







 本文详细介绍了Flink的三种部署模式:Local模式适合本地测试,Standalone模式适用于小规模集群,但缺乏系统级任务管理,而FlinkOnYarn模式利用YARN的资源管理,适合生产环境。在生产环境中,通常采用FlinkOnYarn并配置高可用,利用ZooKeeper实现。此外,文章还讨论了各种模式的适用场景和配置注意事项。
本文详细介绍了Flink的三种部署模式:Local模式适合本地测试,Standalone模式适用于小规模集群,但缺乏系统级任务管理,而FlinkOnYarn模式利用YARN的资源管理,适合生产环境。在生产环境中,通常采用FlinkOnYarn并配置高可用,利用ZooKeeper实现。此外,文章还讨论了各种模式的适用场景和配置注意事项。
我们在这一课时将讲解 Flink 常见的部署模式:本地模式、Standalone 模式和 Flink On Yarn 模式,然后分别讲解三种模式的使用场景和部署中常见的问题,最后将讲解在生产环境中 Flink 集群的高可用配置。
Flink 常见的部署模式
环境准备
在绝大多数情况下,我们的 Flink 都是运行在 Unix 环境中的,推荐在 Mac OS 或者 Linux 环境下运行 Flink。如果是集群模式,那么可以在自己电脑上安装虚拟机,保证有一个 master 节点和两个 slave 节点。
同时,要注意在所有的机器上都应该安装 JDK 和 SSH。JDK 是我们运行 JVM 语言程序必须的,而 SSH 是为了在服务器之间进行跳转和执行命令所必须的。关于服务器之间通过 SSH 配置公钥登录,你可以直接搜索安装和配置方法,我们不做过度展开。
Flink 的安装包可以在这里下载。需要注意的是,如果你要和 Hadoop 进行集成,那么我们需要使用到对应的 Hadoop 依赖,下面将会详细讲解。
Local 模式
Local 模式是 Flink 提供的最简单部署模式,一般用来本地测试和演示使用。
我们在这里下载 Apache Flink 1.10.0 for Scala 2.11 版本进行演示,该版本对应 Scala 2.11 版本。
将压缩包下载到本地,并且直接进行解压,使用 Flink 默认的端口配置,直接运行脚本启动:
