






 本文探讨了微众银行面试题中的AQS同步器原理,Java并发工具AQS的使用,线程池的概念与实现,SpringBoot中的注解用法,MySQL索引优化策略,以及如何通过策略模式管理和优化复杂的业务逻辑。
本文探讨了微众银行面试题中的AQS同步器原理,Java并发工具AQS的使用,线程池的概念与实现,SpringBoot中的注解用法,MySQL索引优化策略,以及如何通过策略模式管理和优化复杂的业务逻辑。
面试题大全:www.javacn.site
昨天有一位同学分享了微众银行一面的题目,八股就问了 11 道,相比较我之前分享的农行面经,可以说细节拉满。

微众银行是由腾讯带头成立的民营企业,主要业务有微粒贷、微众银行、微车贷等等,对银行业务感兴趣的同学可以投一投。
内容较长,建议正在冲刺 24 届春招和 25 届暑期实习、秋招的同学先收藏起来,面试的时候大概率会碰到,我会尽量用通俗易懂+手绘图的方式,让天下所有的面渣都能逆袭 😁
聊一聊 AQS
AQS,全称是 AbstractQueuedSynchronizer,中文意思是抽象队列同步器,由 Doug Lea 设计,是 Java 并发包java.util.concurrent的核心框架类,许多同步类的实现都依赖于它,如 ReentrantLock、Semaphore、CountDownLatch 等。
AQS 的思想是,如果被请求的共享资源空闲,则当前线程能够成功获取资源;否则,它将进入一个等待队列,当有其他线程释放资源时,系统会挑选等待队列中的一个线程,赋予其资源。
整个过程通过维护一个 int 类型的状态和一个先进先出(FIFO)的队列,来实现对共享资源的管理。
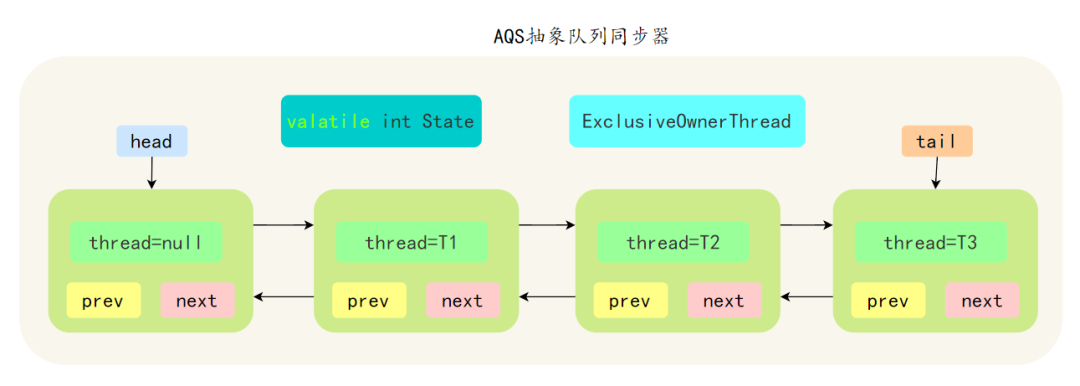
①、同步状态 state 由 volatile 修饰,保证了多线程之间的可见性;
private volatile int state;②、同步队列是通过内部定义的 Node 类来实现的,每个 Node 包含了等待状态、前后节点、线程的引用等。
