







目录
1、读写分离的实现形式
1.1、mysql-proxy方式实现
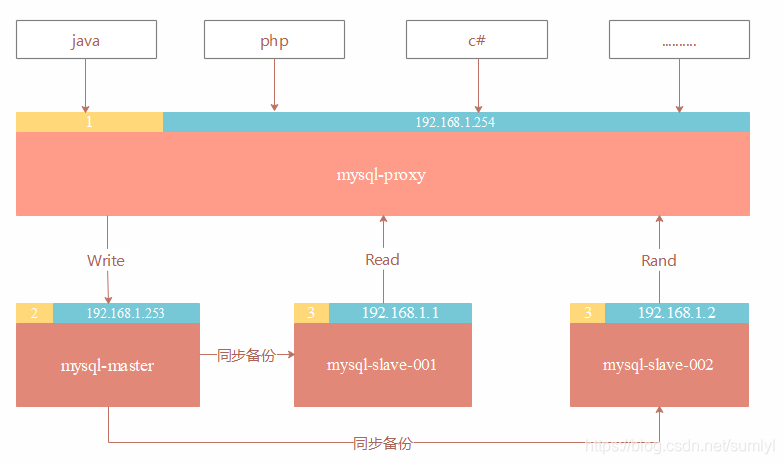
优点:实现简单,在独立的机器安装mysql-proxy,直接实现读写分离和负载均衡,不用项目修改代码,支持多语言。通过mysql-proxy去访问master和slave。
缺点:字符集问题,lua语言编程,还只是alpha版本, 由中间件做了中转代理, 切换数据库变得困难,性能有所下降,时间消耗有点高。
参考:https://www.jianshu.com/p/552b1307dd22
网络拓扑图如下:
1.2、Sharding-Sphere分布式是数据中间件
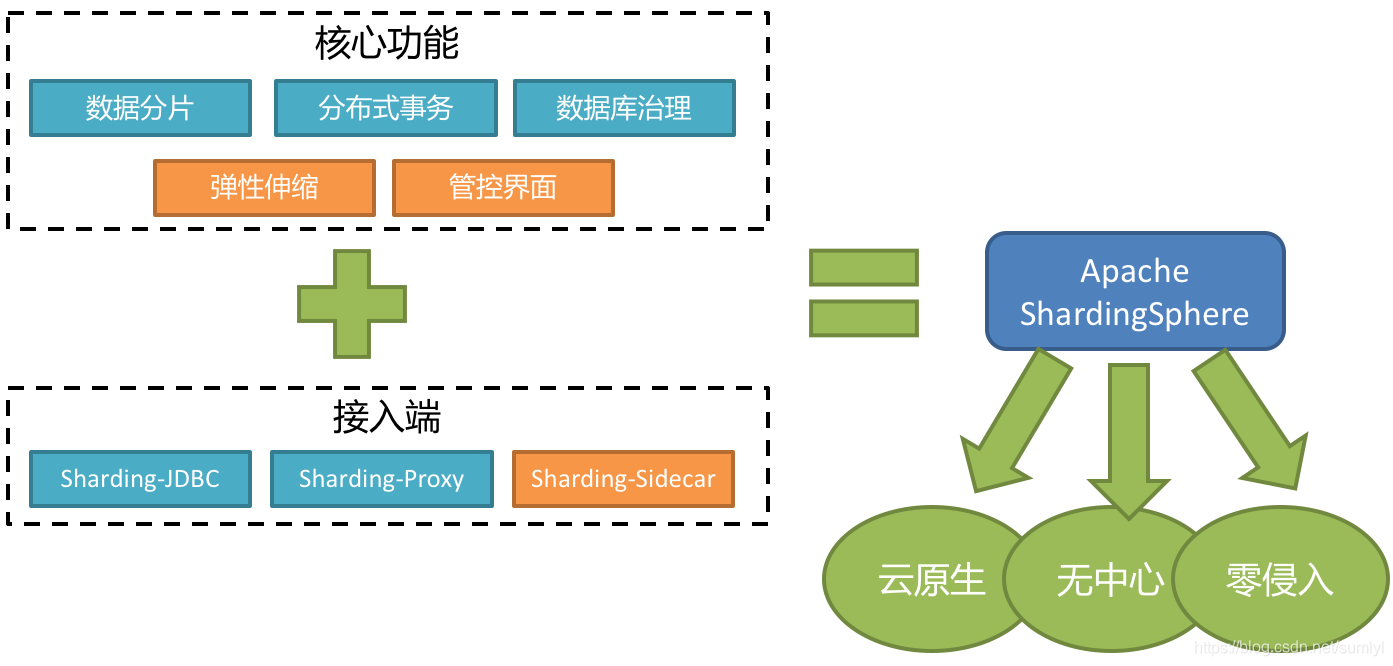
Sharding-Sphere包含了3个产品,分别是 Sharding-JDBC、 Sharding-Proxy、 Sharding-Sidecar。
本文主要介绍Sharding-JDBC,它就是Sharding-Sphere的前身。
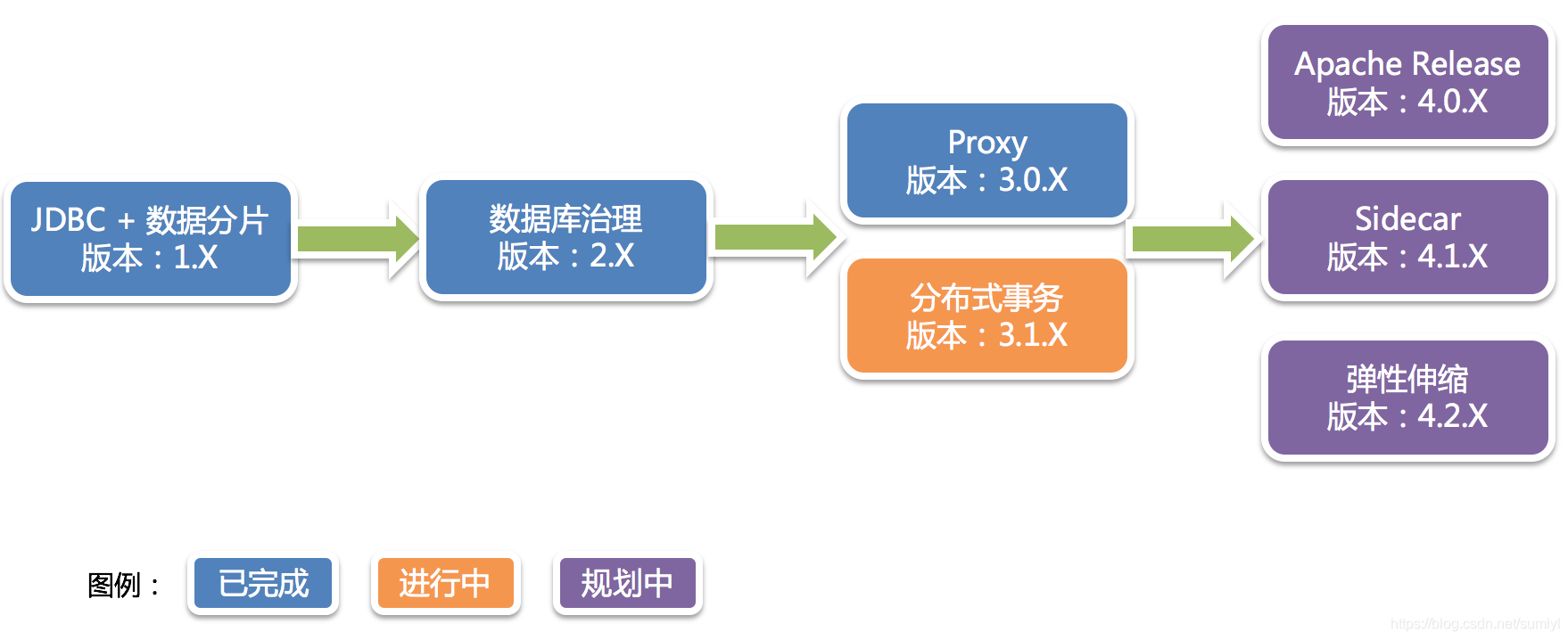
发展线路图如下:
 Sharding-Sphere核心功能图:
Sharding-Sphere核心功能图:
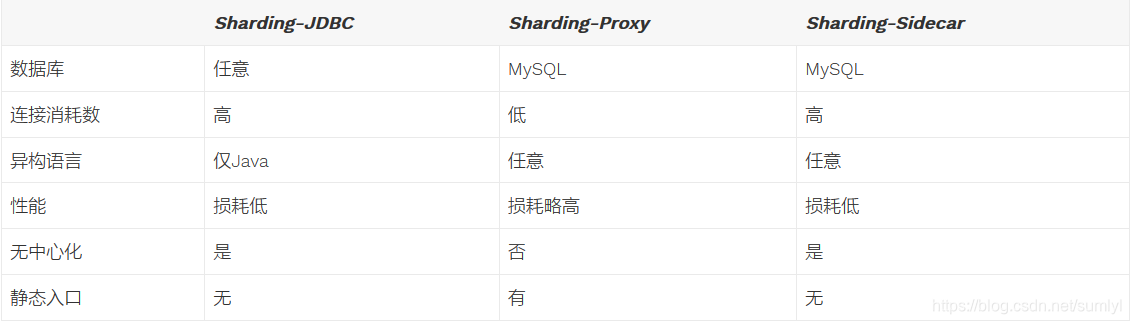 优点:
优点:
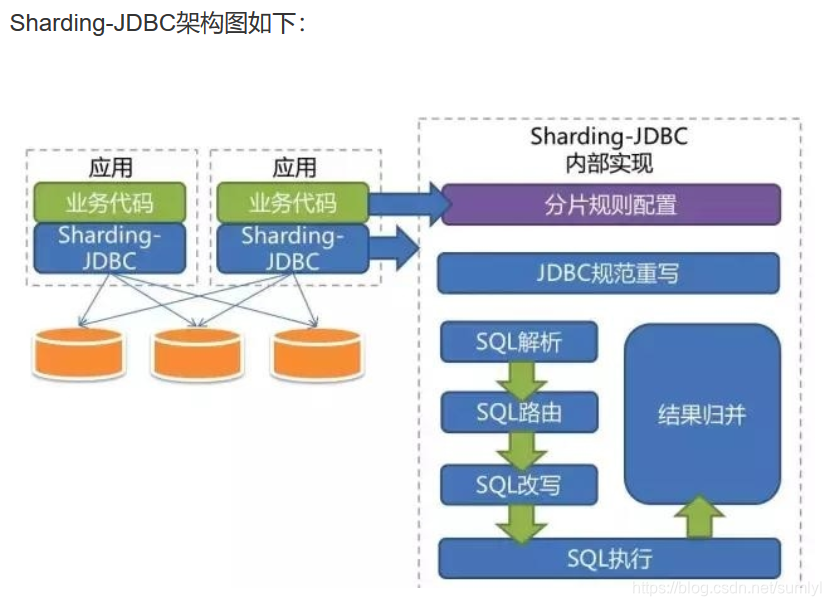