➜ [SoftWare]# tar -zxvf flink-1.10.0-bin-scala_2.11.tgz
上图则为解压完成后的目录情况。
然后,我们可以直接运行脚本启动 Flink :
➜ [flink-1.10.0]# ./bin/start-cluster.sh

上图显示我们的 Flink 启动成功。
我们直接访问本地的 8081 端口,可以看到 Flink 的后台管理界面,验证 Flink 是否成功启动。
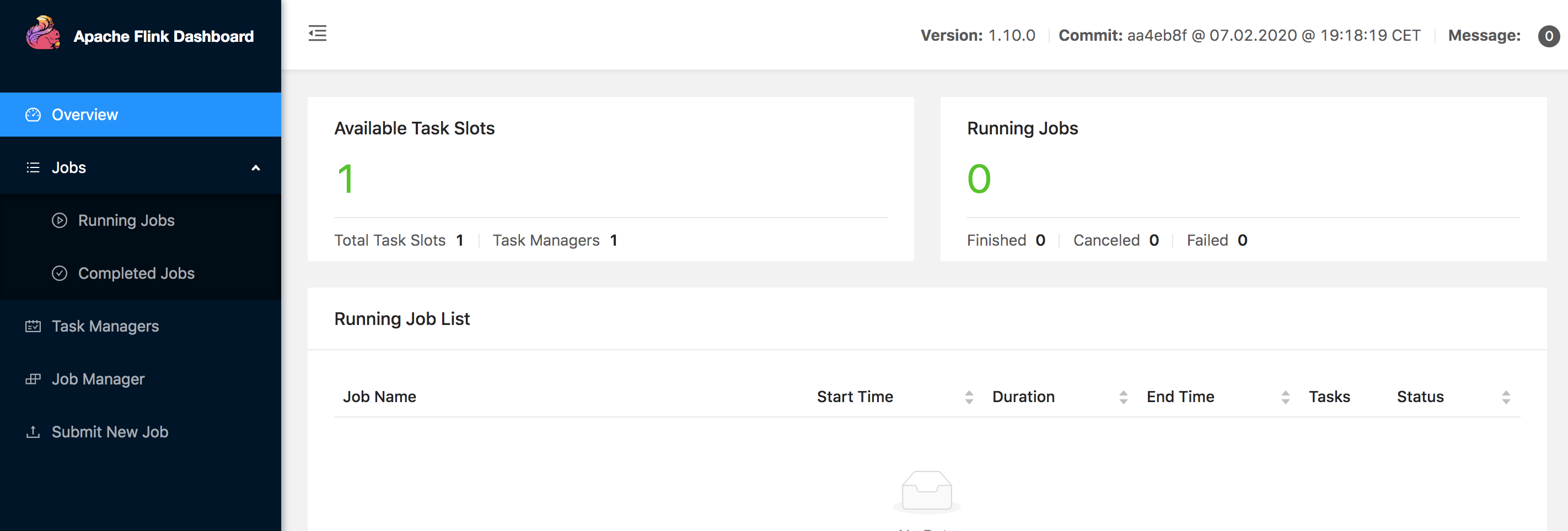
可以看到 Flink 已经成功启动。当然,我们也可以查看运行日志来确认 Flink 是不是成功启动了,在 log 目录下有程序的启动日志:

我们尝试提交一个测试任务:
./bin/flink run examples/batch/WordCount.jar
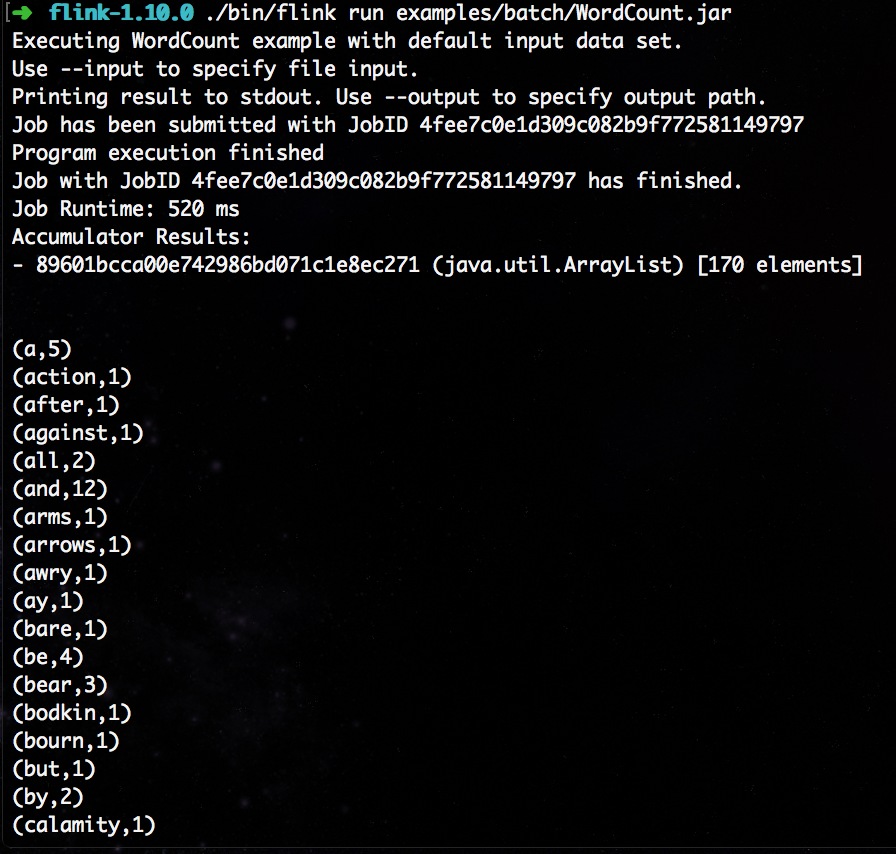
我们在控制台直接看到输出。同样,在 Flink 的后台管理界面 Completed Jobs 一栏可以看到刚才提交执行的程序:
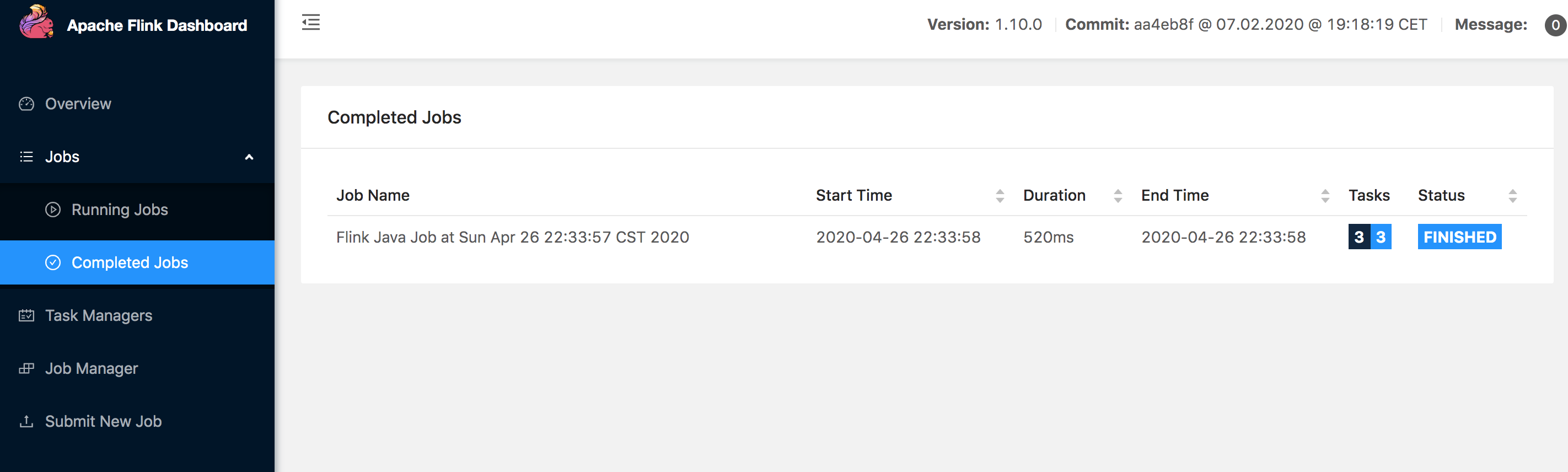
Standalone 模式
Standalone 模式是集群模式的一种,但是这种模式一般并不运行在生产环境中,原因和 on yarn 模式相比:
-
Standalone 模式的部署相对简单,可以支持小规模,少量的任务运行;
-
Stabdalone 模式缺少系统层面对集群中 Job 的管理,容易遭成资源分配不均匀;
-
资源隔离相对简单,任务之间资源竞争严重。
我们在 3 台虚拟机之间搭建 standalone 集群:

在 master 节点,将 Apache Flink 1.10.0 for Scala 2.11 包进行解压:
➜ [SoftWare]# tar -zxvf flink-1.10.0-bin-scala_2.11.tgz
重点来啦,我们需要修改 Flink 的配置文件,并且将修改好的解压目录完整的拷贝到两个从节点中去。在这里,我强烈建议主节点和从节点的目录要保持一致。
我们修改 conf 目录下的 flink-conf.yaml:
flink-conf.yaml 文件中有大量的配置参数,我们挑选其中必填的最基本参数进行修改:
