









在 Domino 平台上,现有的工作流引擎都有一个比较大的缺点,就是每次工作流的运转都需要从配置库读取配置信息。这好像没什么错误!的确每次流转都要读取配置信息,可以保证每次的流程配置改动都能即时反映到流程引擎中,但是我们可以想想,流程配置修改的频率会有多高那?而工作流引擎将大量的运算用于读取数据、构建工作流引擎对象上,是不是一种资源的浪费那?对于修改并不频繁的流程配置数据来说,能不能将这些数据装入缓存中,然后供流程引擎调用那?
答案是可行的。我们都知道 Domino 数据库是一种文档型数据库,它对数据的检索有多种途径,但是哪种方法似乎都不是特别完美。咱们就这几种方法探讨一下。
第一种,视图检索。
通过视图检索数据,应该还是非常普遍的。但是用视图有个比较大的缺点,视图是静态的,不能在程序中动态指定视图的选择条件。虽然可以用视图的 GetDocumentByKey() 或者 GetAllDocumentsByKey() 方法,但是查询的条件只能限定在某个字段或某几个字段的组合。而且搜索结果受视图索引的制约,有时也不是那么准确。
第二种,公式检索。
这个方法是通过调用 NotesDatabase.dbSearch() 实现的。这个方法较之视图搜索更灵活,开发人员只需要编写搜索公式即可。但是这个方法也有个缺点,如果数据库中文档数量较多,那么查询速度就会让人抓狂了。
第三种,索引检索
这个方法是调用 NotesDatabase.ftsearch() 来实现的,调用这个方法的前提是数据库已经创建了索引。 ftsearch() 的速度是最快的,即使在数据量很大的情况下。但是这个方法仍然有个缺陷,如果索引更新不及时,就查不到最新的数据。而这往往是致命的。
以上三种检索方法跟本篇的主题似乎是有点远。其实不然,在 Domino 平台上,纵观这三种检索方法没有一个完美的。也许这跟文档型数据库的工作原理有关系,但这不在我们的讨论之列。一直以来 Domino 平台上的检索遭人诟病,才逐渐发展出借用关系型数据库来增强 Domino 平台的检索能力,这个问题以后再单起文讨论。只所以把检索的问题提出来,是因为基于 Domino 平台的流程引擎,大量使用了视图检索和公式检索。在一个流程配置库和人员管理库中需要建立大量的视图。这些视图的建立虽然方便了流程引擎的运转,但同时也拖累了系统的运行速度。至于使用索引检索,最大的问题是经常检索不到数据,不用也罢。
现在的问题出现了,为了保证检索结果的准确性,一方面使用公式检索 — 速度慢,一方面使用视图检索 — 不灵活。而且还有个问题是,想同的数据,每次运行代理都得重复检索而不管这块数据有没有更新。浪费,极大地浪费!一个结论呼之欲出:使用数据缓存。
工作流数据缓存的概念肯定别人也想到了,但是从网上查找相关资料却少的可怜。也许这个东西根本不值得一提吧。但是我认为工作流数据缓存还是很有必要的,至少在 Domino 平台上还是有用武之地的。
从本质上将工作流的数据缓存也不是一个多复杂的东西。无非是将工作流引擎需要的数据现行读入内存,然后在工作流引擎工作地时候直接从内存中读取数据。这样做不但减少了对数据库访问次数,而且从内存读取数据的速度要比从数据库中读取数据的速度快太多了。
实现数据缓存我知道的有两种方式,在这里先提前说一句。我知识有限写些东西只是为抛砖引玉。实现缓存的方法一种是利用 HaspMap 键值对的方式在内存中建立映射表,当然关键字只有一个。另外一个方式就是通过 JNDI ,利用 JNDI 的查询机制建立数据映射。我们熟悉的 LDAP 服务其实就是 JNDI 的一个很典型的实例。当然 JNDI 这种方式怎么样,我心里没谱,还是各位看官发表一下意见吧。
对于工作流引擎来说如何想办法快速、高效、准确的找到需要的数据是非常重要的。但是现在大多数流程引擎是直接从数据库中检索数据,前文中也说了这种方式是效率低下的。大家可能没有一个感官上的认识,我们先来看看传统的工作流引擎的工作原理。
