






一、pom.xml文件
<!--中文分词-->
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>二、Dic字典文件
※关注微信公众号:搜题网
※回复关键词:dic
※免费获取分词字典文件
![]()
三、DTO类文件
package com.sulei.dto;
/**
* @Description:
* @Author sulei
* @Date 2021/12/16 16:02
*/
public class Keyword implements Comparable<Keyword>{
/**
* tfidfvalue
*/
private double tfidfvalue;
/**
* name
*/
private String name;
public Keyword(String name, double tfidfvalue) {
this.name = name;
// tfidf值只保留3位小数
this.tfidfvalue = (double) Math.round(tfidfvalue * 10000) / 10000;
}
public double getTfidfvalue() {
return tfidfvalue;
}
public void setTfidfvalue(double tfidfvalue) {
this.tfidfvalue = tfidfvalue;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* 为了在返回tdidf分析结果时,可以按照值的从大到小顺序返回,故实现Comparable接口
*/
@Override
public int compareTo(Keyword o) {
if (this.tfidfvalue - o.tfidfvalue > 0) {
return -1;
} else if (this.tfidfvalue - o.tfidfvalue < 0) {
return 1;
} else {
return 0;
}
//return this.tfidfvalue-o.tfidfvalue>0?-1:1;
}
/**
* 重写hashcode方法,计算方式与原生String的方法相同
*/
@Override
public int hashCode() {
final int PRIME = 31;
int result = 1;
result = PRIME * result + ((name == null) ? 0 : name.hashCode());
long temp;
temp = Double.doubleToLongBits(tfidfvalue);
result = PRIME * result + (int) (temp ^ (temp >>> 32));
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
Keyword other = (Keyword) obj;
if (name == null) {
if (other.name != null) {
return false;
}
} else if (!name.equals(other.name)) {
return false;
}
return true;
}
}
package com.sulei.dto;
import com.huaban.analysis.jieba.JiebaSegmenter;
import lombok.extern.slf4j.Slf4j;
import org.springframework.core.io.ClassPathResource;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.*;
/**
* @Description:
* @Author sulei
* @Date 2021/12/16 16:03
*/
@Slf4j
public class TfIdfAnalyzer {
/**
* idfMap集合
*/
static HashMap<String, Double> idfMap;
/**
* 停止词集合
*/
static HashSet<String> stopWordsSet;
/**
* idfMedian
*/
static double idfMedian;
/**
*
* 功能描述: tfidf分析方法
*
* @param content 需要分析的文本/文档内容
* @param top 需要返回的tfidf值最高的N个关键词,若超过content本身含有的词语上限数目,则默认返回全部
* @return 关键词
* @auther: lizongke
* @date: 2020/1/13 9:58
*/
public List<Keyword> analyze(String content, int top) {
List<Keyword> keywordList = new ArrayList<>();
try {
if (stopWordsSet == null) {
stopWordsSet = new HashSet<>();
ClassPathResource classPathResource = new ClassPathResource("dic/stop_words.txt");
InputStream inputStream = classPathResource.getInputStream();
loadStopWords(stopWordsSet, inputStream);
//loadStopWords(stopWordsSet, this.getClass().getResourceAsStream("stop_words.txt"));
}
if (idfMap == null) {
idfMap = new HashMap<>();
loadIdfMap(idfMap, new ClassPathResource("dic/idf_dict.txt").getInputStream());
//loadIDFMap(idfMap, this.getClass().getResourceAsStream("idf_dict.txt"));
}
} catch (Exception e) {
log.info(e.toString());
}
Map<String, Double> tfMap = getTf(content);
for (String word : tfMap.keySet()) {
// 若该词不在idf文档中,则使用平均的idf值(可能定期需要对新出现的网络词语进行纳入)
if (idfMap.containsKey(word)) {
keywordList.add(new Keyword(word, idfMap.get(word) * tfMap.get(word)));
} else {
keywordList.add(new Keyword(word, idfMedian * tfMap.get(word)));
}
}
Collections.sort(keywordList);
if (keywordList.size() > top) {
int num = keywordList.size() - top;
for (int i = 0; i < num; i++) {
keywordList.remove(top);
}
}
return keywordList;
}
/**
*
* 功能描述: tf值计算公式 tf=N(i,j)/(sum(N(k,j) for all k))
* N(i,j)表示词语Ni在该文档d(content)中出现的频率,sum(N(k,j))代表所有词语在文档d中出现的频率之和
*
