







 本文介绍了通过"三次简化一张图"的方法理解LSTM和GRU的门控机制,以解决RNN的梯度消失问题。LSTM有输入门、遗忘门和输出门,GRU则融合了这两个门,结构更为简洁。通过分析门控单元的作用,揭示了它们如何有效传播梯度信息。
本文介绍了通过"三次简化一张图"的方法理解LSTM和GRU的门控机制,以解决RNN的梯度消失问题。LSTM有输入门、遗忘门和输出门,GRU则融合了这两个门,结构更为简洁。通过分析门控单元的作用,揭示了它们如何有效传播梯度信息。

作者 | 张皓
引言
RNN是深度学习中用于处理时序数据的关键技术, 目前已在自然语言处理, 语音识别, 视频识别等领域取得重要突破, 然而梯度消失现象制约着RNN的实际应用。LSTM和GRU是两种目前广为使用的RNN变体,它们通过门控机制很大程度上缓解了RNN的梯度消失问题,但是它们的内部结构看上去十分复杂,使得初学者很难理解其中的原理所在。本文介绍”三次简化一张图”的方法,对LSTM和GRU的内部结构进行分析。该方法非常通用,适用于所有门控机制的原理分析。
预备知识: RNN
RNN (recurrent neural networks, 注意不是recursiveneural networks)提供了一种处理时序数据的方案。和n-gram只能根据前n-1个词来预测当前词不同, RNN理论上可以根据之前所有的词预测当前词。在每个时刻, 隐层的输出ht依赖于当前词输入xt和前一时刻的隐层状态ht-1:
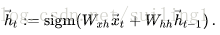
其中:=表示”定义为”, sigm代表sigmoid函数sigm(z):=1/(1+exp(-z)), Wxh和Whh是可学习的参数。结构见下图:
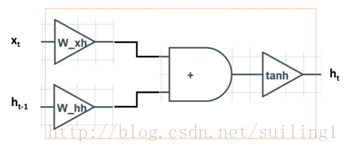
图中左边是输入,右边是输出。xt是当前词,ht-1记录了上文的信息。xt和ht-1在分别乘以Wxh和Whh之后相加,再经过tanh非线性变换,最终得到ht。
在反向传播时,我们需要将RNN沿时间维度展开,隐层梯度在沿时间维度反向传播时需要反复乘以参数。因此, 尽管理论上RNN可以捕获长距离依赖, 但实际应用中,根据谱半径(spectralradius)的不同,RNN将会面临两个挑战:梯度爆炸(gradient explosion)和梯度消失(vanishing gradient)。梯度爆炸会影响训练的收敛,甚至导致网络不收敛;而梯度消失会使网络学习长距离依赖的难度增加。这两者相比, 梯度爆炸相对比较好处理,可以用梯度裁剪(gradientclipping)来解决,而如何缓解梯度消失是RNN及几乎其他所有深度学习方法研究的关键所在。
LSTM
LSTM通过设计精巧的网络结构来缓解梯度消失问题,其数学上的形式化表示如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









