







关于场景文字检测的定义、应用、意义等科普性质的细节这里就不提了,本文是一篇相对比较专业的文章,如果非此领域的同学请绕行。本文主要探讨场景文字主流的方法,并提供了一些创新思路,以及一个基于文献[1]的场景文字检测系统(在csdn上分享了该代码)。就我所知(半年前全面搜索过),十分完善的场景文字检测的代码网上是没有的,有的只是一些算法,或者比较过时的系统,本文的出现正是希望通过本人的一点努力填补这个空白,方便广大研究者能够更快入门,至少一开始研究就有一个基本框架。
目前主流的方法主要有两类:基于区域(MSER,最大稳定极值区域)和基于像素点(SWT,笔划宽度变换)的方法。在文献[2]中提到:截止2011年,场景文字检测结果最好的是韩国人Chunghoon Kim基于MSER的方法,其查全率(recall)为62.47%,查准率(precision)为82.98%。遗憾的是,他的方法并没有写成论文,其算法也不得而知。
当然,使用SWT是更普遍的情况,[1]即是基于SWT的。SWT方法最有代表性的有两篇文章,都出自微软研究院,一篇是SWT开山之作——Epshtein大神的文献[3],一篇是巅峰之作——华科Cong Yao的文献[4]。Epshtein大神提出SWT算法,使得场景文字检测向前迈出一大步,其算法核心非常简单,大致是(1)将原图做Canny检测,Canny边缘图作为算法的输入图,对每一个Canny点进行一次SWT算法,见图1;(2)SWT算法的一个前提是作者认为每个字符的笔划宽度是大致相同的,所以从一个Canny边缘点顺着梯度方向出发,如果能够找到梯度方向正好相反的点,且该点也是Canny边缘点,则认为该笔划宽度有效;(3)当检测完所有的Canny点时,有效的笔划宽度就构成了输出图,即文字检测图,可见图2。当然,理论上是这样,而实际上会出现很多虚警图,这些虚警通常是由于类文字物体得到的,如条环、窗户、砖块和网格等。我认为该算法是基于像素点的,是因为起始点是Canny边缘点,梯度方向和大小也是基于边缘点,而笔划宽度则是将两个对应的Canny边缘点间的线段连接起来。基于像素点有一个最严重的问题,就是容易受到噪声点或特殊点的影响。比方说图2,本来很好的结果,却由于伪笔划宽度带了一些问题,因此做完SWT变换,必须做一些处理或改进。

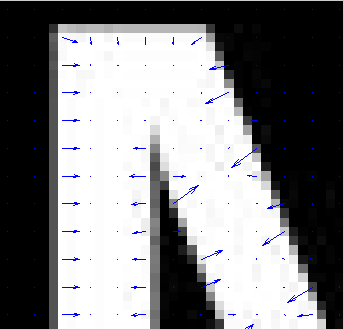
(a)原图的梯度方向 (b)局部放大图
图1 梯度方向图


图2. SWT过程图(具体算法见[3])
Cong Yao的文章曾让我大为震惊,虽然我并未做仿真,也没有按照其思路进行研究,但是并不妨碍我推崇这篇文章。我没有做仿真的原因是,这篇文章的工作量太大,对于只有半年时间写论文的我来说时间不够。通常,看到这类文章就像寻着一个珍宝一样,时不时要拿出来鼓励一下自己,什么是真正的好文章?既有创新,又有工作量。可能是受Marios Anthimopoulos的启发,Cong Yao使用的分类器是RFs(Random Forests, 随机森林) 。在文献[5]中,Marios例举了RFs在文字检测中比Boosting、SVM和NNs好的两个优点。我在网上搜过RFs的代码,只有一个简化版的,本来RFs是一种判决树,输出的是概率,具体阈值可以人为设定,但是简化版的只给出0或1。另外,该论文使用contour shape, edge shape 很新的描述子作为特征向量,说明作者对图像领域最新发展是很熟悉的。作者一共给了十来个特征向量,测试这些特征的工作量可想而知。当然,工作量归工作量,如果结果不行,那工作量也是白瞎,但是作者不负众望,对ICDAR的查全率为0.66,查准率为0.68,对OSTD(倾斜场景文字数据库,由文献[1]作者发布)的查全率为0.73,查准率为0.77。


(a)p, e, c, o出现了伪笔划宽度 (b)E, A, G, S包含伪笔画宽度
图3. SWT由于噪声点引起的伪笔划宽度
2012年,Weilin Huang提出了SWT的变体——SFT[6],在SWT算法中添加了颜色信息。2014年,将由本人提出另一种SWT变体——GSWT,目前还在进一步实验中,但相信不久就能成文,准备发到PR上。
本人曾做过两个有趣的小实验,有图供大家参考批评。
一是研究图像梯度时,发现文字的梯度大小图有一个很明显的特征,就是一个文字的笔划对应的两个边缘的梯度大小是大致相等的。见图4。
二是,由于SWT受噪声点影响较大,所以可以通过滤波,将噪声点过滤掉再使用SWT算法,但是一般低通滤波器会使文字的边缘信息造成模糊,所以保持边缘平滑滤波器是一个完美选择。我在这方面的研究还不深入,但是做个一个很神奇的实验。灵感来自于Gastal写的文献[7],Adaptive Manifolds滤波器是一种新型的而且性能非常优越的保持边缘平滑滤波器。见图5。

图4. 对比原图和梯度大小图。上行为原图;下行为梯度大小图,颜色从蓝至红表示值增大。可以发现,每个字中笔划对应的两个边缘梯度大小是基本相等的。


(a)对原图进行文字检测 (b)对经过AM滤波后的图进行文字检测
图5. 黄色框表示检测到的竖直文字区域,红色表示水平文字区域。可见,原图由于噪声的影响,结果很不准确,而后者能够准确检测。
最后,提一下我发布的一个场景文字检测系统——TSDFNS(text string detection from natural scenes)——也许是很多人最想要的。但在这里,希望大家有时间能够读一读上面我提到的两个小实验,或许会对你在这个领域有写帮助。代码见TSDFNS。
参考文献
[1] Chucai Yi, etc. Text string detection from natural scenes by structure-based partition and grouping. TIP, 2011.
[2] Asif Shahab, etc. ICDAR 2011 Robust Reading Competition Challenge 2: Reading Text in Scene Images. ICDAR, 2011.
[3] Boris Epshtein, etc. Detecting Text in Natural Scenes with Stroke Width Transform. CVPR, 2010.(为了致敬,特意将Epshtein标为粗体)
[4] Cong Yao, etc. Detecting texts of arbitrary orientation in natural images. CVPR, 2012.
[5] Marios Anthimopoulos, etc. Detection of artificial and scene text in images and video frames. PAA, 2011.
[6] Weilin Huang, etc. Text Localization in Natural Images using Stroke Feature Transform and Text Covariance Descriptors. ICCV, 2012.
[7] Eduardo S. L. Gastal, etc. Adaptive Manifolds for Real-Time High-Dimensional Filtering. SIGGRAPH, 2012.














 3778
3778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









