







内容
负载类型不同,需要解决的问题不同,常见的负载类型有如下几种:
- CPU密集型,如运行归并排序算法
- IO密集型,如进行 REST 调用或数据库查询
- 内存密集型(相对来说,内存已经十分低廉,所以暂时不讨论)
接下来结合一种并发模式——工作者池(worker pooling)来理解为啥对负载类型分类很重要。
这个例子中实现了一个read函数,接收io.Reader,并不断地从其中读取 1024 字节的数据。然后将这1024字节送给一个task函数,这个任务函数会返回一个整数,然后将返回的整数进行汇总,最终返回。
func read(r io.Reader) (int, error) {
count := 0
for {
b := make([]byte, 1024)
_, err := r.Read(b)
if err != nil {
if err == io.EOF {
break
}
return 0, err
}
count += task(b)
}
return count, nil
}
这段函数创建了一个计数变量,从 io.Reader 输入中读取数据,调用任务函数,并递增计数。那么,如果我们想要以并行的方式运行所有的任务函数,该怎么办呢?
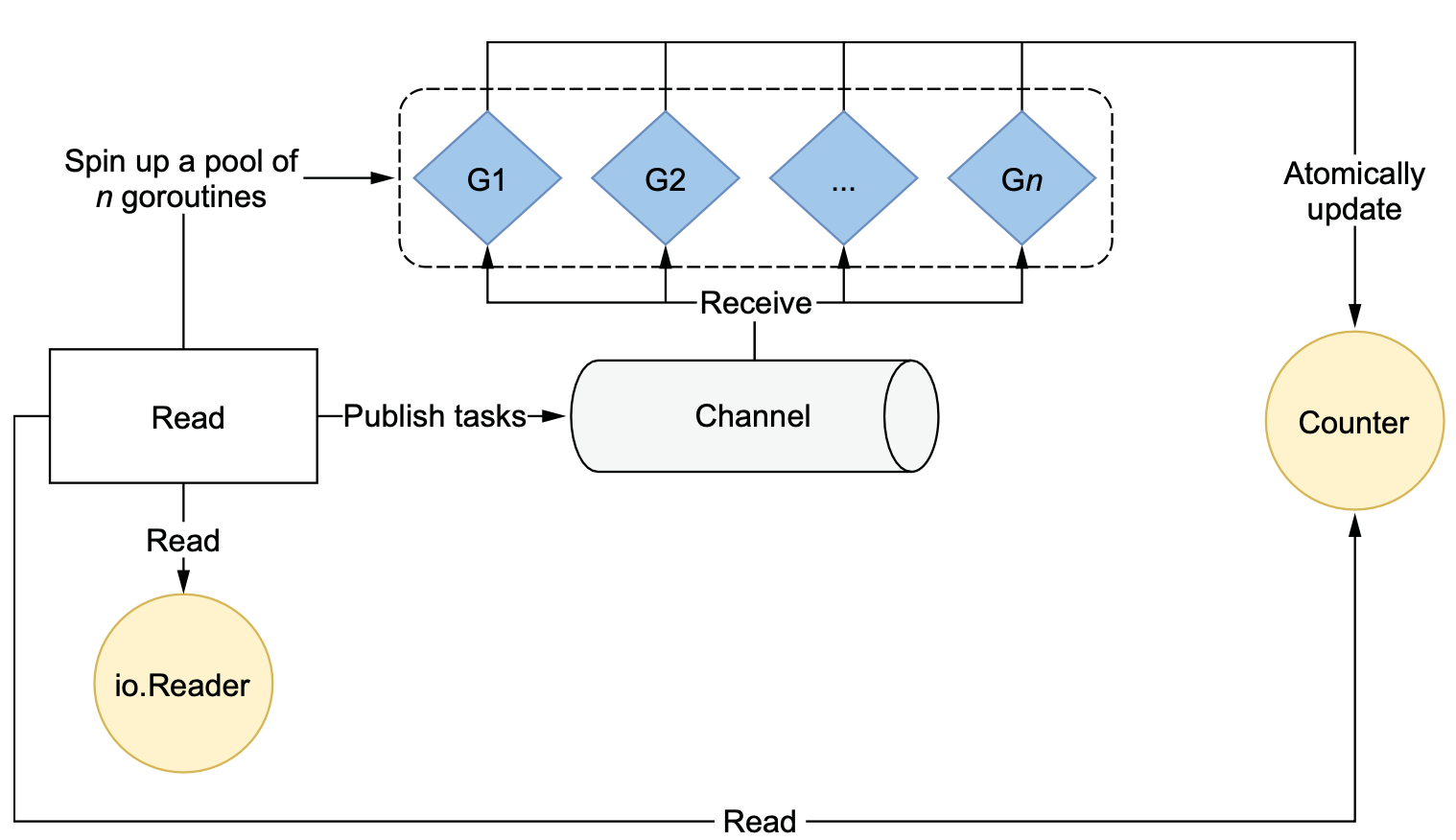
一种选择是使用所谓的工作者池模式。这样做需要创建固定数量的工作者(协程),这些工作者从一个公共通道中获取任务。
func read(r io.Reader) (int, error) {