static final class Node {
static final int CANCELLED = 1;
static final int SIGNAL = -1;
static final int CONDITION = -2;
static final int PROPAGATE = -3;
volatile Node prev;
volatile Node next;
volatile Thread thread;
}AQS 支持两种同步方式:
独占模式:这种方式下,每次只能有一个线程持有锁,例如 ReentrantLock。
共享模式:这种方式下,多个线程可以同时获取锁,例如 Semaphore 和 CountDownLatch。
子类可以通过继承 AQS 并实现它的方法来管理同步状态,这些方法包括:
tryAcquire:独占方式尝试获取资源,成功则返回 true,失败则返回 false;tryRelease:独占方式尝试释放资源;tryAcquireShared(int arg):共享方式尝试获取资源;tryReleaseShared(int arg):共享方式尝试释放资源;isHeldExclusively():该线程是否正在独占资源。
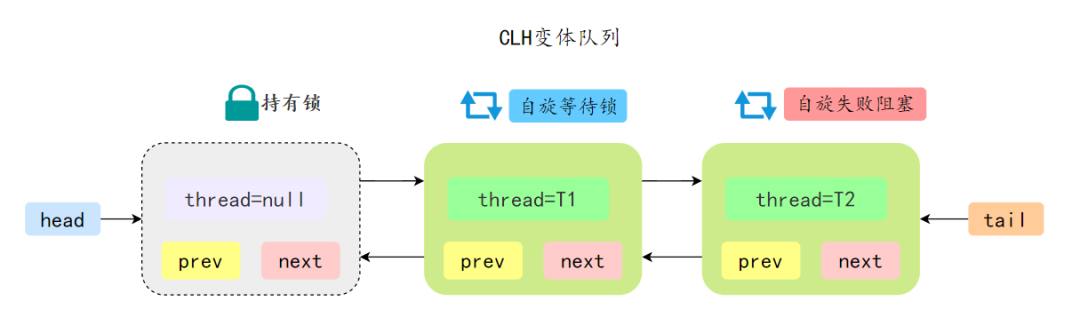
如果共享资源被占用,需要一种特定的阻塞等待唤醒机制来保证锁的分配,AQS 会将竞争共享资源失败的线程添加到一个 CLH 队列中。
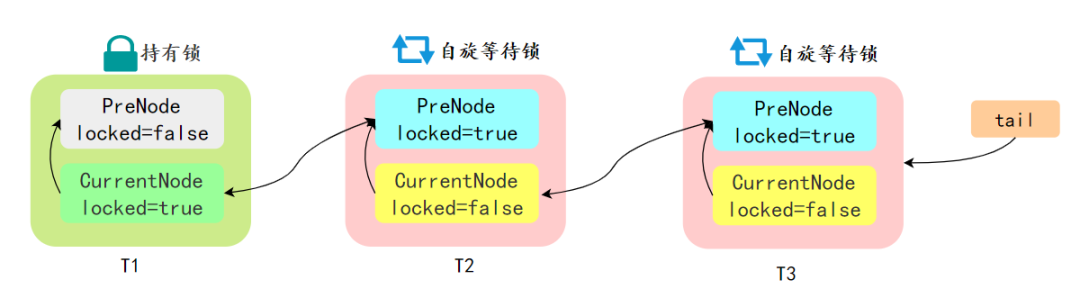
在 CLH 锁中,当一个线程尝试获取锁并失败时,它会将自己添加到队列的尾部并自旋,等待前一个节点的线程释放锁。
说说你对线程池的理解
线程池,简单来说,就是一个管理线程的池子。
①、频繁地创建和销毁线程会消耗系统资源,线程池能够复用已创建的线程。
②、提高响应速度,当任务到达时,任务可以不需要等待线程创建就立即执行。
③、线程池支持定时执行、周期性执行、单线程执行和并发数控制等功能。
线程池的阻塞队列有哪些实现方式?
