








Abstract
最近邻搜索是一个从数据库中寻找数据点的问题,使得数据点到查询点的距离最小。学习哈希是这个问题的主要解决方案之一,最近得到了广泛的研究。在本文中,我们对哈希算法的学习进行了全面的综述,根据保持相似度的方式将它们分为:成对相似度保持、多重相似度保持、隐式相似度保持和量化,并讨论了它们之间的关系。我们将量化与成对相似度保持分离开来,因为目标函数非常不同,尽管量化,如我们所示,可以从保持成对相似度中推导出来。此外,我们提出了评估协议和一般性能分析,并指出量化算法在搜索精度、搜索时间成本和空间成本方面表现优越。最后,我们将介绍几个新出现的主题。
索引术语:相似度搜索,近似最近邻搜索,哈希,学习哈希,量化,成对相似度保持,多重相似度保持,隐式相似度保持。
Introduction
最近邻搜索问题,也称为相似性搜索、接近性搜索或近项搜索,其目的是找到一个项,称为最近邻,它是在搜索数据库的一定距离度量下与查询项最近的项。如果参考数据库非常大,或者计算查询项和数据库项之间的距离代价很大,那么查找最接近的邻居的代价就会非常高。另一种方法,近似最近邻搜索,是更有效的,并被证明是足够和有用的许多实际问题,从而吸引了大量的研究工作。
哈希是一种被广泛研究的近似最近邻搜索的解决方案,旨在将数据项转换为低维表示,或等效地转换为由一组位序列组成的短代码,称为哈希代码。哈希算法主要有两类:局部敏感哈希和学习哈希。位置敏感散列(LSH)与数据无关。继[14]、[44]等先驱工作之后,人们又进行了大量的努力,如提出了满足各种距离度量的局部敏感性的随机哈希函数,证明了更好的搜索效率和精度,开发了更好的搜索方案,提供了方差更小的相似估计器,更小的存储,或更快的哈希函数计算。LSH已被应用于许多领域,如快速目标检测,图像匹配,关于LSH的详细综述见。
学习哈希是本次调查的兴趣所在,它是一种依赖于数据的哈希方法,目的是从特定的数据集中学习哈希函数,使哈希编码空间中最近邻的搜索结果尽可能接近原始空间中的搜索结果,并且搜索代价和空间代价都很小。学习哈希的发展受到了汉明距离和从原始空间提供的距离之间的联系的启发,例如,SimHash中显示的余弦距离。语义哈希和谱哈希这两种早期算法学习投影向量,而不是像[14]那样随机投影,学习哈希已经吸引了计算机视觉和机器学习领域的大量研究兴趣,并已被广泛应用于大规模对象检索、图像分类和检测等领域。
学习哈希的主要方法是相似度保持,即尽量减少原始空间中计算/给定的相似度与哈希编码空间中各种形式的相似度之间的差距。原始空间中的相似性可能来自语义(类)信息,也可能来自原始空间中计算的距离(如欧几里得距离),这在实际应用中具有广泛的兴趣和广泛的研究,如大规模图像搜索和图像分类。因此,后者是本文研究的重点。