jobmanager.rpc.address: master
jobmanager.heap.size: 1024m
jobmanager.rpc.port: 6123
taskmanager.memory.process.size: 1568m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
jobmanager.execution.failover-strategy: region
io.tmp.dirs: /tmp
它们分别代表:
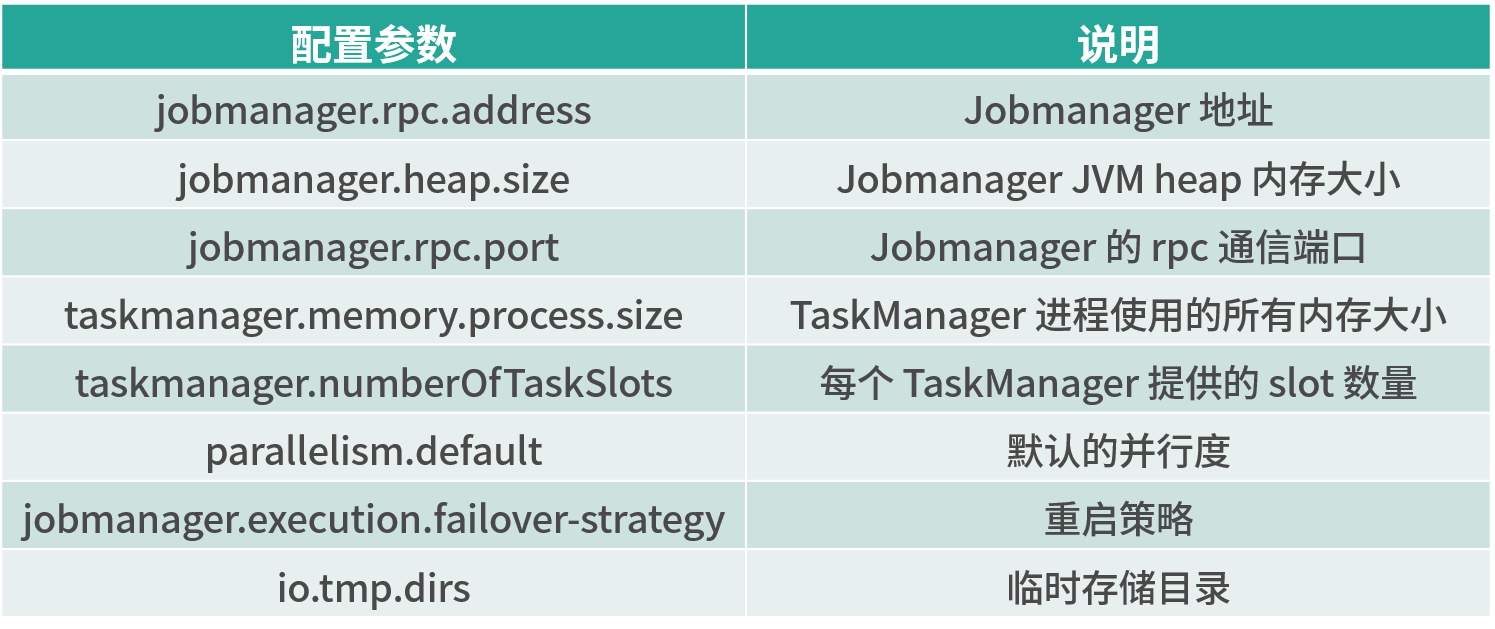
如果你对其他的参数有兴趣的话,可以直接参考官网。
接下来我们修改 conf 目录下的 master 和 slave 文件。
vim master,将内容修改为:
master
vim slave,将内容修改为:
slave01
slave02
然后,将整个修改好的 Flink 解压目录使用 scp 远程拷贝命令发送到从节点:
scp -r /SoftWare/flink-1.10.0 slave01:/SoftWare/
scp -r /SoftWare/flink-1.10.0 slave02:/SoftWare/
在 master、slave01、slave02 上分别配置环境变量,vim /etc/profile,将内容修改为:
export FLINK_HOME=/SoftWare/flink-1.10.0
export PATH=$PATH:$FLINK_HOME/bin
到此为止,我们整个的基础配置已经完成,下面需要启动集群,登录 master 节点执行:
/SoftWare/flink-1.10.0/bin/start-cluster.sh
可以在浏览器访问:http://192.168.2.100:8081/ 检查集群是否启动成功。
集群搭建过程中,可能出现的问题:
-
端口被占用,我们需要手动杀掉占用端口的程序;
-
目录找不到或者文件找不到,我们在 flink-conf.yaml 中配置过 io.tmp.dirs ,这个目录需要手动创建。
On Yarn 模式和 HA 配置
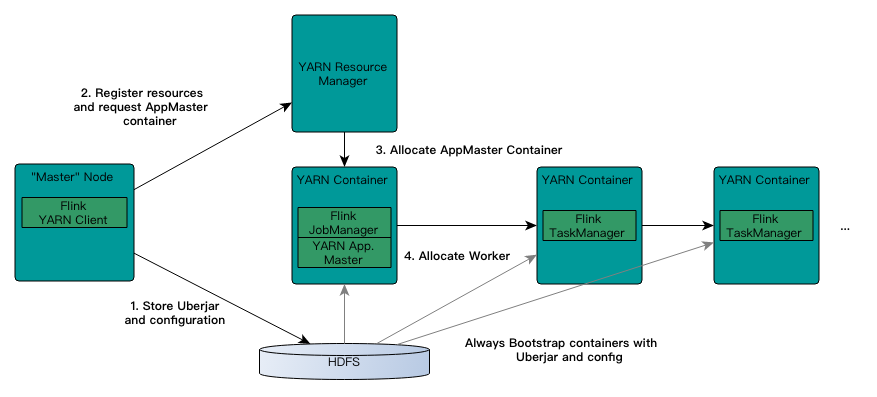