var count int64
wg := sync.WaitGroup{}
var n = 10
ch := make(chan []byte, n) // 创建一个channel,容量等于工作池
wg.Add(n) // 通过wait group保证每个goroutine都执行结束才返回
for i := 0; i < n; i++ { // 创建n个工作协程(goroutines)。
go func() {
defer wg.Done() // 执行结束后调用Done方法
for b := range ch {
v := task(b)
atomic.AddInt64(&count, int64(v))
}
}()
}
for {
b := make([]byte, 1024)
// Read from r to b
ch <- b
}
close(ch)
wg.Wait()
return int(count), nil
}
上述代码通过定义一个n来控制工作池、channel的容量以及wait group的大小,关于n设置多大,取决于工作负载类型。
如果工作负载是 I/O 密集型,答案主要取决于外部系统。如果我们想要最大化吞吐量,系统能够应对多少并发访问。
如果工作负载是 CPU 密集型,一个最佳实践是依靠 GOMAXPROCS。GOMAXPROCS 是一个变量,用于设置分配给运行 goroutine 的操作系统线程数量。默认情况下,该值被设置为逻辑 CPU 的数量。
那么,将池的大小映射到GOMAXPROCS的理由是什么?让我们举一个具体的例子,在四核机器上运行我们的应用程序,Go 运行时会实例化 4 个操作系统线程来执行 goroutine。最初可能只有一个 goroutine 被执行,其他三个处于可运行状态但未分配给线程,没有与内核关联。
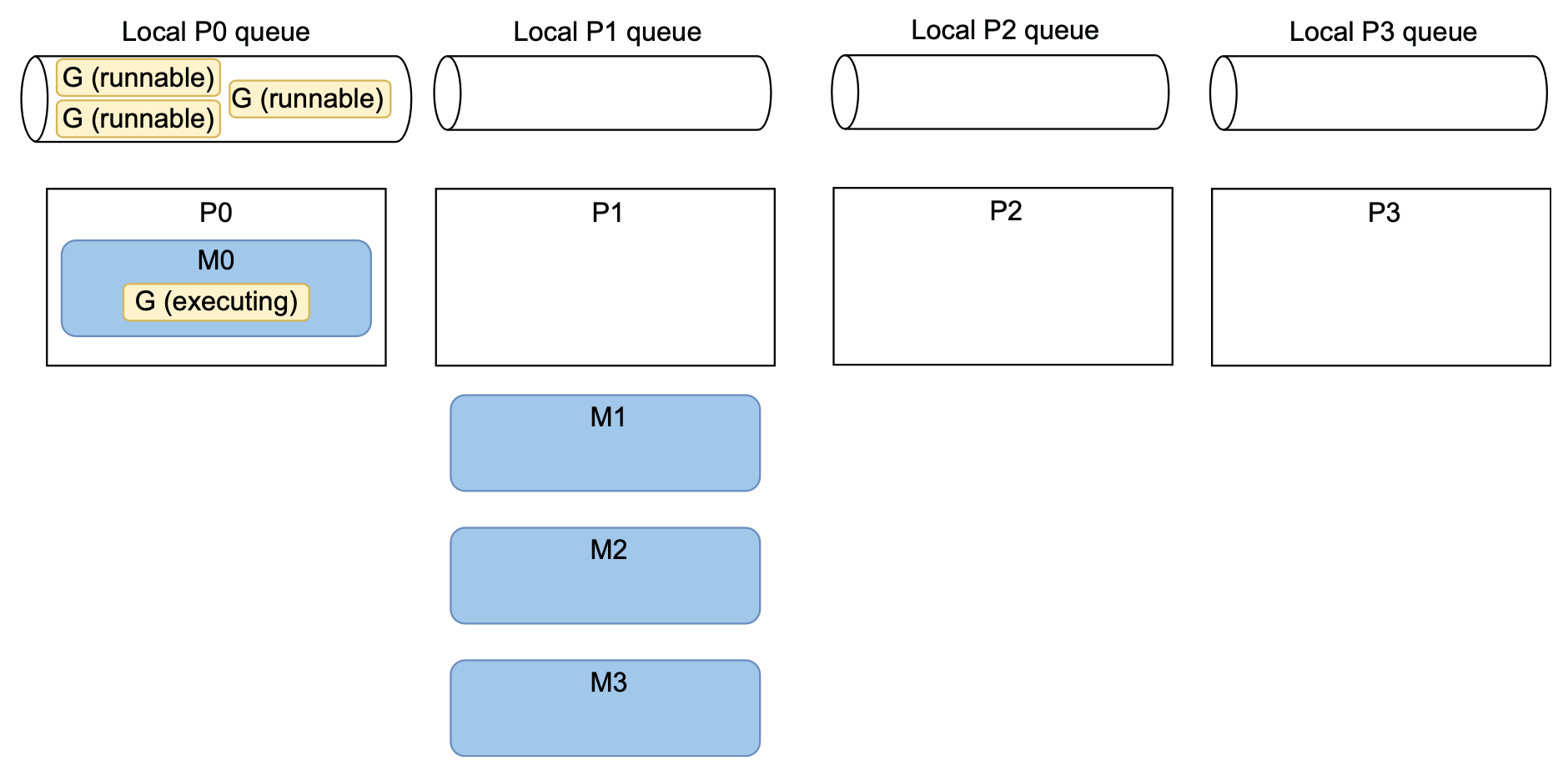
M0 正在运行工作池中的一个 goroutine,这个 goroutine 开始从通道接收消息并执行任务。而工作池中的其他三个 goroutine 尚未分配给 M,它们处于可运行状态。M1、M2 和 M3 没有任何 goroutine 可运行,所以它们没有与内核关联,导致只有一个 goroutine 在运行。
最终,前边提到过的work-stealing概念,P1 可能会从本地的 P0 队列中窃取 goroutine。在图中,P1 从 P0 窃取了三个 goroutine。在这种情况下,Go 调度器最终也可能会将所有的 goroutine 分配到不同的操作系统线程,但无法保证这种情况何时会发生。然而,由于 Go 调度器的主要目标之一是优化资源(在这里是 goroutine 的分配),鉴于工作负载的性质,我们应该最终会处于这样一种场景中。
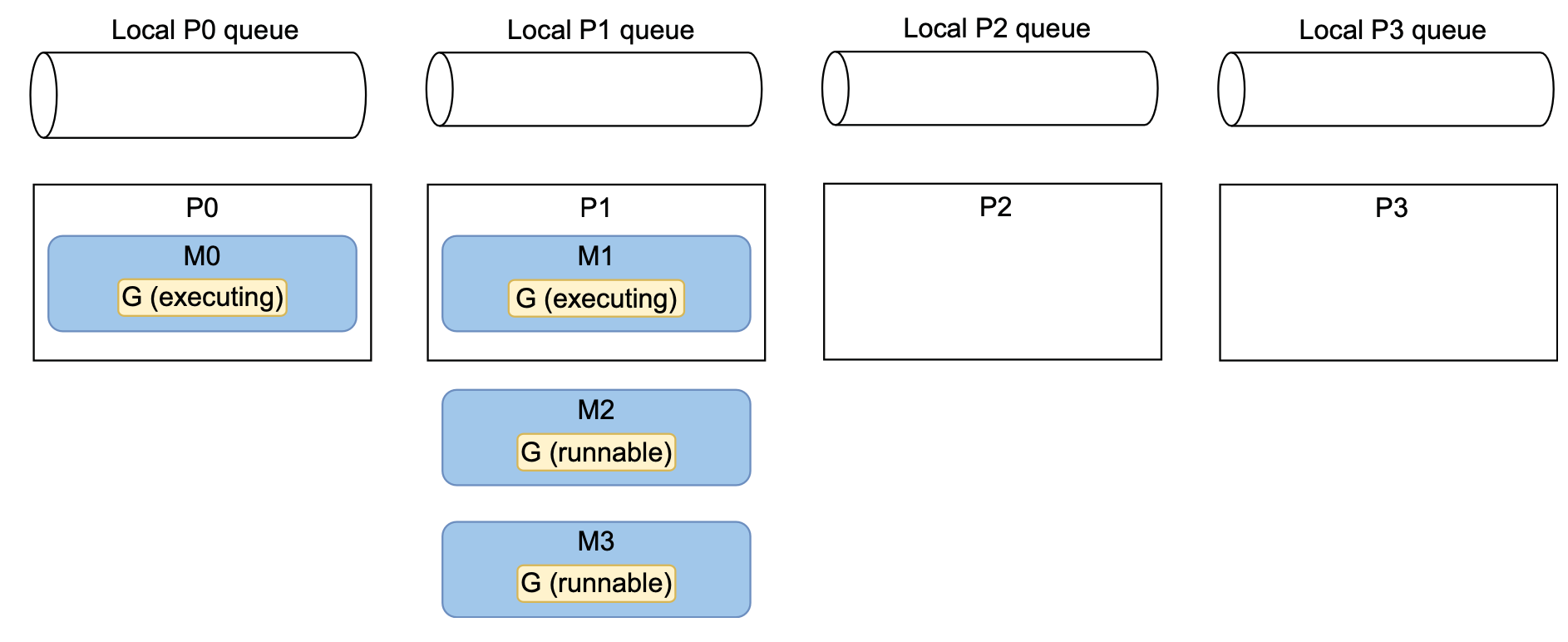
这种场景仍然不是最优的,因为最多只有两个 goroutine 在运行。假设机器上除了操作系统进程外只运行我们的应用程序,所以 P2 和 P3 是空闲的。最终,操作系统应该如下图中所示移动 M2 和 M3。
