







Python绘制克利夫兰点图:从入门到实战
引言
克利夫兰点图(Cleveland Dot Plot)是一种强大的数据可视化工具,由统计学家William Cleveland在1984年提出。这种图表特别适合展示多个类别的数值比较,比传统的条形图更直观、更精确。本文将详细介绍如何使用Python创建克利夫兰点图,从基础概念到实际应用。
什么是克利夫兰点图?
克利夫兰点图是一种简洁而有效的数据可视化方式,它通过点和水平线的组合来展示数据。每个数据点都通过一条水平线连接到坐标轴,使得数据之间的比较更加直观。
主要特点:
- 使用点和水平线展示数据
- 适合展示多个类别的数值比较
- 数据排序后更容易观察趋势
- 支持多数据系列的对比展示
环境准备
在开始之前,我们需要安装必要的Python库:
pip install matplotlib seaborn pandas numpy
代码实现
让我们通过实际的例子来学习如何创建克利夫兰点图。我们将使用matplotlib和seaborn来实现这个可视化效果。
1. 基础设置
首先,我们需要导入必要的库并设置中文字体支持:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
2. 准备数据
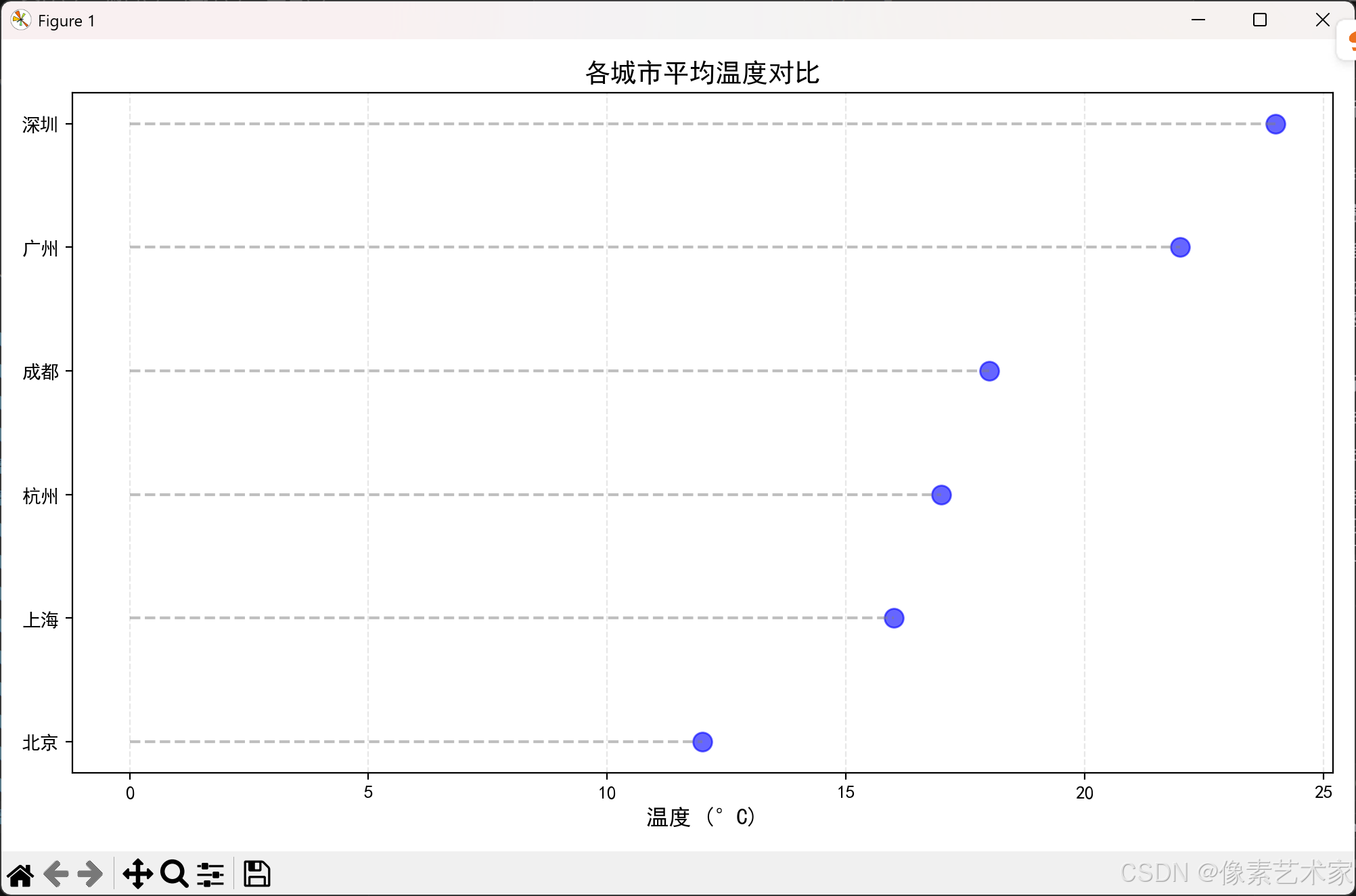
在我们的示例中,我们使用城市温度数据来展示克利夫兰点图的效果:
# 示例数据:不同城市的平均温度
cities = ['北京', '上海', '广州', '深圳', '成都', '杭州']
temperatures = [12, 16, 22, 24, 18, 17]
# 创建DataFrame
df = pd.DataFrame({
'城市': cities,
'温度': temperatures
})
# 按温度排序
df = df.sort_values('温度')
3. 创建基础点图
使用matplotlib创建基础克利夫兰点图:
# 创建图形
plt.figure(figsize=(10, 6))
# 绘制点
plt.scatter(df['温度'], range(len(df)), s=100, color='blue', alpha=0.6)
# 添加水平线
for i, temp in enumerate(df['温度']):
plt.hlines(i, 0, temp, colors='gray', linestyles='--', alpha=0.5)
# 设置y轴标签
plt.yticks(range(len(df)), df['城市'])
# 添加标题和标签
plt.title('各城市平均温度对比', fontsize=14)
plt.xlabel('温度 (°C)', fontsize=12)
# 添加网格线
plt.grid(True, axis='x', linestyle='--', alpha=0.3)