上图是 Flink on Yarn 模式下,Flink 和 Yarn 的交互流程。Yarn 是 Hadoop 三驾马车之一,主要用来做资源管理。我们在 Flink on Yarn 模式中也是借助 Yarn 的资源管理优势,需要在三个节点中配置 YARN_CONF_DIR、HADOOP_CONF_DIR、HADOOP_CONF_PATH 中的任意一个环境变量即可。
本课时中集群的高可用 HA 配置是基于独立的 ZooKeeper 集群。当然,Flink 本身提供了内置 ZooKeeper 插件,可以直接修改 conf/zoo.cfg,并且使用 /bin/start-zookeeper-quorum.sh 直接启动。
环境准备:
-
ZooKeeper-3.x
-
Flink-1.10.0
-
Hadoop-2.6.5
我们使用 5 台虚拟机搭建 on yarn 的高可用集群:

如果你在使用 Flink 的最新版本 1.10.0 时,那么需要在本地安装 Hadoop 环境并进行下面的操作。
首先,添加环境变量:
vi /etc/profile
# 添加环境变量
export HADOOP_CONF_DIR=/Software/hadoop-2.6.5/etc/hadoop
# 环境变量生效
source /etc/profile
其次,下载对应的的依赖包,并将对应的 Hadoop 依赖复制到 flink 的 lib 目录下,对应的 hadoop 依赖可以在这里下载。
与 standalone 集群不同的是,我们需要修改 flink-conf.yaml 文件中的一些配置:
high-availability: zookeeper
high-availability.storageDir: hdfs://cluster/flinkha/
high-availability.zookeeper.quorum: slave01:2181,slave02:2181,slave03:2181
它们分别代表:
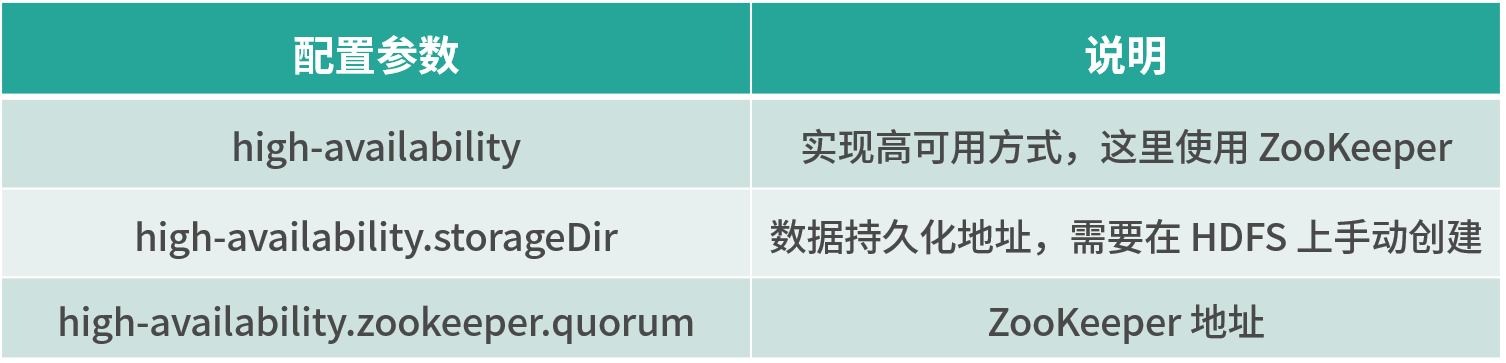
然后分别修改 master、slave、zoo.cfg 三个配置文件。
vim master,将内容修改为:
master01:8081