本次调查根据相似度保持方式将算法分为:成对相似度保持,多重相似度保持,隐式相似度保持,我们将展示的量化也是成对相似度保持的一种形式,以及一种端到端哈希学习策略,在深度学习框架下直接从对象(例如图像)学习哈希码,而不是先学习表示,然后再从表示学习哈希码。此外,我们还讨论了评价数据集和评价方案等问题。同时,我们提出了量化方法优于其他方法的经验观察,并对此进行了一些分析。
与其他关于学习哈希的调查相比,这项调查更侧重于学习哈希,更多地讨论基于量化的解决方案。我们的分类方法有助于读者了解现有算法之间的联系和差异。我们特别指出,实证观察表明,量化在搜索精度、搜索效率和空间成本方面具有优势。
3. 学习哈希
学习哈希是学习一个(复合)哈希函数y = h(x),将一个输入项x映射到一个紧凑代码y,目的是使查询q的最近邻居搜索结果尽可能接近于真正的最近搜索结果,并且在编码空间中的搜索也是有效的。学习哈希方法需要考虑五个问题:采用什么样的哈希函数h(x),在编码空间中使用什么样的相似度,在输入空间中提供什么样的相似度,为优化目标选择什么样的损失函数,以及采用什么样的优化技术。
3.1 哈希函数
哈希函数可以基于线性投影、克尔函数、球面函数、(深度)神经网络、非参数函数等。一个流行的哈希函数是线性哈希函数。
哈希函数的形式是影响哈希码搜索精度的重要因素,也是影响哈希码计算时间成本的重要因素。线性函数可以有效地求值,而基于核函数和最近向量赋值的函数由于更灵活而导致更好的搜索精度。几乎所有使用线性哈希函数的方法都可以扩展到非线性哈希函数,例如内核哈希函数或神经网络。因此,我们不使用哈希函数来分类哈希算法。
3.2 相似度
欧式距离/汉明距离
3.3 损失函数
设计损失函数的基本原则是保持相似顺序,即最小化从哈希码计算出的近似最近邻搜索结果与从输入空间获得的真实搜索结果之间的差距。
广泛使用的解决方案是成对相似度保持,使输入和编码空间的一对项之间的距离或相似度尽可能一致。同时,还研究了使输入空间和编码空间计算出的多个项目之间的顺序尽可能一致的多方向相似保持解。一类解决方案,例如空间划分,隐式地保留了相似性。基于量化的解决方案和其他基于重建的解决方案旨在通过重建函数(例如,以量化中的查找表或自动编码器的形式)根据重建误差找到项目的最佳近似。除了相似度保持项外,一些方法还引入桶平衡或其近似变量作为额外约束,这对于获得更好的结果或避免琐碎的解也很重要。
3.4 优化
优化哈希函数参数的挑战主要在于两个因素。一是问题包含sgn函数,这导致了一个具有挑战性的混合二进制整数优化问题。二是在处理大量数据点时,时间复杂度较高,通常通过采样点的子集或约束的子集(或目标函数中等价的基本术语)来处理。
下面总结了处理sgn函数的方法。第一种方法是最广泛采用的连续松弛,包括sigmoid松弛、tanh松弛,以及直接去掉符号函数sgn(z)≈z,然后使用各种标准优化技术来解决松弛问题。第二种是两步方案及其扩展到备选优化:在不考虑哈希函数的情况下优化二进制代码,然后根据优化的哈希代码估计函数参数。第三种方法是离散化:去掉符号函数sgn(z)≈z,并将哈希代码视为哈希函数的近似值,其表达式为损失(y−z)2。还有一些方法仅在少数算法中采用,如将问题转化为潜在的结构-svm公式,坐标下降法(固定除一个权值外的所有权值,在每次迭代中针对单个权值优化原始目标),这两种方法都不进行连续松弛。