实际应用场景
克利夫兰点图在以下场景特别有用:
- 数据对比:比较不同类别之间的数值差异
- 趋势分析:展示数据的变化趋势
- 多维度分析:同时展示多个指标
- 时间序列对比:比较不同时间点的数据
进阶技巧
1. 多数据系列对比
可以同时展示多个数据系列:
# 创建更复杂的示例数据
categories = ['产品A', '产品B', '产品C', '产品D', '产品E']
sales_2022 = [120, 85, 150, 95, 110]
sales_2023 = [140, 95, 160, 105, 130]
# 创建DataFrame
df = pd.DataFrame({
'类别': categories,
'2022年': sales_2022,
'2023年': sales_2023
})
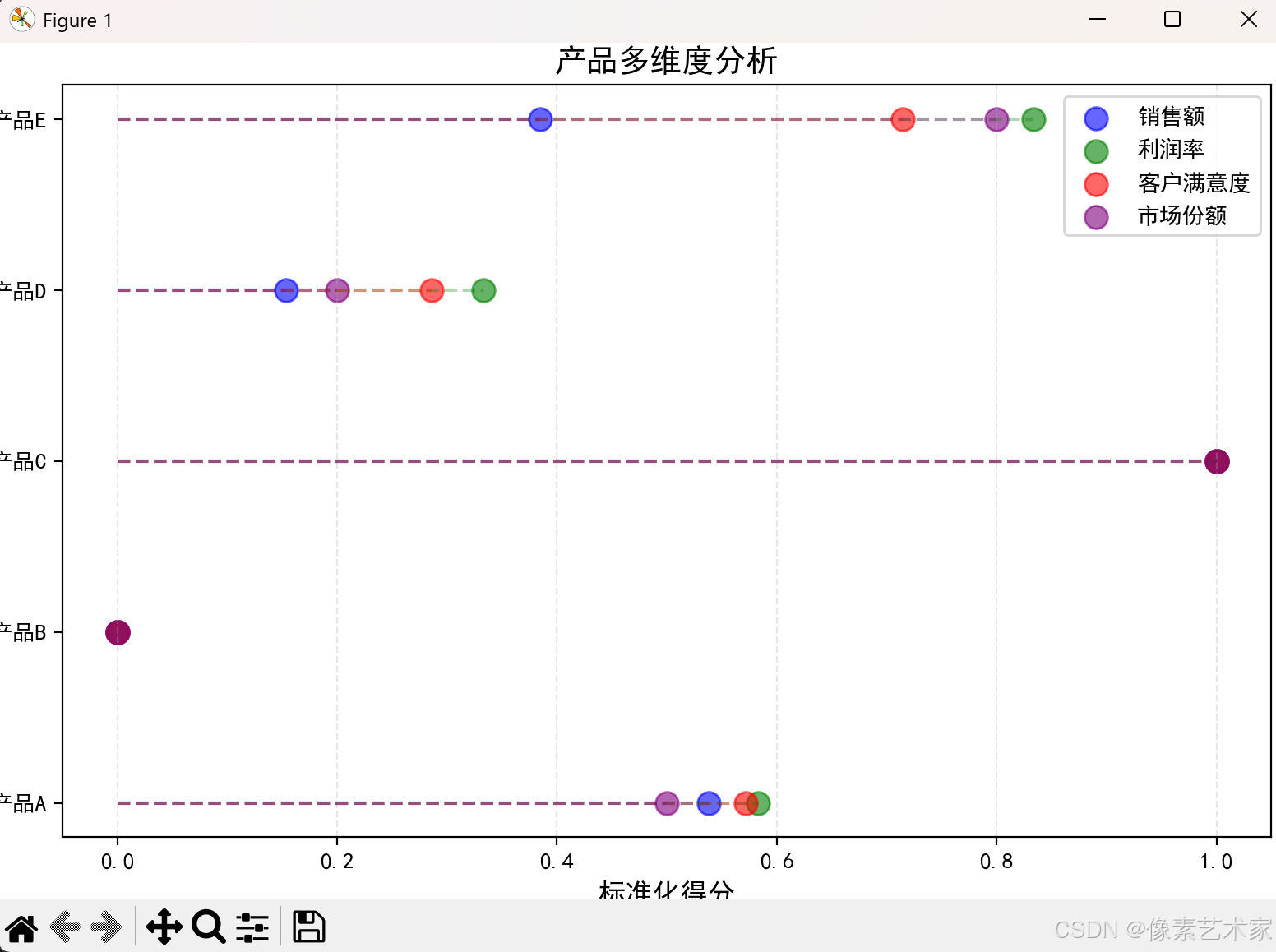
2. 多维度分析
展示产品的多个指标:
# 创建业务数据
products = ['产品A', '产品B', '产品C', '产品D', '产品E']
metrics = {
'销售额': [120, 85, 150, 95, 110],
'利润率': [25, 18, 30, 22, 28],
'客户满意度': [4.2, 3.8, 4.5, 4.0, 4.3],
'市场份额': [15, 10, 20, 12, 18]
}
3. 自定义样式
可以通过修改各种参数来优化图表外观:
# 设置颜色
colors = ['blue', 'green', 'red', 'purple']
# 设置透明度
alpha = 0.6
# 设置点的大小
s = 100
# 设置网格线样式
plt.grid(True, axis='x', linestyle='--', alpha=0.3)
多数据序列演示
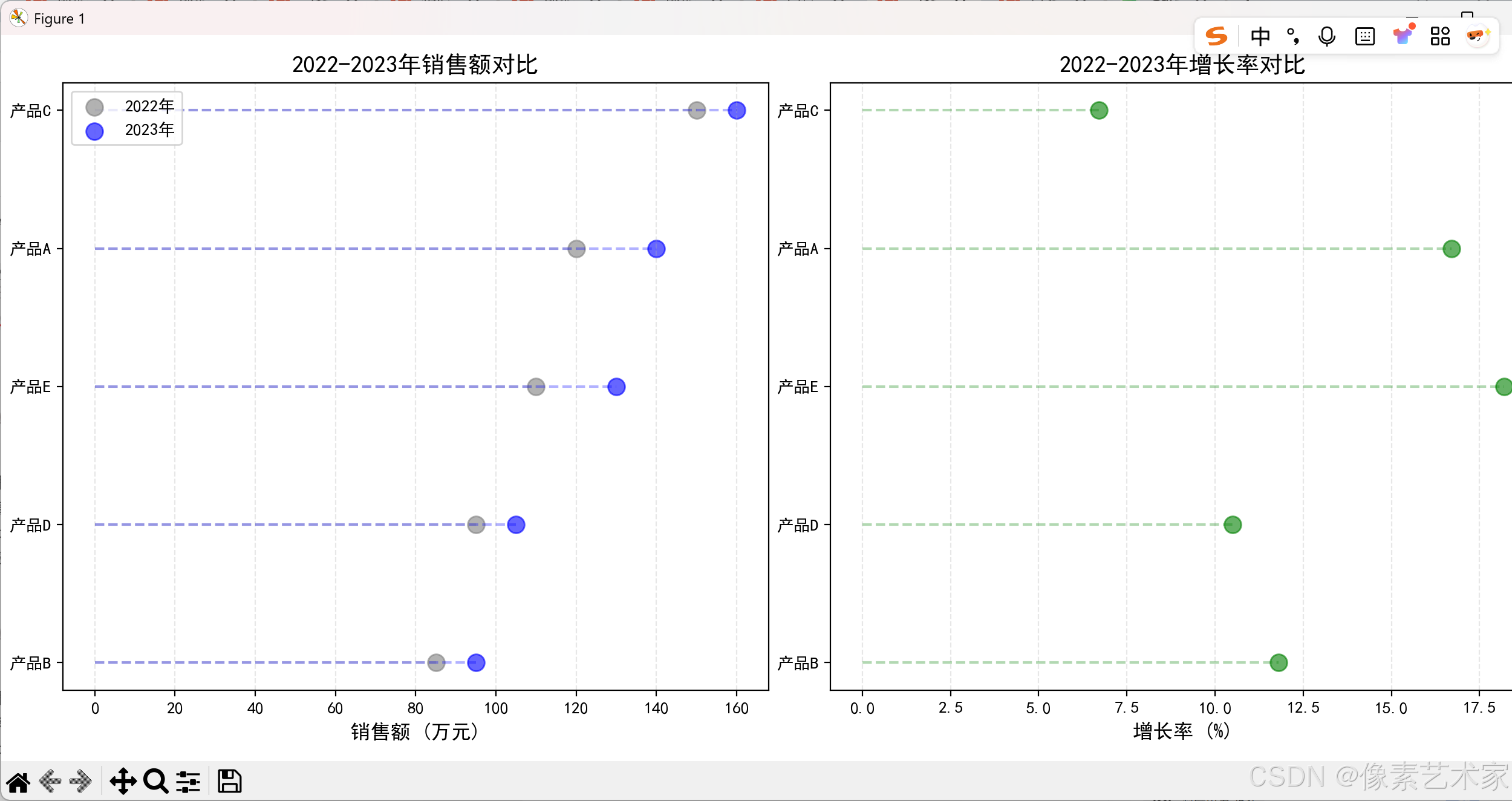
让我们通过一个实际的例子来展示如何使用克利夫兰点图比较多个数据序列。这个例子将展示不同产品在2022年和2023年的销售数据对比。
1. 数据准备
# 创建示例数据
categories = ['产品A', '产品B', '产品C', '产品D', '产品E']
sales_2022 = [120, 85, 150, 95, 110]
sales_2023 = [140, 95, 160, 105, 130]
# 创建DataFrame
df = pd.DataFrame({
'类别': categories,
'2022年': sales_2022,
'2023年': sales_2023
})
# 计算增长率
df['增长率'] = ((df['2023年'] - df['2022年']) / df['2022年'] * 100).round(1)
# 按2023年销售额排序
df = df.sort_values('2023年')
2. 创建双图表对比