master02:8081
vim slave,将内容修改为:
slave01
slave02
slave03
vim zoo.cfg,将内容修改为:
server.1=slave01:2888:3888
server.2=slave02:2888:3888
server.3=slave03:2888:3888
然后,我们将整个修改好的 Flink 解压目录使用 scp 远程拷贝命令发送到从节点:
scp -r /SoftWare/flink-1.10.0 slave01:/SoftWare/
scp -r /SoftWare/flink-1.10.0 slave02:/SoftWare/
scp -r /SoftWare/flink-1.10.0 slave03:/SoftWare/
分别启动 Hadoop 和 ZooKeeper,然后在主节点,使用命令启动集群:
/SoftWare/flink-1.10.0/bin/start-cluster.sh
我们同样直接访问 http://192.168.2.100:8081/ 端口,可以看到 Flink 的后台管理界面,验证 Flink 是否成功启动。
在 Flink on yarn 模式下,启动集群的方式有两种:
-
直接在 yarn 上运行任务
-
yarn session 模式
直接在 yarn 上运行任务相当于将 job 直接提交到 yarn 上,每个任务会根据用户的指定进行资源申请,任务之间互不影响。
./bin/flink run -yjm 1024m -ytm 4096m -ys 2 ./examples/batch/WordCount.jar
更多关于参数的含义,可以参考官网。
使用 yarn session 模式,我们需要先启动一个 yarn-session 会话,相当于启动了一个 yarn 任务,这个任务所占用的资源不会变化,并且一直运行。我们在使用 flink run 向这个 session 任务提交作业时,如果 session 的资源不足,那么任务会等待,直到其他资源释放。当这个 yarn-session 被杀死时,所有任务都会停止。
例如我们启动一个 yarn session 任务,该任务拥有 8G 内存、32 个槽位。
./bin/yarn-session.sh -tm 8192 -s 32