在 Java 中,线程池(ThreadPoolExecutor)使用阻塞队列(BlockingQueue)来存储待处理的任务。
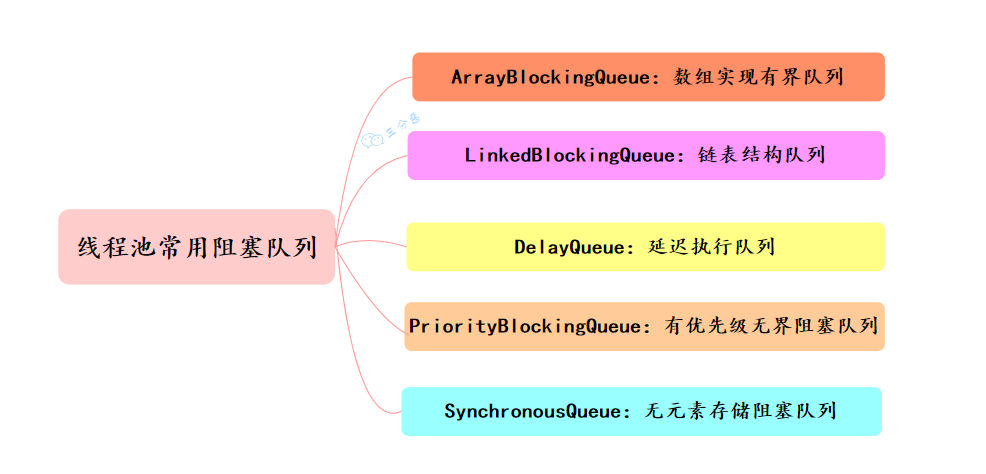
①、ArrayBlockingQueue:一个有界的先进先出的阻塞队列,底层是一个数组,适合固定大小的线程池。
ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10, true);②、LinkedBlockingQueue:底层数据结构是链表,如果不指定大小,默认大小是 Integer.MAX_VALUE,相当于一个无界队列。
技术派实战项目中,就使用了 LinkedBlockingQueue 来配置 RabbitMQ 的消息队列。
③、PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。任务按照其自然顺序或通过构造器给定的 Comparator 来排序。
适用于需要按照给定优先级处理任务的场景,比如优先处理紧急任务。
④、DelayQueue:类似于 PriorityBlockingQueue,由二叉堆实现的无界优先级阻塞队列。
Executors 中的 newScheduledThreadPool() 就使用了 DelayQueue 来实现延迟执行。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}⑤、SynchronousQueue:实际上它不是一个真正的队列,因为没有容量。每个插入操作必须等待另一个线程的移除操作,同样任何一个移除操作都必须等待另一个线程的插入操作。
Executors.newCachedThreadPool() 就使用了 SynchronousQueue,这个线程池会根据需要创建新线程,如果有空闲线程则会重复使用,线程空闲 60 秒后会被回收。
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}对异常体系了解多少?
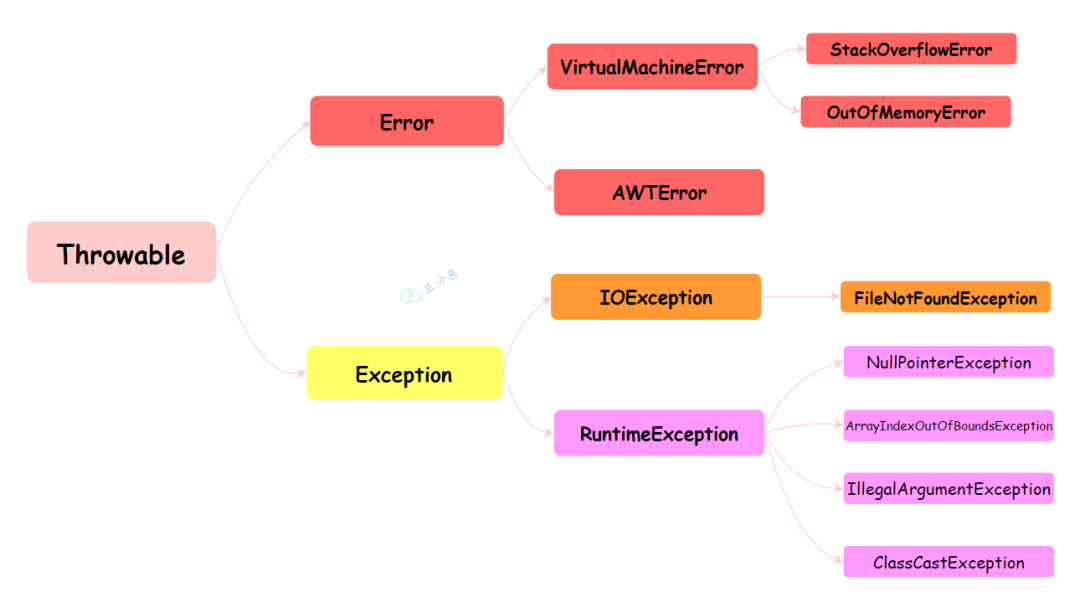
Throwable 是 Java 语言中所有错误和异常的基类。它有两个主要的子类:Error 和 Exception,这两个类分别代表了 Java 异常处理体系中的两个分支。
Error 类代表那些严重的错误,这类错误通常是程序无法处理的。比如,OutOfMemoryError 表示内存不足,StackOverflowError 表示栈溢出。这些错误通常与 JVM 的运行状态有关,一旦发生,应用程序通常无法恢复。