# 创建图形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 绘制销售额对比图
for year, color in zip(['2022年', '2023年'], ['gray', 'blue']):
ax1.scatter(df[year], range(len(df)), s=100, color=color, alpha=0.6, label=year)
for i, value in enumerate(df[year]):
ax1.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)
ax1.set_yticks(range(len(df)))
ax1.set_yticklabels(df['类别'])
ax1.set_title('2022-2023年销售额对比', fontsize=14)
ax1.set_xlabel('销售额 (万元)', fontsize=12)
ax1.legend()
ax1.grid(True, axis='x', linestyle='--', alpha=0.3)
# 绘制增长率图
ax2.scatter(df['增长率'], range(len(df)), s=100, color='green', alpha=0.6)
for i, rate in enumerate(df['增长率']):
ax2.hlines(i, 0, rate, colors='green', linestyles='--', alpha=0.3)
ax2.set_yticks(range(len(df)))
ax2.set_yticklabels(df['类别'])
ax2.set_title('2022-2023年增长率对比', fontsize=14)
ax2.set_xlabel('增长率 (%)', fontsize=12)
ax2.grid(True, axis='x', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()
3. 图表解读
这个多数据序列的克利夫兰点图展示了:
-
销售额对比:
- 左侧图表展示了2022年和2023年的销售额对比
- 使用不同颜色区分不同年份
- 通过水平线连接点,便于比较同一产品在不同年份的表现
-
增长率分析:
- 右侧图表展示了各产品的年度增长率
- 使用绿色表示增长情况
- 可以直观看出哪些产品增长最快
-
数据排序:
- 按2023年销售额排序,便于观察产品表现
- 清晰的标签和图例,提高可读性
4. 完整的多数据序列代码
def create_multi_series_cleveland_plot():
# 创建示例数据
categories = ['产品A', '产品B', '产品C', '产品D', '产品E']
sales_2022 = [120, 85, 150, 95, 110]