Sharding-JDBC 采用在 JDBC 层扩展分库分表,支持读写分离,是一个以 jar 形式提供服务的轻量级组件,其核心思路是小而美地完成最核心的事情,基于 JDBC 层进行分片的好处是轻量、简单、兼容性好以及无需额外的运维工作。 Sharding-JDBC是对原生的JDBC基础上做扩展,是增强版的JDBC,所以性能上损失很小。
引用官网的话总结如下:
① Sharding-JDBC是一个开源的分布式数据库中间件解决方案。它在Java的JDBC层以对业务应用零侵入的方式额外提供数据分片,读写分离,柔性事务和分布式治理能力。并在其基础上提供封装了MySQL协议的服务端版本,用于完成对异构语言的支持。
② Sharding-JDBC是基于JDBC的客户端版本定位为轻量级Java框架,使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
③ Sharding-JDBC封装了MySQL协议的服务端版本定位为透明化的MySQL代理端,可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
缺点:
由程序员完成,运维参与不到,无法跨语言,目前仅支持 Java。
参考:认识Sharding-JDBC,中文官网,ShardingJdbc项目地址,使用ShardingJdbc应对大数据量的案例
Sharding-JDBC配置依赖
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>3.0.0</version>
</dependency>
Sharding-JDBC配置规则
配置是整个Sharding-JDBC的核心,是Sharding-JDBC中唯一与应用开发者打交道的模块。配置模块也是Sharding-JDBC的门户,通过它可以快速清晰的理解Sharding-JDBC所提供的功能。
本部分是Sharding-JDBC的配置参考手册,需要时可当做字典查阅。
Sharding-JDBC提供了4种配置方式,用于不同的使用场景。通过配置,应用开发者可以灵活的使用分库分表、读写分离以及分库分表 + 读写分离共用。
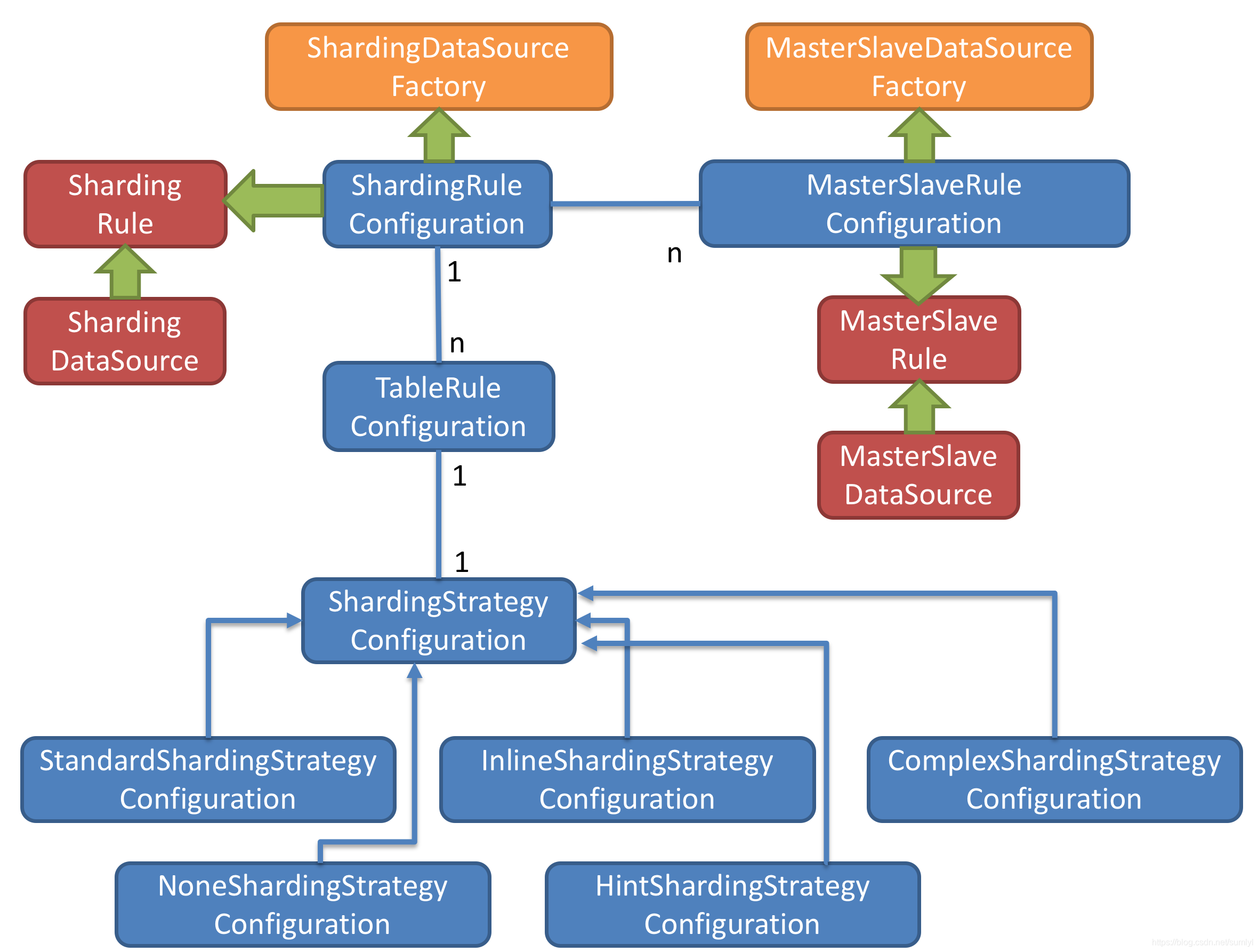
工厂方法API
图中黄色部分表示的是Sharding-JDBC的入口API,采用工厂方法的形式提供。 目前有ShardingDataSourceFactory和MasterSlaveDataSourceFactory两个工厂类。ShardingDataSourceFactory用于创建分库分表或分库分表+读写分离的JDBC驱动,MasterSlaveDataSourceFactory用于创建独立使用读写分离的JDBC驱动。
配置对象