Exception 类代表程序可以处理的异常。它分为两大类:编译时异常(Checked Exception)和运行时异常(Runtime Exception)。
①、编译时异常(Checked Exception):这类异常在编译时必须被显式处理(捕获或声明抛出)。
如果方法可能抛出某种编译时异常,但没有捕获它(try-catch)或没有在方法声明中用 throws 子句声明它,那么编译将不会通过。例如:IOException、SQLException 等。
②、运行时异常(Runtime Exception):这类异常在运行时抛出,它们都是 RuntimeException 的子类。对于运行时异常,Java 编译器不要求必须处理它们(即不需要捕获也不需要声明抛出)。
运行时异常通常是由程序逻辑错误导致的,如 NullPointerException、IndexOutOfBoundsException 等。
@SpringBootApplication注解了解吗?
@SpringBootApplication是 Spring Boot 的核心注解,经常用于主类上,作为项目启动入口的标识。它是一个组合注解:
@SpringBootConfiguration:继承自@Configuration,标注该类是一个配置类,相当于一个 Spring 配置文件。@EnableAutoConfiguration:告诉 Spring Boot 根据 pom.xml 中添加的依赖自动配置项目。例如,如果 spring-boot-starter-web 依赖被添加到项目中,Spring Boot 会自动配置 Tomcat 和 Spring MVC。@ComponentScan:扫描当前包及其子包下被@Component、@Service、@Controller、@Repository注解标记的类,并注册为 Spring Bean。
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}说说 Spring 常见的注解?
Spring 提供了大量的注解来简化 Java 应用的开发和配置,主要用于 Web 开发、往容器注入 Bean、AOP、事务控制等。
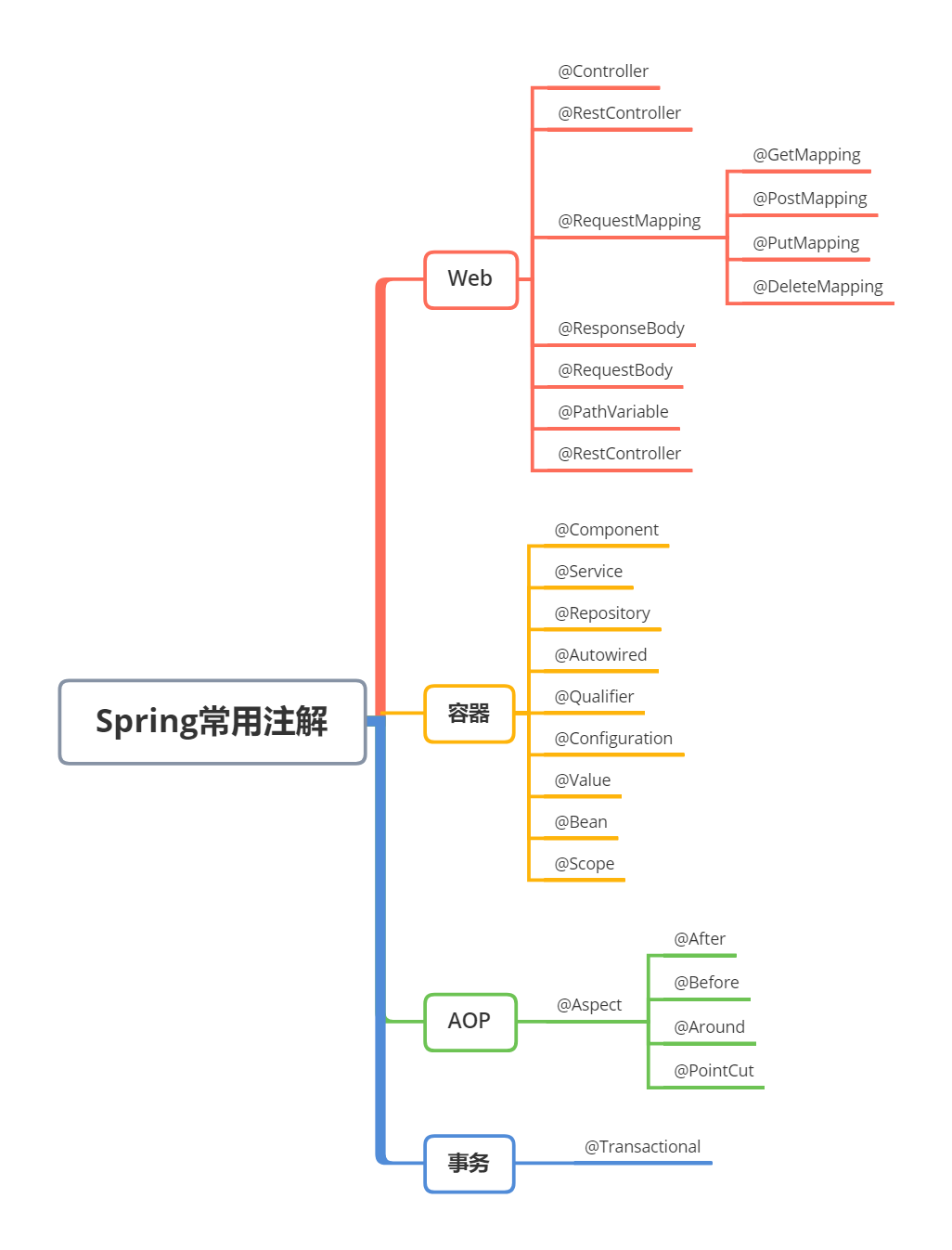
Web 开发方面有哪些注解呢?
①、@Controller:用于标注控制层组件。
②、@RestController:是@Controller 和 @ResponseBody 的结合体,返回 JSON 数据时使用。
③、@RequestMapping:用于映射请求 URL 到具体的方法上,还可以细分为:
