






#注意:笔者在2021/11/11当天调试过这个代码是可用的,由于pdfminer版本的更新,网络上大多数的语法没有更新,我也是找了好久的文章才修正了我的代码,仅供学习参考。
1、把pdf文件移动到本代码文件的同一个目录下,笔者是在pycharm里面运行的项目,下图中的x1文件夹存储了我需要转换成文本文件的所有pdf文件。然后要在此目录下创建一个存放转换后的txt文件的文件夹,如图中的txt文件夹。
2、编写代码
(1)导入所需库
# coding:utf-8
import os
import re
from pdfminer.converter import LTChar, TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTTextBox
from io import StringIO
from io import open(2)定义一个读取pdf文件内容的函数
#读取pdf文件文本内容
def read(path):
parser = PDFParser(path)
doc = PDFDocument(parser, '')
parser.set_document(doc)
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建PDf 资源管理器 来管理共享资源
rsrcmgr = PDFResourceManager()
# 创建一个PDF聚合器,包含资源管理器与参数分析器
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 创建一个PDF解释器对象
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 循环遍历列表,每次处理一个page的内容
page0 = ''
for i, page in enumerate(PDFPage.create_pages(doc)):
interpreter.process_page(page)
print("START PAGE %d\n" % i)
if page is not None:
interpreter.process_page(page)
print("END PAGE %d\n" % i)
# 接受该页面的LTPage对象
layout = device.get_result()
print(layout)
# 这里layout是一个LTPage对象,里面存放着这个 page 解析出的各种对象
# 包括 LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等
line0 = ''
for x in layout:
if isinstance(x, LTTextBox):
line0 = line0 + x.get_text().strip()
page0 = page0 + line0
return page0 #返回pdf文件中所有提取到的文本内容(3)主函数
if __name__ == '__main__':
path = 'x1'
pdfList = os.listdir(path)
#批量读取存储
pdf_num = 0
for li in pdfList:
try:
pdffile = open(path + '/' + li, "rb")
content = read(pdffile)
except:
continue
str = re.sub('.pdf', '.txt', li)
file1 = 'txt/' + str
with open(file1, 'w+', encoding='utf8') as f:
f.write(content)
pdf_num = pdf_num + 1
# handleData(str)
print("DONE:" + str )
print('number of done-article:',end = "")
print(pdf_num)
3、运行结果
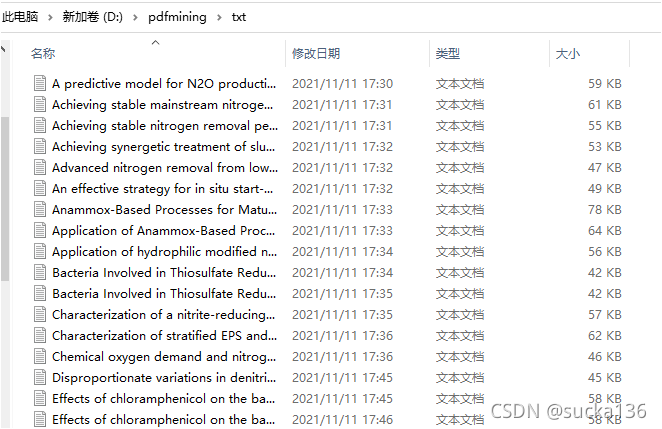

大家可以看到这个提取的只是文本内容,我是只需要用来做文本挖掘用的,如果有需要图片的可以稍微改一下read(path)函数就可以啦!

喜欢的可以关注一下小萌新作者哦,后续会不断更新自己的爬虫项目和深度学习有关的python小知识的!!!!!!

















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









