







 本文介绍了Dueling DQN和Double DQN,并详细阐述了D3QN(Dueling Double DQN)的算法流程与参数调优。通过结合两者的优点,D3QN在强化学习中能更准确地估算Q值。文章还分享了简单的D3QN代码实现,探讨了网络结构、内存管理、超参数设置等关键环节。
本文介绍了Dueling DQN和Double DQN,并详细阐述了D3QN(Dueling Double DQN)的算法流程与参数调优。通过结合两者的优点,D3QN在强化学习中能更准确地估算Q值。文章还分享了简单的D3QN代码实现,探讨了网络结构、内存管理、超参数设置等关键环节。
本文首发于:行者AI
2016年Google DeepMind提出了Dueling Network Architectures for Deep Reinforcement Learning,采用优势函数advantage function,使Dueling DQN在只收集一个离散动作的数据后,能够更加准确的去估算Q值,选择更加合适的动作。Double DQN,通过目标Q值选择的动作来选择目标Q值,从而消除Q值过高估计的问题。D3QN(Dueling Double DQN)则是结合了Dueling DQN和Double DQN的优点。
1. Dueling DQN
决斗(Dueling)DQN,网络结构如图1所示,图1中上面的网络为传统的DQN网络。图1中下面的网络则是Dueling DQN网络。Dueling DQN网络与传统的DQN网络结构的区别在于Dueling DQN的网络中间隐藏层分别输出value函数 V V V和advantage function优势函数 A A A,通过: Q ( s , a ; θ , α , β ) = V ( s ; θ , β ) + Q(s,a;\theta,\alpha,\beta) = V(s;\theta,\beta) + Q(s,a;θ,α,β)=V(s;θ,β)+ ( A ( s , a ; θ , α ) (A(s,a;\theta,\alpha) (A(s,a;θ,α) - 1 ∣ A ∣ 1 \over |A| ∣A∣1 ∑ A ( s , a ′ ; θ , α ) ) \sum_{} A(s,a′;\theta,\alpha) ) ∑A(s,a′;θ,α))计算出各个动作对应的Q值。
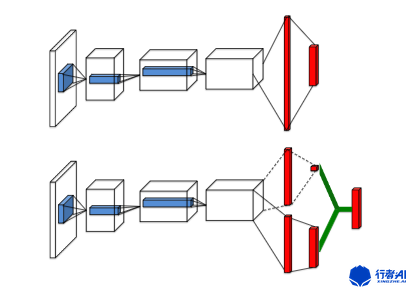
图1. Dueling DQN网络结构
2. D3QN
Double DQN只在DQN的基础上有一点改动,就不在这儿介绍了,如果对DQN还不了解的话,可以戳这里。
2.1 D3QN算法流程
-
初始化当前 Q Q Q网络参数 θ \theta θ,初始化目标 Q ′ Q^′ Q′网络参数 θ ′ \theta^′ θ′,并将 Q Q Q网络参数赋值给 Q ′ Q^′ Q′网络, θ → θ ′ \theta \to \theta^′ θ→θ′,总迭代轮数 T T T,衰减因子 γ \gamma γ,探索率 ϵ \epsilon ϵ,目标Q网络参数更新频率 P P P,每次随机采样的样本数 m m m。
-
初始化replay buffer D D D
-
for t = 1 t = 1 t=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