@GetMapping:只能用于处理 GET 请求@PostMapping:只能用于处理 POST 请求@DeleteMapping:只能用于处理 DELETE 请求
④、@ResponseBody:直接将返回的数据放入 HTTP 响应正文中,一般用于返回 JSON 数据。
⑤、@RequestBody:表示一个方法参数应该绑定到 Web 请求体。
⑥、@PathVariable:用于接收路径参数,比如 @RequestMapping(“/hello/{name}”),这里的 name 就是路径参数。
⑦、@RequestParam:用于接收请求参数。比如 @RequestParam(name = "key") String key,这里的 key 就是请求参数。
容器类注解有哪些呢?
@Component:标识一个类为 Spring 组件,使其能够被 Spring 容器自动扫描和管理。@Service:标识一个业务逻辑组件(服务层)。比如@Service("userService"),这里的 userService 就是 Bean 的名称。@Repository:标识一个数据访问组件(持久层)。@Autowired:按类型自动注入依赖。@Configuration:用于定义配置类,可替换 XML 配置文件。@Value:用于将 Spring Boot 中 application.properties 配置的属性值赋值给变量。
AOP 方面有哪些注解呢?
@Aspect 用于声明一个切面,可以配合其他注解一起使用,比如:
@After:在方法执行之后执行。@Before:在方法执行之前执行。@Around:方法前后均执行。@PointCut:定义切点,指定需要拦截的方法。
事务注解有哪些?
主要就是 @Transactional,用于声明一个方法需要事务支持。
SpringTask 了解吗?
SpringTask 是 Spring 框架提供的一个轻量级的任务调度框架,它允许我们开发者通过简单的注解来配置和管理定时任务。
①、@Scheduled:最常用的注解,用于标记方法为计划任务的执行点。技术派实战项目中,就使用该注解来定时刷新 sitemap.xml:
@Scheduled(cron = "0 15 5 * * ?")
public void autoRefreshCache() {
log.info("开始刷新sitemap.xml的url地址,避免出现数据不一致问题!");
refreshSitemap();
log.info("刷新完成!");
}@Scheduled 注解支持多种调度选项,如 fixedRate、fixedDelay 和 cron 表达式。
②、@EnableScheduling:用于开启定时任务的支持。
MySQL 索引如何优化?