sales_2023 = [140, 95, 160, 105, 130]
# 创建DataFrame
df = pd.DataFrame({
'类别': categories,
'2022年': sales_2022,
'2023年': sales_2023
})
# 计算增长率
df['增长率'] = ((df['2023年'] - df['2022年']) / df['2022年'] * 100).round(1)
# 按2023年销售额排序
df = df.sort_values('2023年')
# 创建图形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 绘制销售额对比图
for year, color in zip(['2022年', '2023年'], ['gray', 'blue']):
ax1.scatter(df[year], range(len(df)), s=100, color=color, alpha=0.6, label=year)
for i, value in enumerate(df[year]):
ax1.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)
ax1.set_yticks(range(len(df)))
ax1.set_yticklabels(df['类别'])
ax1.set_title('2022-2023年销售额对比', fontsize=14)
ax1.set_xlabel('销售额 (万元)', fontsize=12)
ax1.legend()
ax1.grid(True, axis='x', linestyle='--', alpha=0.3)
# 绘制增长率图
ax2.scatter(df['增长率'], range(len(df)), s=100, color='green', alpha=0.6)
for i, rate in enumerate(df['增长率']):
ax2.hlines(i, 0, rate, colors='green', linestyles='--', alpha=0.3)
ax2.set_yticks(range(len(df)))
ax2.set_yticklabels(df['类别'])
ax2.set_title('2022-2023年增长率对比', fontsize=14)
ax2.set_xlabel('增长率 (%)', fontsize=12)
ax2.grid(True, axis='x', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
create_multi_series_cleveland_plot()
注意事项
- 数据量不宜过多,建议控制在10-15个类别以内
- 确保数据之间的差异足够明显