3.5 分类
根据采用何种相似保持方式来表示目标函数,我们将现有的算法分类为:成对相似保持类、多wise相似保持类、隐式相似保持类以及量化类。我们将量子化类与成对相似度保持类分开,因为量子化类可以从成对相似度保持的角度来解释,但它们在表述上有很大的不同。在下面的描述中,我们可以将全权化称为基于量化的哈希,将哈希函数生成二进制值的其他算法称为二进制代码哈希。此外,我们还将讨论其他关于学习哈希的研究。代表性算法的总结如表1所示。
选择相似度保持方式进行分类的主要原因是相似度保持是哈希的基本目标。需要注意的是,其他因素如哈希函数或优化算法,对搜索性能也很重要。
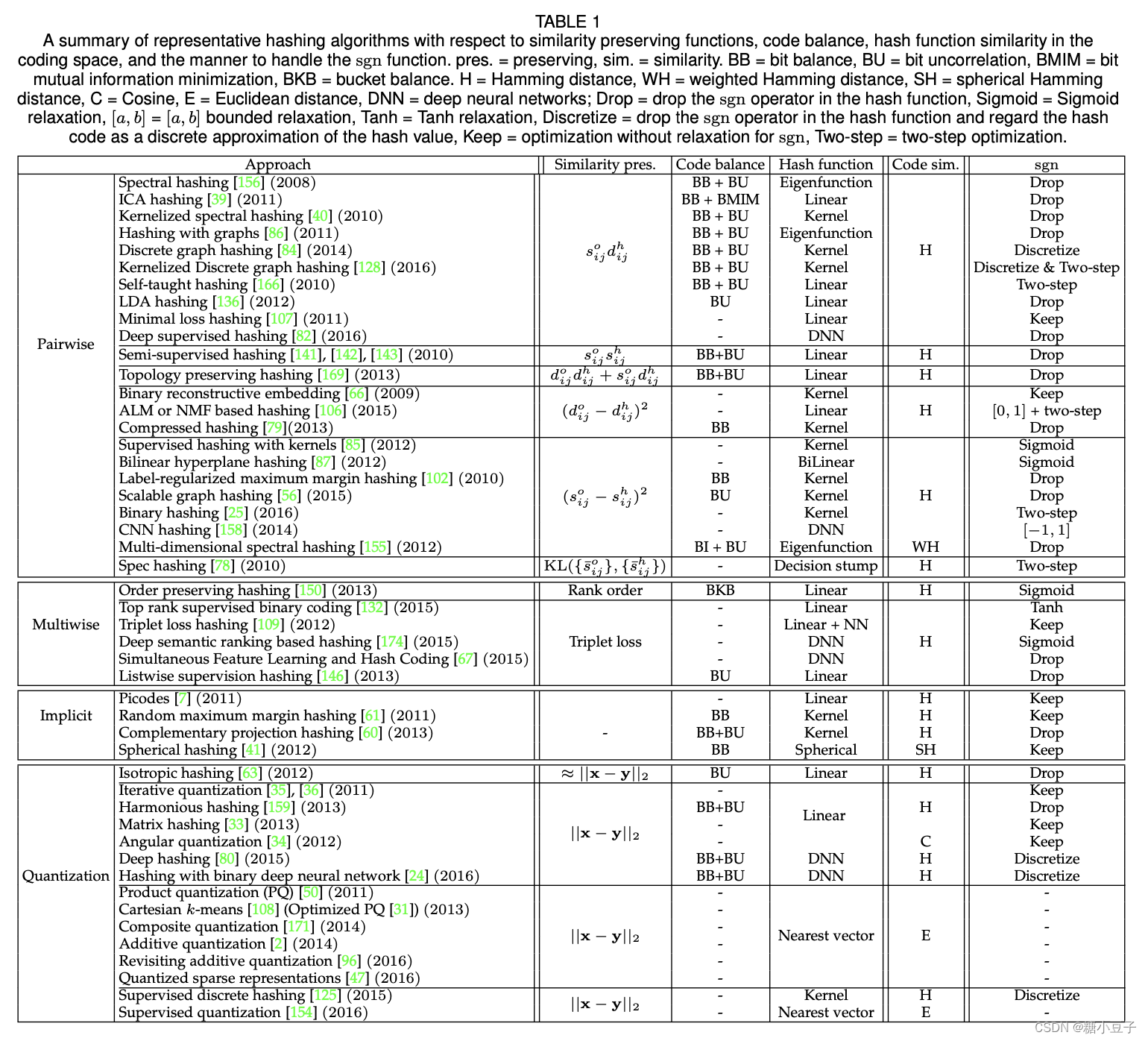
4. 成对相似度保持
从输入空间和汉明编码空间计算出的一对项目的距离或相似性的对齐算法大致分为以下几组:
- 相似距离积最小化(SDPM)
- 相似-相似积最大化(SSPM)
- 距离-距离乘积最大化(DDPM)
- 距离相似积最小化(DSPM)
- 相似-相似差异最小化(SSDM)
- 距离-距离差最小化(DDDM)
- 归一化相似度-相似度差异最小化(NSSDM)
下面回顾这些算法组,除了距离相似积最小化组,我们不知道任何算法属于它。需要注意的是,仅仅优化上述相似保持函数,如SDPM和SSPM,是不够的,可能会得到琐碎的解,需要结合其他约束,这将在接下来的讨论中详细说明。我们还指出了相似距离积最小值与相似相似积最大值的关系,以及相似相似积m的关系
5. 多重相似度保持
本节回顾了哈希算法的类别,这些算法通过最大化从输入空间和编码空间计算的两个以上项目的相似顺序的一致性来制定损失函数。
保序哈希(Order preserving hashing)旨在通过对齐从原始空间和编码空间中计算的顺序来学习哈希函数。
三组损失哈希(Triplet loss hashing)通过最大化在三组项目上定义的相似顺序一致来阐述哈希问题。
列表式监督哈希(Listwise supervision hashing)也使用三项。这个公式基于一个三重张量。
6. 隐式相似度保持
我们回顾了哈希算法的类别,这些算法专注于追求有效的空间划分,而不显式地评估输入空间和编码空间中的距离/相似性之间的关系。通常的思想是用最大裕度准则或代码平衡条件将空间划分为分类问题。
随机最大裕度哈希学习一个具有最大裕度准则的哈希函数。重点是,通过随机抽取N个数据项,将一半数据项随机标记为−1,另一半数据项随机标记为1,随机生成正负标签。
