







1.问题原因
查询kudu库的数据是基于impala查询的,有一列的数据是a;b;c这样的数据,需要转化的多行。
将数据导入hive,用explode函数效率比较低
2.问题解决
利用 cross join 实现笛卡尔集,然后过滤掉多余的数据。可以实现需求
3.具体操作
with A as (select 'row 1' as key, 'a;b;c' as value
union all
select 'row 2' as key, 'd;e' as value
union all
select 'row 3' as key, 'f' as value),
B as (select *, length(value) - length(regexp_replace(value,';','')) + 1 as n from A),
-- assuming you have at lest as many rows as different values in a single row
C as (select row_number() over(order by key) as seq, n from B),
D as (select seq from C where seq <= (select max(n) from C))
select key, value, split_part(value,';',seq) as part
from B
cross join D
where seq <= n
order by key,seq
- A表原始数据
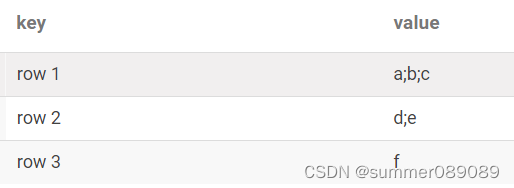
- B表数据,主要是为了求出对应的value值,有几个元素
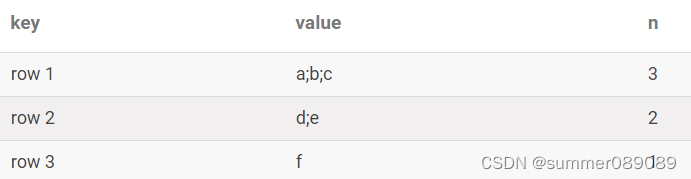
- C表加上D表主要是为了1到最大元素个数的一个序列。不这样生成也行,直接通过union all也可以

- 最后结果通过 cross join 联合去除各个元素的数据,过滤掉 seq <= n 取不到的数据
















 688
688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