我们在 yarn 的界面上可以看到这个任务的 ID,然后向这个 session ID 提交 Flink 任务:
./bin/flink run -m yarn-cluster -yid application_xxxx ./examples/batch/WordCount.jar
其中,application_xxxx 即为上述的 yarn session 任务 ID。
总结
本课时我们讲解了 Flink 的三种部署模式和高可用配置,并且对这三种部署模式的适用场景进行了讲解。在生产上,我们最常用的方式当然是 Flink on Yarn,借助 Yarn 在资源管理上的绝对优势,确保集群和任务的稳定。
精选评论
**蜗牛:
请问下那个:hadoop 依赖下载连接在哪里呀?可否提供下,谢谢~
讲师回复:
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/
**7324:
每天在地铁上,看看文档就学习了,非常方便
**忠:
基于yarn模式,其实不用搭建集群的,就是作为一个客户端使用的
*少:
老师你好,这是来自一个初学者的疑惑。本篇介绍了flink常见的三种部署模式,但是前几篇的例子中并不涉及flink的部署,在项目工程中可以直接run起来。所以,之前的工程例子启动时是做了flink集群的初始化吗,还是可以选择不使用flink集群的方式?实际应用时一定要部署flink集群吗?像前几章工程直接运行和本章提交到flink运行有什么样的区别?希望老师可以给予解答,谢谢。
讲师回复:
我们右键运行时相当于在本地启动了一个单机版本。生产中都是集群环境,并且是高可用的,生产上提交任务需要用到flink run 命令,指定必要的参数。
**鲁:
如果是cdh集群该怎么让他集成呢
讲师回复:
Flink和CDH集成搭建高可用,你需要把flink on yarn中yarn集群的地址指向cdh中的yarn即可。
**彬:
这个有点懵,为啥on yarn模式要需要部署flink集群呢,spark的on yarn模式不要部署spark集群啊。都on yarn了,任务是调度到nm的节点呢,还是调度到flink的节点呢?如果不调度到flink的节点,flink集群的作用是啥呢?