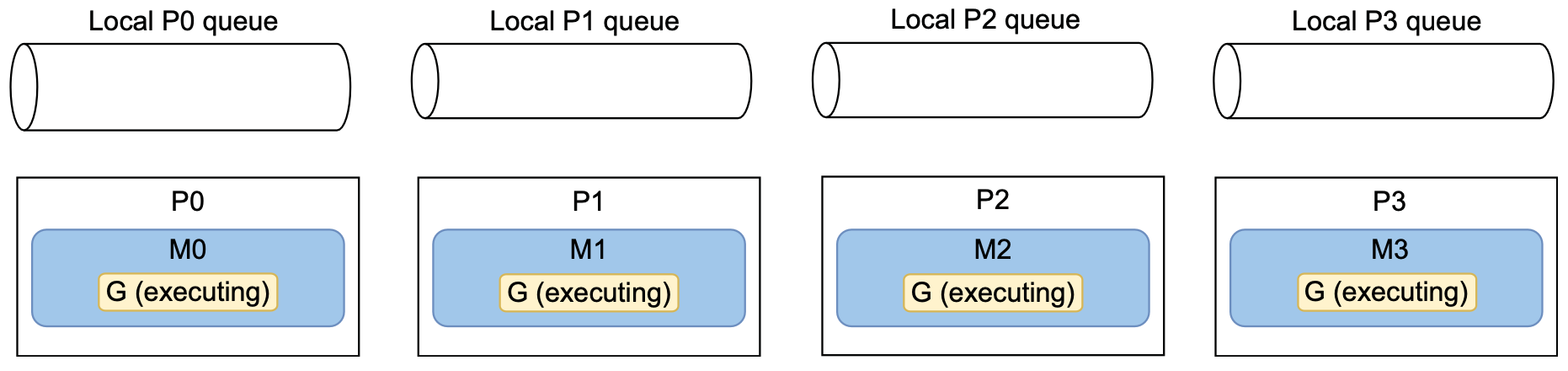
在这里,操作系统调度程序决定将 M2 移动到 P2,将 M3 移动到 P3。同样,无法保证这种情况何时会发生。但是,对于一台仅执行我们的四线程应用程序的机器,这应该是最终的状态。
这种情况下,已然达到最优解了,四个 goroutine 在独立的线程中运行,并且这些线程在独立的CPU上。这种方法减少了在 goroutine 和线程级别上的上下文切换量。
这就是为什么期望goroutine 的数量与 CPU 核心数相同。在 CPU 密集型工作负载的情况下,如果核心数量是 4 个,但我们只有 3 个线程,那么我们应该启动 3 个 goroutine,而不是 4 个。否则,一个线程将在两个 goroutine 之间分配其执行时间,从而增加了上下文切换的次数。
这种最终情况不是我们(Go 开发者)能够设计和要求的。然而,正如我们所看到的,在 CPU 密集型工作负载的情况下,我们可以通过有利的条件来实现它:基于 GOMAXPROCS 创建工作者池。
最佳 goroutine 数量取决于工作负载类型。如果工作者执行的工作负载是 I/O 密集型,该值主要取决于外部系统。相反,如果工作负载是 CPU 密集型,最佳的 goroutine 数量接近可用线程的数量。在设计并发应用程序时,了解工作负载类型(I/O 型还是 CPU 型)至关重要。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