互补投影哈希,类似于互补哈希,查找的哈希函数是使项目尽可能远离哈希函数对应的分区平面。
球面哈希[41]使用超球面来划分空间。
7. 量化QUANTIZATION
下面提供了一个简单的推导,表明量化方法可以从距离-距离差最小化准则推导出来。从统计学角度得到的[50]中也有类似的表述:距离重构误差在统计学上受量化误差的限制。
8. 其他话题
8.1 基于深度学习的联合特征和哈希学习
8.2 汉明空间中的快速搜索
8.3 反向多索引
9. 评价方案
9.1 评价标准
9.2 评估数据集
目前广泛使用的评价数据集有小、大、超大等不同规模。已经使用了各种特征,例如从Phototourism[131]和Caltech 101中提取的SIFT特征,从LabelMe和Peekaboom中提取的GIST特征,以及用于对象检索的一些特征:Fisher向量和VLAD向量。下面简要介绍几个有代表性的数据集,如表2所示。

MNIST[68]包括60K 784维原始像素特征,描述手写数字的灰度图像作为参考集,10K特征作为查询。
SIFT10K[50]由10K个128维SIFT向量作为参考集,25K个向量作为学习集,100个向量作为查询集组成。SIFT1M[50]由1M个128维SIFT向量作为参考集,100K向量作为学习集,10K向量作为查询集组成。SIFT10K和SIFT1M中的学习集从Flicker图像中提取,参考集和查询集从INRIA假日图像[49]中提取。
GIST1M[50]由1M个960维GIST向量作为参考集,50K向量作为学习集,1K向量作为查询集组成。学习集从微小图像的前100K图像中提取[137]。参考集来自Holiday图像结合Flickr1M[49]。查询集来自Holiday图像查询。Tiny1M[152]1由1M个384维GIST向量作为参考集,100K向量作为查询集组成。这两个集合是从1100K微小图像中提取出来的。
SIFT1B[53]包含1B个128维byte值的SIFT向量作为参考集,100M向量作为学习集,10K向量作为查询集。这三组图像是从大约1M的图像中提取出来的。该数据集以及SIFT10K、SIFT1M和GIST1M都是公开的2。
GloVe1.2M[115]3包含从Tweets中提取的1,193,514个200维单词特征向量。我们随机抽取10K向量作为查询集,其余的向量作为训练集。
CONCLUSION
在本文中,我们将学习哈希算法分为四大类:成对相似度保持算法、多重相似度保持算法、隐式相似度保持算法和量化算法,并对它们之间的关系进行了全面的考察和讨论。我们指出,实证观察表明,量化在搜索精度、搜索效率和空间成本方面具有优势。此外,我们还介绍了一些新兴的主题和有前景的扩展。














 5159
5159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









