







考虑一个16位整数,它由两个字节组成。内存中存储这两个字节有两种方法:一种是将低序字节存储在起始地址,这称为小端(little-endian)字节序;另一种是将高序字节存储在起始地址,这称为大端(big-endian)字节序。图1展示了这两种格式。
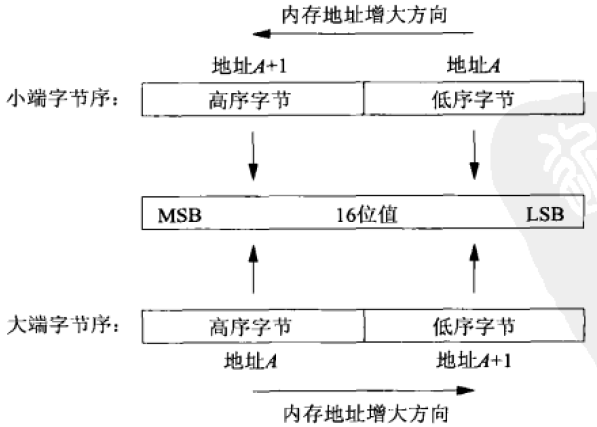
图1 16位整数的小端字节序和大端字节序
在该图中,我们在顶部标明内存地址增长的方向为从右到左,在底部标明内存地址增长的方向为从左到右。我们还标明最高有效位(most significant bit, MSB)是这个16位值最左边一位,最低有效位(leastsignificant bit, LSB)是这个16位值最右边一位。
术语“小端”和“大端”表示多个字节值的哪一端(小端或大端)存储在该值的起始地址。
遗憾的是,这两种字节序之间没有标准可循,两种格式都有系统使用。我们把某个给定系统所用的字节序称为主机字节序(host byte order)。图2所示程序输出主机字节序。
#include <stdio.h>
int main(void)
{
union {
short s;
char c[sizeof(short)];
} un;
un.s = 0x0102;
if (sizeof(short) == 2) {
if (un.c[0] == 1 && un.c[1] == 2) {
printf("big-endian\n");
} else if (un.c[0] == 2 && un.c[1] == 1) {
printf("little-endian\n");
} else {
printf("unknown\n");
}
} else {
printf("sizeof(short) = %d\n", sizeof(short));
}
return 0;
}图2确定主机字节序的程序
我们在短整数变量中存放两字节的值0x0102,然后查看它的两个连续字节c[0](对应图1中的地址A)和c[1](对应图1中的地址A+1),以此确定字节序。
我们已讨论了16位整数的字节序,显然,同样的讨论也适用于32位整数。
既然网络协议必须指定一个网络字节序(network byte order),作为网络编程人员的我们必须清楚不同字节序之间的差异。举例来说,在每个TCP报文段中都有16位的端口号和32位的IPv4地址。发送协议栈和接收协议栈必须就这些多字节字段各个字节的传送顺序达成一致。网际协议使用大端字节序来传送这些多字节整数。
从理论上说,具体实现可以按主机字节序存储套接字地址结构中的各个字段,等到需要在这些字段和协议首部相应字段之间转移时,再在主机字节序和网络字节序之间进行互换,让我们免于操心转换细节。然后由于历史的原因和POSIX规范的规定,套接字地址结构中的某些字段必须按照网络字节序进行维护。因此我们要关注如何在主机字节序和网络字节序之间相互转换。这两种字节序之间的转换使用以下4个函数:
#include<netinet/in.h>
uint16_thtons(uint16_t host16bitvalue);
uint32_thtonl(uint32_t host32bitvalue);
均返回:网络字节序的值
uint16_tntohs(uint16_t net16bitvalue);
uint32_tntohl(uint32_t net32bitvalue);
均返回:主机字节序的值
在这些函数的名字中,h代表host,n代表network,s代表short,l代表long。
当使用这些函数时,我们并不关心主机字节序和网络字节序的真实值(或为大端,或为小端)。我们所要做的只是调用适当的函数在主机和网络字节序之间转换某个给定值。在那些与网际协议所用字节序(大端)相同的系统中,这四个函数通常被定义为空宏。















 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