* @param content 待分析文本
* @return tf集合
* @auther: lizongke
* @date: 2020/1/13 10:09
*/
private Map<String, Double> getTf(String content) {
Map<String, Double> tfMap = new HashMap<>();
if (content == null || "".equals(content)) {
return tfMap;
}
JiebaSegmenter segmenter = new JiebaSegmenter();
List<String> segments = segmenter.sentenceProcess(content);
Map<String, Integer> freqMap = new HashMap<>();
int wordSum = 0;
for (String segment : segments) {
//停用词不予考虑,单字词不予考虑
if (!stopWordsSet.contains(segment) && segment.length() > 1) {
wordSum++;
if (freqMap.containsKey(segment)) {
freqMap.put(segment, freqMap.get(segment) + 1);
} else {
freqMap.put(segment, 1);
}
}
}
// 计算double型的tf值
for (String word : freqMap.keySet()) {
tfMap.put(word, freqMap.get(word) * 0.1 / wordSum);
}
return tfMap;
}
/**
* 默认jieba分词的停词表
* url:https://github.com/yanyiwu/nodejieba/blob/master/dict/stop_words.utf8
*
* @param set 停止词集合
* @param in 停止词输入流
*/
private void loadStopWords(Set<String> set, InputStream in) {
BufferedReader bufr;
try {
bufr = new BufferedReader(new InputStreamReader(in));
String line = null;
while ((line = bufr.readLine()) != null) {
set.add(line.trim());
}
try {
bufr.close();
} catch (IOException e) {
log.info(e.toString());
}
} catch (Exception e) {
log.info(e.toString());
}
}
/**
* idf值本来需要语料库来自己按照公式进行计算,不过jieba分词已经提供了一份很好的idf字典,所以默认直接使用jieba分词的idf字典
* url:https://raw.githubusercontent.com/yanyiwu/nodejieba/master/dict/idf.utf8
*
* @param map idf集合
* @param in idf输入流
*/
private void loadIdfMap(Map<String, Double> map, InputStream in) {
BufferedReader bufr;
try {
bufr = new BufferedReader(new InputStreamReader(in));
String line = null;
while ((line = bufr.readLine()) != null) {
String[] kv = line.trim().split(" ");
map.put(kv[0], Double.parseDouble(kv[1]));
}
try {
bufr.close();
} catch (IOException e) {
log.info(e.toString());
}
// 计算idf值的中位数
List<Double> idfList = new ArrayList<>(map.values());
Collections.sort(idfList);
idfMedian = idfList.get(idfList.size() / 2);
} catch (Exception e) {
log.info(e.toString());
}
}
}
四、接口类、实现类
package com.sulei.service;
import java.util.List;
public interface FenciService {
List<String> keywords(String content,int top) throws Exception;
}
package com.sulei.service.Impl;
import com.sulei.dto.Keyword;
import com.sulei.dto.TfIdfAnalyzer;
import com.sulei.service.FenciService;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
/**
* @Description:
* @Author sulei
* @Date 2021/12/16 16:08
*/
@Service
public class FenciServiceImpl implements FenciService {
@Override
public List<String> keywords(String content,int top) throws Exception {
//去除空格和特殊字符
String regEx = "[\n\r\t`~!@#$%^&*()+=|{}':;',\\[\\].<>/?~!@#¥%……&*()——+|{}【】‘;:”“’。, 、?^p\\\"\\\"-_]";
String aa = "";
content = content.replaceAll(regEx, aa).replaceAll(" ", "").replaceAll(" ", "");
List<String> keywords = new ArrayList<>();
//提取10个关键词
TfIdfAnalyzer tfIdfAnalyzer = new TfIdfAnalyzer();
List<Keyword> list = tfIdfAnalyzer.analyze(content, top);
for (Keyword word : list) {
keywords.add(word.getName());
}
return keywords;
}
}
五、controller使用
@Autowired
private FenciService fenciService;
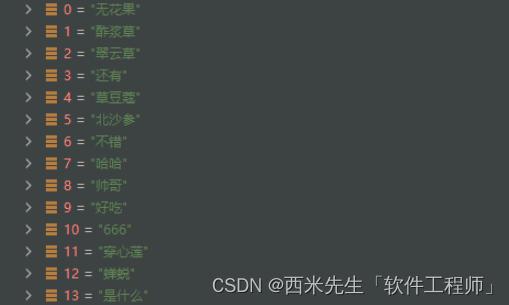
List<String> keywords = fenciService.keywords("哈哈无花果翠云草酢浆草是什么,。我是帅哥666无花果真好吃还有北沙参穿心莲翠云草,草豆蔻和蝉蜕酢浆草也不错的", 20);
StringBuilder stringBuilder=new StringBuilder();
for(String s:keywords){
stringBuilder.append(s).append("、");
}
















 2867
2867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