- 选择合适的颜色方案,避免使用过于相似的颜色
- 添加适当的图例和标签
- 注意中文字体的显示问题,确保系统安装了所需的中文字体
总结
克利夫兰点图是一种强大的数据可视化工具,特别适合展示多个类别的数值比较。通过Python和matplotlib,我们可以轻松创建美观且功能丰富的克利夫兰点图。在实际应用中,要根据具体需求选择合适的展示方式,并注意数据的可读性和美观性。
完整代码
完整的代码实现如下,包含基础示例和多数据序列示例:
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def create_basic_cleveland_plot():
"""创建基础克利夫兰点图"""
# 示例数据
cities = ['北京', '上海', '广州', '深圳', '成都', '杭州']
temperatures = [12, 16, 22, 24, 18, 17]
# 创建DataFrame
df = pd.DataFrame({
'城市': cities,
'温度': temperatures
})
# 按温度排序
df = df.sort_values('温度')
# 创建图形
plt.figure(figsize=(10, 6))
# 绘制点
plt.scatter(df['温度'], range(len(df)), s=100, color='blue', alpha=0.6)
# 添加水平线
for i, temp in enumerate(df['温度']):
plt.hlines(i, 0, temp, colors='gray', linestyles='--', alpha=0.5)
# 设置y轴标签
plt.yticks(range(len(df)), df['城市'])
# 添加标题和标签
plt.title('各城市平均温度对比', fontsize=14)
plt.xlabel('温度 (°C)', fontsize=12)
# 添加网格线
plt.grid(True, axis='x', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()
def create_multi_series_cleveland_plot():
"""创建多数据序列克利夫兰点图"""
# 创建示例数据
categories = ['产品A', '产品B', '产品C', '产品D', '产品E']
sales_2022 = [120, 85, 150, 95, 110]
sales_2023 = [140, 95, 160, 105, 130]
# 创建DataFrame
df = pd.DataFrame({
'类别': categories,
'2022年': sales_2022,
'2023年': sales_2023
})