图中蓝色部分表示的是Sharding-JDBC的配置对象,提供灵活多变的配置方式。 ShardingRuleConfiguration是分库分表配置的核心和入口,它可以包含多个TableRuleConfiguration和MasterSlaveRuleConfiguration。每一组相同规则分片的表配置一个TableRuleConfiguration。如果需要分库分表和读写分离共同使用,每一个读写分离的逻辑库配置一个MasterSlaveRuleConfiguration。 每个TableRuleConfiguration对应一个ShardingStrategyConfiguration,它有5中实现类可供选择。
仅读写分离使用MasterSlaveRuleConfiguration即可。
内部对象
图中红色部分表示的是内部对象,由Sharding-JDBC内部使用,应用开发者无需关注。Sharding-JDBC通过ShardingRuleConfiguration和MasterSlaveRuleConfiguration生成真正供ShardingDataSource和MasterSlaveDataSource使用的规则对象。ShardingDataSource和MasterSlaveDataSource实现了DataSource接口,是JDBC的完整实现方案。
初始化流程
- 配置Configuration对象。
- 通过Factory对象将Configuration对象转化为Rule对象。
- 通过Factory对象将Rule对象与DataSource对象装配。
- Sharding-JDBC使用DataSource对象进行分库。

分库分表为了解决一个问题,引入了很多成本,从长久看这种方案会逐步被新的解决方案替代。目前看来,解决的思路主要分为两个方向:
- 第一个思路既然分库的原动力主要是单实例的写入容量限制,那么我们可以最大程度地提升整个写入容量,云计算的发展为这种思路提供了新的可能,以 AWS Aurora 为代表 RDS ,它以 Log is database 为理念,将复杂的随机写入简化为顺序写的 Log,并通过将计算与存储分离,把复杂的数据持久化、一致性、数据合并都扔给一个高可用的共享存储系统来完成,进而打开写入的天花板,将昂贵的写入容量提升一个量级;
- 第二种思路承认分片的必要性,将这种分片的策略集成到一套整体的分布式数据库体系中,同时通过 Paxos/Raft 复制协议加上多实例节点来实现数据强一致的高可用,其中代表产品有 Google 的 Spanner&F1、TiDB(https://github.com/pingcap/tidb)、CockRoachDB(https://github.com/cockroachdb/cockroach) 等,是比较理想的 Sharding + Proxy 的替代方案。
2、项目源码
项目源码Dome参考:https://gitee.com/sunlx/qxl-sharding














 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









