






PUT /blog_info
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"blog_id": { "type": "long" },
"blog_name": { "type": "text" },
"blog_url": { "type": "keyword" },
"blog_points": { "type": "double" },
"blog_describe": { "type": "text" },
"blog_time": { "type": "text", "fields": { "date": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" } } }
}
}
}blog_time 字段被定义为 text 类型,并且包含一个子字段 date,该子字段是日期类型,支持多种日期格式。
POST /_bulk
{ "index": { "_index": "blog_info", "_id": "1" }}
{ "blog_id": 1, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 150.68, "blog_describe": "您好,欢迎访问 pan_junbiao的博客", "blog_time": "2023-10-01 10:00:00" }
{ "index": { "_index": "blog_info", "_id": "2" }}
{ "blog_id": 2, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 276.34, "blog_describe": "您好,欢迎访问 pan_junbiao的CSDN博客", "blog_time": "2023-10-02 11:00:00" }
{ "index": { "_index": "blog_info", "_id": "3" }}
{ "blog_id": 3, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 316.58, "blog_describe": "您好,欢迎访问 pan_junbiao的CSDN博客", "blog_time": "2023-10-03 12:00:00" }
{ "index": { "_index": "blog_info", "_id": "4" }}
{ "blog_id": 4, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 198.76, "blog_describe": "您好,欢迎访问 pan_junbiao的博客", "blog_time": "2023-10-04 13:00:00" }
{ "index": { "_index": "blog_info", "_id": "5" }}
{ "blog_id": 5, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 250.12, "blog_describe": "您好,欢迎访问 pan_junbiao的CSDN博客", "blog_time": "2023-10-05 14:00:00" }
{ "index": { "_index": "blog_info", "_id": "6" }}
{ "blog_id": 6, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 300.45, "blog_describe": "您好,欢迎访问 pan_junbiao的CSDN博客", "blog_time": "2023-10-06 15:00:00" }
{ "index": { "_index": "blog_info", "_id": "7" }}
{ "blog_id": 7, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 210.34, "blog_describe": "您好,欢迎访问 pan_junbiao的博客", "blog_time": "2023-10-07 16:00:00" }
{ "index": { "_index": "blog_info", "_id": "8" }}
{ "blog_id": 8, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 235.67, "blog_describe": "您好,欢迎访问 pan_junbiao的CSDN博客", "blog_time": "2023-10-08 17:00:00" }
{ "index": { "_index": "blog_info", "_id": "9" }}
{ "blog_id": 9, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 267.89, "blog_describe": "您好,欢迎访问 pan_junbiao的博客", "blog_time": "2023-10-09 18:00:00" }
{ "index": { "_index": "blog_info", "_id": "10" }}
{ "blog_id": 10, "blog_name": "pan_junbiao的博客", "blog_url": "https://blog.csdn.net/pan_junbiao", "blog_points": 289.56, "blog_describe": "您好,欢迎访问 pan_junbiao的CSDN博客", "blog_time": "2023-10-10 19:00:00" }如果这样查询查不到数据
GET /blog_info/_search
{
"query": {
"range": {
"blog_time": {
"gte": "2023-10-01",
"lte": "2023-10-05"
}
}
}
}使用 子字段 date就可以查到数据
GET /blog_info/_search
{
"query": {
"range": {
"blog_time.date": {
"gte": "2023-10-01",
"lte": "2023-10-05"
}
}
}
}
GET /blog_info/_search
{
"sort": [
{ "blog_time": { "order": "desc" } }
]
}使用blog_time排序报错
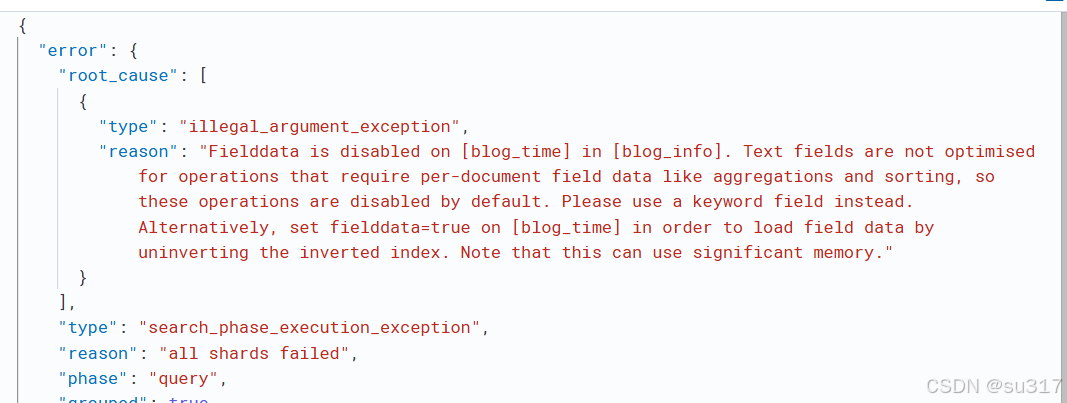
这个错误信息表明你在尝试对一个 text 类型的字段(在这个例子中是 blog_time)进行某些操作(如聚合或排序),而这些操作默认情况下在 text 字段上是被禁用的。这是因为 text 字段主要用于全文搜索,不适合直接用于需要逐文档字段数据的操作。
