构建df
import pandas as pd
df = pd.DataFrame(
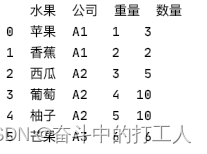
{'水果': ['苹果', '香蕉', '西瓜', '葡萄', '柚子', '芒果'], '公司': ['A1', 'A1', 'A2', 'A2', 'A2', 'A3'], '重量': [1, 2, 3, 4, 5, 6],
'数量': [3, 2, 5, 10, 10, 6]})
df结构
按公司分组,然后求出数量字段最大值所在的行
print(df.iloc[df.groupby(['公司']).apply(lambda x: x['数量'].idxmax())])
效果

代码汇总
import pandas as pd
df = pd.DataFrame(
{'水果': ['苹果', '香蕉', '西瓜', '葡萄', '柚子', '芒果'], '公司': ['A1', 'A1', 'A2', 'A2', 'A2', 'A3'], '重量': [1, 2, 3, 4, 5, 6],
'数量': [3, 2, 5, 10, 10, 6]})
print(df.iloc[df.groupby(['公司']).apply(lambda x: x['数量'].idxmax())])
























 4709
4709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