正确地使用索引可以显著减少 SQL 的查询时间,通常可以从索引覆盖、避免使用 != 或者 <> 操作符、适当使用前缀索引、避免列上函数运算、正确使用联合索引等方面进行优化。
①、利用覆盖索引
使用非主键索引查询数据时需要回表,但如果索引的叶节点中已经包含要查询的字段,那就不会再回表查询了,这就叫覆盖索引。
举个例子,现在要从 test 表中查询 city 为上海的 name 字段。
select name from test where city='上海'如果仅在 city 字段上添加索引,那么这条查询语句会先通过索引找到 city 为上海的行,然后再回表查询 name 字段,这就是回表查询。
为了避免回表查询,可以在 city 和 name 字段上建立联合索引,这样查询结果就可以直接从索引中获取。
alter table test add index index1(city,name);②、避免使用 != 或者 <> 操作符
!= 或者 <> 操作符会导致 MySQL 无法使用索引,从而导致全表扫描。
例如,可以把column<>'aaa',改成column>'aaa' or column<'aaa',就可以使用索引了。
优化策略就是尽可能使用 =、>、<、BETWEEN等操作符,它们能够更好地利用索引。
③、适当使用前缀索引
适当使用前缀索引可以降低索引的空间占用,提高索引的查询效率。
比如,邮箱的后缀一般都是固定的@xxx.com,那么类似这种后面几位为固定值的字段就非常适合定义为前缀索引:
alter table test add index index2(email(6));需要注意的是,MySQL 无法利用前缀索引做 order by 和 group by 操作。
④、避免列上使用函数
在 where 子句中直接对列使用函数会导致索引失效,因为数据库需要对每行的列应用函数后再进行比较,无法直接利用索引。
select name from test where date_format(create_time,'%Y-%m-%d')='2021-01-01';可以改成:
select name from test where create_time>='2021-01-01 00:00:00' and create_time<'2021-01-02 00:00:00';通过日期的范围查询,而不是在列上使用函数,可以利用 create_time 上的索引。
⑤、正确使用联合索引
正确地使用联合索引可以极大地提高查询性能,联合索引的创建应遵循最左前缀原则,即索引的顺序应根据列在查询中的使用频率和重要性来安排。
select * from messages where sender_id=1 and receiver_id=2 and is_read=0;那就可以为 sender_id、receiver_id 和 is_read 这三个字段创建联合索引,但是要注意索引的顺序,应该按照查询中的字段顺序来创建索引。
alter table messages add index index3(sender_id,receiver_id,is_read);MySQL 和缓存一致性问题了解吗?
在技术派实战项目中,我采用的是先写 MySQL,再删除 Redis 的方式来保证缓存和数据库的数据一致性。

对于第一次查询,请求 B 查询到的缓存数据是 10,但 MySQL 被请求 A 更新为了 11,此时数据库和缓存不一致。
但也只存在这一次不一致的情况,对于不是强一致性的业务,可以容忍。
当请求 B 第二次查询时,因为请求 A 更新完数据库把缓存删除了,所以请求 B 这次不会命中缓存,会重新查一次 MySQL,然后回写到 Redis。
缓存和数据库又一致了。
Redis 为什么这么快?