具体解释
Fielddata is disabled on [blog_time] in [blog_info]:
这意味着你试图对 blog_time 字段执行某些需要使用 Fielddata 的操作(如聚合或排序),但该字段的 Fielddata 已被禁用。
Text fields are not optimised for operations that require per-document field data like aggregations and sorting:
text 字段主要用于全文搜索,而不是用于聚合或排序等需要逐文档字段数据的操作。因此,默认情况下,这些操作在 text 字段上是禁用的。
Please use a keyword field instead:
建议使用 keyword 类型的字段来执行聚合和排序等操作。keyword 字段更适合这些类型的查询。
Alternatively, set fielddata=true on [blog_time] in order to load field data by uninverting the inverted index:
作为替代方案,你可以通过设置 fielddata=true 来启用 text 字段的 Fielddata。但这会显著增加内存使用,并且不推荐,因为这会影响性能。
Note that this can use significant memory:
启用 Fielddata 会占用大量内存,可能会影响集群的整体性能。
使用子字段date排序正常
GET /blog_info/_search
{
"sort": [
{ "blog_time.date": { "order": "desc" } }
]
}现在假设已经创建了索引,而且也有数据了,但是没有设置子字段date如何解决排序问题?
方法1
新增一个字段,然后把旧的数据转换到新的日期类型,然后排序就没问题
PUT /blog_info/_mapping
{
"properties": {
"blog_time2": {
"type": "date",
"format": "yyyy-MM-dd'T'HH:mm||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
POST /blog_info/_update_by_query
{
"script": {
"source": """
if (ctx._source.blog_time != null) {
try {
// 定义输入日期格式
DateTimeFormatter inputFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 解析输入日期字符串
LocalDateTime dateTime = LocalDateTime.parse(ctx._source.blog_time, inputFormatter);
// 定义输出日期格式(不带'T')
DateTimeFormatter outputFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 将日期格式化为所需格式并赋值给新字段
ctx._source.blog_time2 = dateTime.format(outputFormatter);
} catch (Exception e) {
// 如果解析失败,跳过该文档
ctx.op = 'noop';
}
}
""",
"lang": "painless"
},
"query": {
"match_all": {}
}
}GET /blog_info/_search
{
"query": {
"range": {
"blog_points": {
"gt": 290
}
}
},
"sort": [
{ "blog_time2": { "order": "desc" } }
]
}GET /blog_info/_search查询出来的结果用字符串显示的日期类型,不影响排序
"blog_time2": "2023-10-01 10:00:00",
插入数据也是写字符串方式新增一个新的11的文档
PUT /blog_info/_doc/11
{
"blog_name": "sus",
"blog_url": "https://blog/xxx",
"blog_time": "2024-10-29 11:00:00",
"blog_time2":"2024-10-29 11:00:00"
}接下来创建新的文档blog_time更新为日期类型
PUT /blog_infonew
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"blog_id": { "type": "long" },
"blog_name": { "type": "text" },
"blog_url": { "type": "keyword" },
"blog_points": { "type": "double" },
"blog_describe": { "type": "text" },
"blog_time": { "type": "date",
"format": "yyyy-MM-dd'T'HH:mm||yyyy-MM-dd HH:mm:ss||yyyy-MM-dd" }
}
}
}迁移数据到新的索引,等于把blog_time2改为blog_time名称了,因为索引无法删除某个字段
POST /_reindex
{
"source": {
"index": "blog_info"
},
"dest": {
"index": "blog_infonew"
},
"script": {
"source": """
// 如果 blog_time2 存在,则将其值赋给 blog_time
if (ctx._source.containsKey('blog_time2')) {
ctx._source.blog_time = ctx._source.remove('blog_time2');
} else {
// 如果 blog_time2 不存在且 publish_date 存在,则删除 blog_time
if (ctx._source.containsKey('publish_date')) {
ctx._source.remove('blog_time');
}
}
""",
"lang": "painless"
}
}删除 DELETE /blog_info 旧的索引。
然后可以把blog_infonew再创建为原来的blog_info索引。或者使用别名这样代码也是可以通过别名进行相应的查询、新增的操作。
POST /_aliases
{
"actions": [
{ "add": { "index": "blog_infonew", "alias": "blog_info" } }
]
}根据条件更新
POST /_reindex
{
"source": {
"index": "old_index",