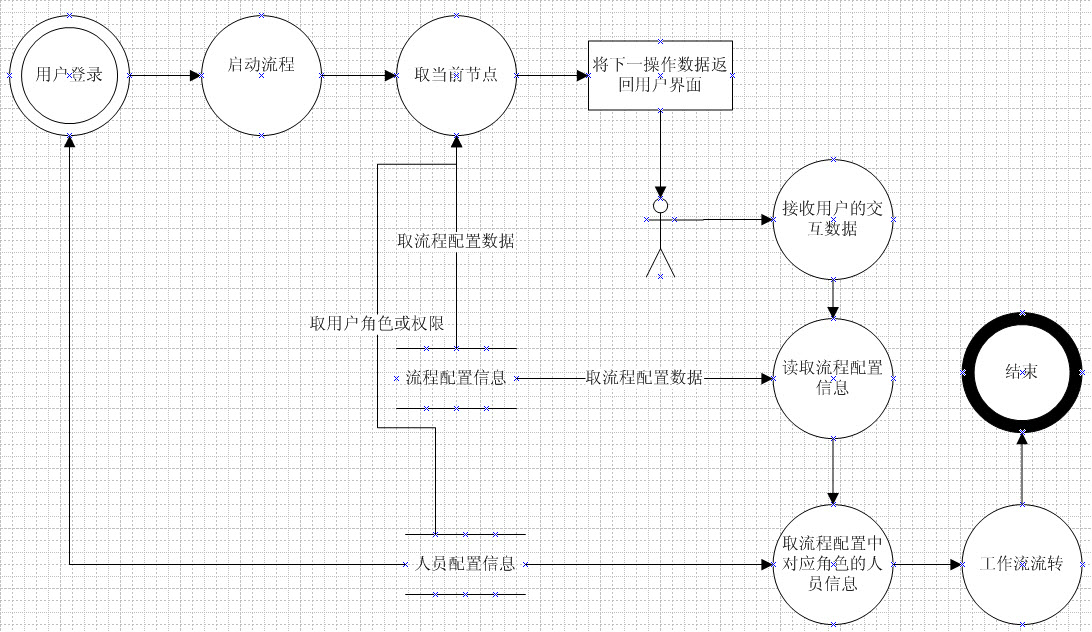
图1
如图1 所示,工作流引擎需要多次从流程配置库中取数据,而且一般的工作流引擎是通过Web 代理方式调用的。Web 代理方式调用的短板就是每次都得重复打开数据库的命令。Domino 是对数据库做了缓存,但是不用打开数据库是不是更快捷那?
缓存的作用是什么?工作流引擎的瓶颈一般也就这么几个方面。一是,引擎设计的好坏。这是先天因素,任何缓存机制都是无用武之地的。二是,读取数据库的次数。次数越少当然越好了。三是,流程配置信息的利用率。每次需要的数据都从数据库读取,那肯定是利用率不高的。四是,业务数据的读写效率。以上问题未必囊括了全部的问题。但在本文中说明问题已经足够了。看到这里我们应该有个原则性的结论,缓存只能是辅助性质的。根本问题还是工作流引擎的设计优劣。当然这不在本文的讨论之列。
根据图 1 所示,将工作流引擎结合缓存机制后会是什么情况那?看一下下图 ( 图 2) 。
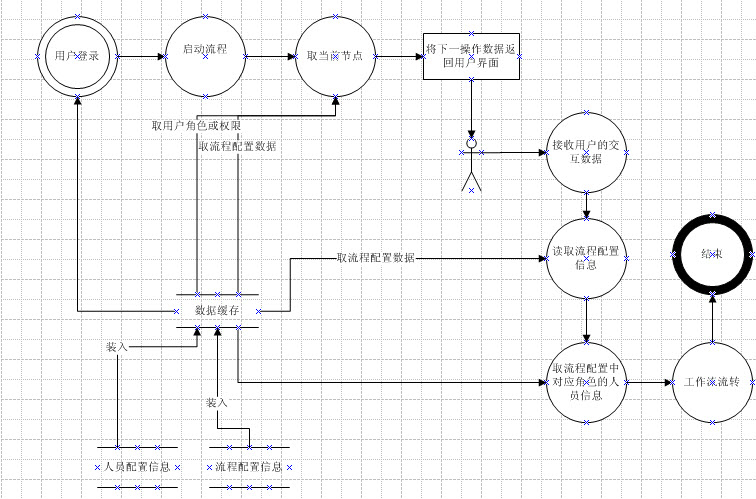
图2
将图 2 中工作流引擎指向数据库的连接全部改成指向数据缓存,即工作流引擎从缓存中取数据。而缓存则从数据库中取数据。一个问题又浮出水面了。从数据库读取信息到缓存中有两种方式。一种是预读取,一种是后读取。这个怎么讲那?听某慢慢道来。
所谓预读取就是事先将数据库中的配置数据读取到内存中。这样做的好处是每次工作流引擎访问缓存,不需要等待。缺点是启动之初需要取大量的数据。这种方式比较浪费资源。后读取的方式是工作流引擎第一次访问缓存时,缓存服务从数据库中读取数据,放入缓存,然后返回给工作流引擎。这样做的好处是没有资源浪费的现象,所有的缓存数据都是用到的。当然缺点也是明显的,那就是流程引擎初次访问的速度会慢一些。 <!-- /* Font Definitions */ @font-face {font-family:宋体; panose-1:2 1 6 0 3 1 1 1 1 1; mso-font-alt:SimSun; mso-font-charset:134; mso-generic-font-family:auto; mso-font-pitch:variable; mso-font-signature:3 135135232 16 0 262145 0;} @font-face {font-family:"Cambria Math"; panose-1:2 4 5 3 5 4 6 3 2 4; mso-font-charset:0; mso-generic-font-family:roman; mso-font-pitch:variable; mso-font-signature:-1610611985 1107304683 0 0 159 0;} @font-face {font-family:Calibri; panose-1:2 15 5 2 2 2 4 3 2 4; mso-font-charset:0; mso-generic-font-family:swiss; mso-font-pitch:variable; mso-font-signature:-1610611985 1073750139 0 0 159 0;} @font-face {font-family:"/@宋体"; panose-1:2 1 6 0 3 1 1 1 1 1; mso-font-charset:134; mso-generic-font-family:auto; mso-font-pitch:variable; mso-font-signature:3 135135232 16 0 262145 