







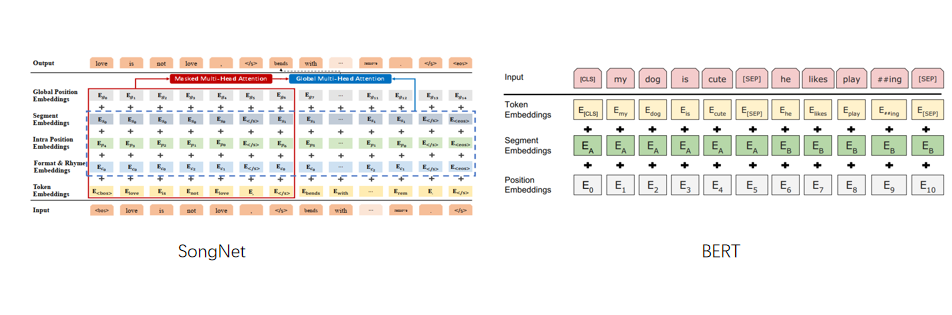
 SongNet是基于BERT的改进模型,用于解决歌词生成的字数可控和押韵问题。它通过将格式信息embedding并利用Mask策略,使BERT具备生成能力,实现了条件文本生成。SongNet的关键特性包括Format and Rhyme Embeddings、Intra-Position Embeddings和Segment Embeddings,这些embedding方法增强了模型对歌词格式的理解和生成效果。
SongNet是基于BERT的改进模型,用于解决歌词生成的字数可控和押韵问题。它通过将格式信息embedding并利用Mask策略,使BERT具备生成能力,实现了条件文本生成。SongNet的关键特性包括Format and Rhyme Embeddings、Intra-Position Embeddings和Segment Embeddings,这些embedding方法增强了模型对歌词格式的理解和生成效果。
歌词生成相较于普通文本生成,需要配合特定的乐曲,并演唱。因而要求,每句歌词演唱的长度正好合拍,即不同曲子,每句歌词的字符个数是要受限制于乐曲。
本文暂不考虑曲配词问题,只是将问题抽象为,在已知歌词每句的字数时,如何生成一个文本,满足字数格式。歌词的押韵没有古诗那么严格,但押韵的歌词朗朗上口,更易演唱,对于歌词生成还是很重要的。总之,歌词生成应当满足两个条件:
(1) 每句的字数可控
(2) 押韵
针对上述两个问题,发表在ACL2020的《Rigid Formats Controlled Text Generation》【1】,可以很好地解决字数可控和押韵问题。该论文将其模型称为SongNet。既可以读作“宋(词)Net”(论文本身是为了生成宋词),又可以读作“Song Net”(歌词网络),一语双关。
1. SongNet简述

SongNet是基于BERT【2】做的改进。相较于BERT,SongNet有如下不同:
将格式信息embedding,输入到模型
通过mask使得BERT具有生成能力
接下来首先介绍,SongNet所属的领域:条件文本生成。
2. 条件文本生成
文本生成领域分为三个部分,自由文本生成(Generic / Free-Text Generation )、条件文本生成(Conditional Text Generation)以及受约束的文本生成(Constrained Text Generation),条件文本生成和受约束的文本生成两者并没有明确的界限,该文将文本生成领域看做两个部分自由文本生成和条件文本生成。【3】
自由文本生成是,没有显式地给出条件的文本生成任务,即只要不是条件文本生成,便是自由文本生成任务。其概率公式如下,
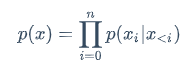
相较于条件文本生成,自由文本生成,只是去建模文本的一个前后依赖。
条件文本生成是,在已知条件情况下,生成满足条件的文本的任务。该任务的概率表示如下,
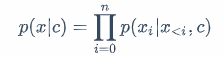
即,模型需要建模一个条件概率,p(x|c),其中c是条件的向量表示,x是单个文本的向量表示,<i表示在第i个时间步之前的文本。
实际情况下,条件文本生成的应用更多,狭义的包括根据主题生成文本、根据情感生成文本,广义的角度来看,机器翻译也可以看做条件文本生成,对于中-英翻译任务,可以看做条件为中文,然后生成英文文本。
例如,生成一个情绪为积极乐观的文本。(文本情绪为积极乐观,即是条件)
条件文本生成的关键在于,如何将条件加入到模型中,常见方法有两种:
将条件进行embedding:无论训练还是生成截断,条件作为输入编码,进行embedding
重加权:在生成阶段,用条件信息重新调整每个时间步下,每个词生成的概率值。
SongNet采用的是第一种方式,将条件进行embedding。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