"query": {
"range": {
"updated_at": {
"gte": "2025-02-15T22:38:00Z"
}
}
}
},
"dest": {
"index": "new_index"
}
}增量更新
POST /new_index/_update_by_query
{
"script": {
"source": """
ctx._source.title = params.title;
ctx._source.content = params.content;
ctx._source.updated_at = params.updated_at;
""",
"lang": "painless",
"params": {
"title": "First Post Updated",
"content": "This is the updated first post.",
"updated_at": "2025-02-16T10:00:00Z"
}
},
"query": {
"term": {
"_id": "1"
}
}
}这个脚本会遍历 new_index 中 _id 为 1 的文档,并根据传入的参数更新 title, content 和 updated_at 字段
对于批量更新多个文档的不同内容,可以使用 _bulk API 或者在 _update_by_query 中使用脚本逻辑来处理。
我们可以使用 _bulk API 来批量更新多个文档的内容。
使用 _bulk API 批量更新文档
根据从 old_index 中获取的增量数据,准备批量更新请求。
json
深色版本
POST /new_index/_bulk
{ "update": { "_id": "1" } }
{ "doc": { "title": "First Post Updated", "content": "This is the updated first post.", "updated_at": "2025-02-16T10:00:00Z" } }
{ "update": { "_id": "2" } }
{ "doc": { "title": "Second Post Updated", "content": "This is the updated second post.", "updated_at": "2025-02-16T11:00:00Z" } }使用 _update_by_query API 批量更新多个文档
如果我们希望通过 _update_by_query API 批量更新多个文档的不同内容,可以使用 Painless 脚本结合条件判断。
假设我们需要更新多个文档,并且每个文档有不同的更新内容。
json
深色版本
POST /new_index/_update_by_query
{
"script": {
"source": """
if (ctx._id == '1') {
ctx._source.title = params.docs[0].title;
ctx._source.content = params.docs[0].content;
ctx._source.updated_at = params.docs[0].updated_at;
} else if (ctx._id == '2') {
ctx._source.title = params.docs[1].title;
ctx._source.content = params.docs[1].content;
ctx._source.updated_at = params.docs[1].updated_at;
}
""",
"lang": "painless",
"params": {
"docs": [
{
"title": "First Post Updated",
"content": "This is the updated first post.",
"updated_at": "2025-02-16T10:00:00Z"
},
{
"title": "Second Post Updated",
"content": "This is the updated second post.",
"updated_at": "2025-02-16T11:00:00Z"
}
]
}
},
"query": {
"ids": {
"values": ["1", "2"]
}
}
}在这个脚本中:
- 我们通过
ctx._id判断当前处理的文档 ID。 - 根据不同的文档 ID,更新相应的字段值。
POST /new_index/_update/1
{
"script": {
"source": """
ctx._source.title = params.title;
ctx._source.content = params.content;
ctx._source.updated_at = new Date().format('yyyy-MM-dd\'T\'HH:mm:ssZ');
""",
"lang": "painless",
"params": {
"title": "Updated Title",
"content": "Updated Content"
}
}
}上面举例是每次更新doc就更新updated_at ,然后手动查询全量同步之后新增的数据,手动增量更新。
这里有个问题是执行全量更新的时候,程序是一直往老的索引写数据的,全量更新对于数据量很大是不是要持续很长时间,那么这段时间产生的数据会不会被写入新的索引?还是部分写入?这样下次增量就不好判断了。
你提到的问题确实是一个常见的挑战,尤其是在处理大数据量的全量同步时。为了确保在全量同步期间产生的新数据不会丢失,并且可以正确地进行后续的增量同步,我们需要采取一些策略来管理数据的一致性和完整性。
解决方案概述
- 双写机制:在全量同步期间,确保所有新的更新同时写入旧索引和新索引。
- 版本控制:使用版本控制或时间戳字段(如
updated_at)来追踪数据的变化。 - 分阶段同步:将全量同步分为多个小批量处理,减少单次操作的时间窗口。
具体步骤
1. 双写机制
在全量同步期间,所有的写操作(包括插入、更新和删除)需要同时写入旧索引和新索引。这可以通过以下几种方式实现:
- 应用程序层面:在应用程序中实现逻辑,确保所有写操作同时写入两个索引。
- 中间件或代理:使用中间件或代理来拦截写请求,并将其分发到两个索引。
应用程序层面示例
假设你有一个应用程序负责处理写操作,可以在每次写操作时同时更新两个索引。
python
深色版本
import requests
# Elasticsearch 配置
es_url = "http://localhost:9200"
def write_to_both_indices(doc_id, doc):
# 写入旧索引
old_index_response = requests.post(f"{es_url}/old_index/_doc/{doc_id}", json=doc)