讲师回复:
那是因为Spark会把一个节点上的Spark程序发到其他的节点,所以spark不需要在所有节点部署。
**媛:
老师,您知道pyflink如何用yarn模式启动任务吗
讲师回复:
现在Flink对Python的支持比较完善了。你可以参考官方的博客这里:https://my.oschina.net/u/2828172/blog/4433843
**用户7095:
老师,flink1.10.版本是不是只能装Hadoop2.8.5版本,不能装Hadoop3
讲师回复:
2和3都可以的。
**斯:
老师有个问题请教一下,最近在搞生产Flink集群。生产提交都是Flink on yarn的方式运行,而且选择per-job的方式,就是flink run -m yarn-cluster的方式。但是提交的第一个任务可以正常运行,但是后面提交的任务的Flink UI就都是第一个的。此时取消第一个任务,后面提交的任务也会被kill。请问这是什么情况呢?
讲师回复:
"是的。我猜想你的问题应该是集群资源的问题,per-job模式需要确保集群资源足够。
"
**6709:
…请问,flink.怎样读取hive数据,执行hive查询sql
讲师回复:
Flink最新更新如下:https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/table/hive/ ,参考这个官方文档
**波:
老师,请问下使用yarn来搭建集群,本地环境必须要有Hadoop环境吗?是否可以直接使用已有的Hadoop集群(Hadoop集群和flink集群在不同的机器上)
讲师回复:
不行的,不然你指定文件目录的时候找不到配置。
**8852:
有对接华为hadoop的吗?认证怎么破?
讲师回复:
华为有自己云上Flink产品,可以参考他们的文档
**霞:
请问老师,如何进行per job cluster in k8s的安装?
讲师回复:
可以参考:https://zhuanlan.zhihu.com/p/74470130
**用户9193:
“我们在使用 flink run 向这个 session 任务提交作业时,如果 session 的资源不足,那么任务会等待,直到其他资源释放。当这个 yarn-session 被杀死时,所有任务都会停止。”这个我测试不是这样的。yarn session会动态申请资源给flink job,命令行中指定的-n参数并未生效。我用的是1.7.2版本。还望老师帮忙解答下是不是这样。
讲师回复:
我理解的是,yarn-session没有了,任务就没有了。因为资源在yarn-session中。
**保:
打卡
**强:
老师,挺强的
*熙:
有个问题,flink on yarn模式,需要修改flink配置文件,打开高可用配置,但是,on yarn 模式,当某个applicationmaster挂了之后,yarn只会重启该AM,来达到高可用效果,并不像standalone模式高可用,会切换jobmanager,所以、我觉得on yarn模式的高可用,不需要打开flink的高可用配置,也不依赖zookeeper,而是yarn自身的重试机制来实现的吧?不知道这样理解对不对?望指导,感谢~~~
讲师回复:
Yarn的AM在Flink的高可用下是对JobManager的封装,跟Spark不同
**阳:
讲得很好,感谢
**毅:
还是要实现落地才最深刻
**3430:
yarn session生产上用得多吗
讲师回复:
不多
**伯:
咨询一下大神,flink on yarn模式的话,还需要安装flink集群?我之前理解的flink只是一个客户端 用flink命令然后往yarn上提交flink程序
讲师回复:
需要的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