Redis 的速度⾮常快,单机的 Redis 就可以⽀撑每秒十几万的并发,性能是 MySQL 的⼏⼗倍。速度快的原因主要有⼏点:
①、基于内存的数据存储,Redis 将数据存储在内存当中,使得数据的读写操作避开了磁盘 I/O。而内存的访问速度远超硬盘,这是 Redis 读写速度快的根本原因。
②、单线程模型,Redis 使用单线程模型来处理客户端的请求,这意味着在任何时刻只有一个命令在执行。这样就避免了线程切换和锁竞争带来的消耗。
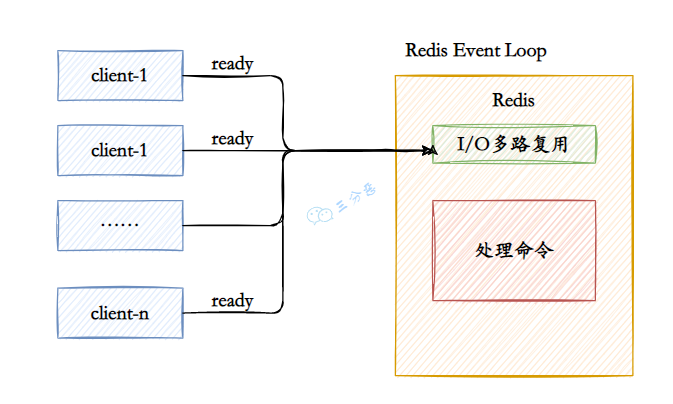
③、IO 多路复⽤,基于 Linux 的 select/epoll 机制。该机制允许内核中同时存在多个监听套接字和已连接套接字,内核会一直监听这些套接字上的连接请求或者数据请求,一旦有请求到达,就会交给 Redis 处理,就实现了所谓的 Redis 单个线程处理多个 IO 读写的请求。
④、高效的数据结构,Redis 提供了多种高效的数据结构,如字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)等,这些数据结构经过了高度优化,能够支持快速的数据操作。
if else过多怎么解决?
策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列的算法,将每个算法封装起来,使得它们可以相互替换。这种模式通常用于实现不同的业务规则或策略,其中每种策略封装了特定的行为或算法。
特别适合用于优化程序中的复杂条件分支语句(if-else),将不同的分支逻辑封装到不同的策略类中,然后通过上下文类来选择不同的策略。
在策略模式中,有三个角色:上下文(Context)、策略接口(Strategy Interface)和具体策略(Concrete Strategy)。
策略接口:定义所有支持的算法的公共接口。策略模式的核心。
具体策略:实现策略接口的类,提供具体的算法实现。
上下文:使用策略的类。通常包含一个引用指向策略接口,可以在运行时改变其具体策略。
比如说在技术派中,用户可以自由切换 AI 服务,服务端可以通过 if/esle 进行判断,但如果后续需要增加新的 AI 服务,就需要修改代码,这样不够灵活。
因此,我们使用了策略模式,将不同的 AI 服务封装成不同的策略类,通过工厂模式创建不同的 AI 服务实例,从而实现 AI 服务的动态切换。
@Service
public class PaiAiDemoServiceImpl extends AbsChatService {
@Override
public AISourceEnum source() {
return AISourceEnum.PAI_AI;
}
}
@Slf4j
@Service
public class ChatGptAiServiceImpl extends AbsChatService {
@Override
public AISourceEnum source() {
return AISourceEnum.CHAT_GPT_3_5;
}
}
@Slf4j
@Service
public class XunFeiAiServiceImpl extends AbsChatService {
@Override
public AISourceEnum source() {
return AISourceEnum.XUN_FEI_AI;
}
}参考链接
三分恶的面渣逆袭:https://javabetter.cn/sidebar/sanfene/nixi.html
二哥的 Java 进阶之路:https://javabetter.cn
重磅推荐
我的《Java面试突击训练营》还在火热招生中,它是有着 14 年工作经验(前 360 开发工程师),9 年面试官经验的我,花费 4 年时间打磨完成的一门视频面试课。
整个课程从 Java 基础到微服务 Spring Cloud、从实际开发问题到场景题应有尽有,包含模块如下:
训练营系统的带领大家把 Java 常见的面试题过一遍,遇到一个问题,把这个问题相关的内容都给大家讲明白,并且视频支持永久观看和一直更新。并且面试训练营还提供 10 大就业服务。
上完训练营的课程之后,基本可以应对目前市面上绝大部分公司的面试了,想要了解详情,加我微信:GG_Stone【备注:训练营】


















 5920
5920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