# 写入新索引
new_index_response = requests.post(f"{es_url}/new_index/_doc/{doc_id}", json=doc)
return old_index_response, new_index_response这种方法确保了所有新的数据变更都会被写入两个索引。
2. 版本控制
使用版本控制或时间戳字段(如 updated_at)来追踪数据的变化。这样可以在全量同步完成后,基于这些字段进行增量同步。
时间戳字段示例
假设每个文档都有一个 updated_at 字段记录最后一次更新的时间。
json
深色版本
{
"_id": "1",
"title": "Sample Title",
"content": "Sample Content",
"updated_at": "2025-02-16T10:00:00Z"
}在全量同步期间,所有的更新都会更新 updated_at 字段,这样在全量同步完成后,可以根据 updated_at 字段进行增量同步。
3. 分阶段同步
将全量同步分为多个小批量处理,减少单次操作的时间窗口。这样可以降低全量同步所需的时间,并减少在此期间产生的新数据的影响。
分批次同步示例
假设你需要同步大量数据,可以将其分成多个批次进行同步。
python
深色版本
import requests
# Elasticsearch 配置
es_url = "http://localhost:9200"
def reindex_in_batches(batch_size=1000):
scroll_id = None
while True:
if not scroll_id:
# 初始查询
response = requests.post(f"{es_url}/_search/scroll", json={
"size": batch_size,
"query": {
"match_all": {}
}
})
else:
# 续续滚动查询
response = requests.post(f"{es_url}/_search/scroll", json={
"scroll": "1m",
"scroll_id": scroll_id
})
hits = response.json().get('hits', {}).get('hits', [])
if not hits:
break
# 处理每个批次的数据
for hit in hits:
doc_id = hit["_id"]
doc = hit["_source"]
# 写入新索引
new_index_response = requests.post(f"{es_url}/new_index/_doc/{doc_id}", json=doc)
scroll_id = response.json().get('_scroll_id')
print("Reindex completed successfully.")
reindex_in_batches(batch_size=1000)这种方法通过分批次处理数据,减少了全量同步所需的时间,并降低了在此期间产生新数据的风险。
结合双写机制和增量同步
为了确保全量同步期间产生的新数据能够正确同步到新索引,并且不影响后续的增量同步,可以结合双写机制和增量同步。
步骤
- 启用双写机制:在全量同步期间,确保所有写操作同时写入旧索引和新索引。
- 执行全量同步:将旧索引中的数据逐步迁移到新索引。
- 基于时间戳进行增量同步:在全量同步完成后,根据
updated_at字段进行增量同步,确保没有遗漏任何数据。
示例流程
- 启用双写机制:在应用程序中实现逻辑,确保所有写操作同时写入两个索引。
python
深色版本
import requests
# Elasticsearch 配置
es_url = "http://localhost:9200"
def write_to_both_indices(doc_id, doc):
# 写入旧索引
old_index_response = requests.post(f"{es_url}/old_index/_doc/{doc_id}", json=doc)
# 写入新索引
new_index_response = requests.post(f"{es_url}/new_index/_doc/{doc_id}", json=doc)
return old_index_response, new_index_response- 执行全量同步:将旧索引中的数据逐步迁移到新索引。
python
深色版本
import requests
# Elasticsearch 配置
es_url = "http://localhost:9200"
def reindex_in_batches(batch_size=1000):
scroll_id = None
while True:
if not scroll_id:
# 初始查询
response = requests.post(f"{es_url}/_search/scroll", json={
"size": batch_size,
"query": {
"match_all": {}
}
})
else:
# 续续滚动查询
response = requests.post(f"{es_url}/_search/scroll", json={
"scroll": "1m",
"scroll_id": scroll_id
})
hits = response.json().get('hits', {}).get('hits', [])
if not hits:
/XMLSchemaValidationError: Invalid schema provided.看起来我在示例代码中出现了一个错误。让我重新整理并提供更清晰的示例代码和步骤。
使用 _reindex API 不会清除目标索引(在你的例子中是 blog_info1),而是以追加的方式将符合条件的文档从源索引(blog_info)复制到目标索引(blog_info1)。这意味着:
现有文档不会被删除:如果目标索引(blog_info1)中已经存在文档,它们不会被删除。
符合条件的新文档会被添加:只有符合查询条件的文档会被从源索引复制到目标索引。
关键点
追加模式:默认情况下,_reindex 是追加模式,它不会删除目标索引中的现有数据。
冲突处理:如果你的目标索引中已经存在具有相同 _id 的文档,Elasticsearch 会根据配置来决定如何处理这些冲突。默认情况下,新文档会覆盖旧文档。
POST /_reindex
{
"source": {
"index": "blog_info",
"query": {
"range": {
"blog_points": {
"gt": 200
}
}
}
},
"dest": {
"index": "blog_info1",
"op_type": "create" // 只创建不存在的文档,忽略已有文档 默认是index
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