0;} /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {mso-style-unhide:no; mso-style-qformat:yes; mso-style-parent:""; margin:0cm; margin-bottom:.0001pt; text-align:justify; text-justify:inter-ideograph; mso-pagination:none; font-size:10.5pt; mso-bidi-font-size:11.0pt; font-family:"Calibri","sans-serif"; mso-fareast-font-family:宋体; mso-bidi-font-family:"Times New Roman"; mso-font-kerning:1.0pt;} .MsoChpDefault {mso-style-type:export-only; mso-default-props:yes; font-size:10.0pt; mso-ansi-font-size:10.0pt; mso-bidi-font-size:10.0pt; mso-ascii-font-family:Calibri; mso-fareast-font-family:宋体; mso-hansi-font-family:Calibri; mso-font-kerning:0pt;} /* Page Definitions */ @page {mso-page-border-surround-header:no; mso-page-border-surround-footer:no;} @page Section1 {size:595.3pt 841.9pt; margin:72.0pt 90.0pt 72.0pt 90.0pt; mso-header-margin:42.55pt; mso-footer-margin:49.6pt; mso-paper-source:0; layout-grid:15.6pt;} div.Section1 {page:Section1;} -->
对于缓存类程序来说,还有个相当重要的问题 , 那就是缓存的更新。众所周知,缓存的更新一般都是一个比较难处理的问题。主要原因在于缓存的数据什么时候更新,更新哪些数据。解决这个问题前,我们先来看看作为支撑工作流引擎的两种基础数据的变化情况。
第一种,组织机构数据。这些数据的变化频率应该是比较高的。第二种,流程配置数据。这类数据变化的频率就没那么频繁了。这两种数据都有一个共同的特点,数据的修改时没有任何规律可循的。那么作为这两种数据的缓存,事件触发的更新机制应该是最合适不过的了。但是事件驱动对 Domino 来说似乎有点难度。我们都知道, Domino 中的代理有个属性“所有新建及修改过得文档”,通过这个属性可以取到所有编辑过的文档。但是,代理运行的间隔时间是在 30 分钟,这个时间间隔还是比较长的。除此之外没有其他途径允许我们能够实时监控文档的事件了。这真是个棘手的问题。
有一个办法可以实现类似事件监控。也许这个方法比较笨,没办法,笨人用笨方法。那就是在保存、删除文档时,都记录一个事件动作,然后记录一个 ID 值,这个值需要与缓存中的数据一一对应。然后缓存循环读取这些个数据,根据事件的动作,采取相应的动作。比如更新数据、删除数据。具体的字段则在缓存规则配置里配置好即可。上面这个方法不见得是个好方法,仅为大家提供一种思路。希望能起到抛砖引玉的作用。

















 214
214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









