









选择排序算法, 和上篇讲的冒泡算法很类似.很容易混淆理解.所以这篇紧接着就讲选择排序算法.上篇讲过,
之所以叫冒泡排序, 是因为从第一个数开始和自己相邻的元素做两两比较,哪个最大就后置,然后这样第二个元素就比第一个元素大,用同样的方法就保证了第三个元素又比第二个元素要大.不断重复这个过程, 最后一个元素肯定是最大的.这样,整个排序是两两比较,找出最大的,从大到小找出所有元素去排列,就就像泡泡一样一个一个的冒出来.这就是冒泡排序.
而选择排序,和上面有一点类似,都是选出最值,但不是选出最大那个元素,而是选出最小的那个元素,并且方法并不是两两比较,而是从首位的元素开始和整个队列中的元素去逐个比较,选出最小的那个元素放在首位;接着又从第二个元素开始,和后面的元素又去逐个比较,找出第二小的元素放在第二位... 重复这个过程,最后的结果是,整个排序队列是从小到大的.这就是和冒泡排序的几个区别了. 每次都选择待排序队列中最小的那个元素放在待排序队列的首位,这就是选择排序的原理.
二维遍历, 自然复杂度就是O(n^2).
掌握了这个思想,我们就能去实现它.很简单吧 当做练习吧~ 下面用C++实现一次:
#include <iostream>
using namespace std;
void print(int* datas, int length){
for (int i = 0; i< length; i++) {
cout << datas[i] << " ";
}
cout << endl;
}
/**
* C++实现选择排序
**/
void selectSort()
{
int values[] = {4,8,7,11,2,25,27,18,1};
int index; //记录最小数的位置
int ele; //记录每次遍历找出的最小值
int length = 9;
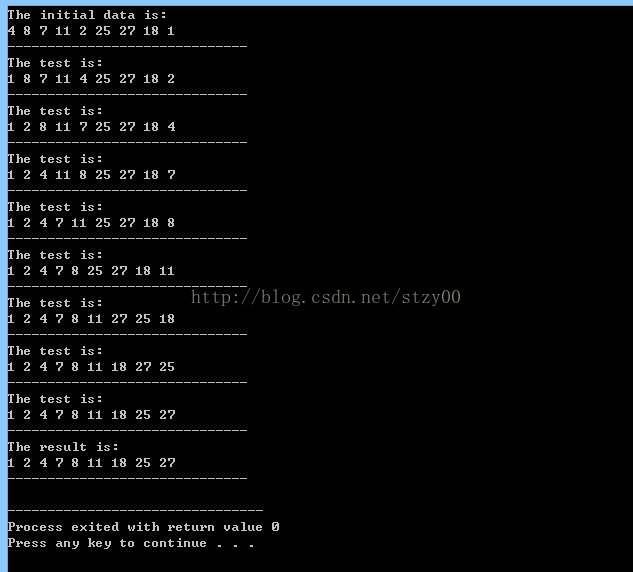
cout << "The initial data is: " << endl;
print(values, length);
cout << "------------------------------" << endl;
for(int i=0;i<length-1;i++)
{
for(int k=i+1;k<length;k++)
{
if(values[k] < values[i])
{ //每次遍历找出最小值
index = k;
//将第 i 次遍历到的最小元素放在第 i 个位置
ele = values[index];
values[index] = values[i];
values[i] = ele;
}
}
cout << "The test is: " << endl;
print(values, length);
cout << "------------------------------" << endl;
}
cout << "The result is: " << endl;
print(values, length);
cout << "------------------------------" << endl;
}
int main()
{
selectSort();
}















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