# 计算增长率
df['增长率'] = ((df['2023年'] - df['2022年']) / df['2022年'] * 100).round(1)
# 按2023年销售额排序
df = df.sort_values('2023年')
# 创建图形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 绘制销售额对比图
for year, color in zip(['2022年', '2023年'], ['gray', 'blue']):
ax1.scatter(df[year], range(len(df)), s=100, color=color, alpha=0.6, label=year)
for i, value in enumerate(df[year]):
ax1.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)
ax1.set_yticks(range(len(df)))
ax1.set_yticklabels(df['类别'])
ax1.set_title('2022-2023年销售额对比', fontsize=14)
ax1.set_xlabel('销售额 (万元)', fontsize=12)
ax1.legend()
ax1.grid(True, axis='x', linestyle='--', alpha=0.3)
# 绘制增长率图
ax2.scatter(df['增长率'], range(len(df)), s=100, color='green', alpha=0.6)
for i, rate in enumerate(df['增长率']):
ax2.hlines(i, 0, rate, colors='green', linestyles='--', alpha=0.3)
ax2.set_yticks(range(len(df)))
ax2.set_yticklabels(df['类别'])
ax2.set_title('2022-2023年增长率对比', fontsize=14)
ax2.set_xlabel('增长率 (%)', fontsize=12)
ax2.grid(True, axis='x', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()
def create_multi_metrics_cleveland_plot():
"""创建多维度指标克利夫兰点图"""
# 创建业务数据
products = ['产品A', '产品B', '产品C', '产品D', '产品E']
metrics = {
'销售额': [120, 85, 150, 95, 110],
'利润率': [25, 18, 30, 22, 28],
'客户满意度': [4.2, 3.8, 4.5, 4.0, 4.3],
'市场份额': [15, 10, 20, 12, 18]
}
# 创建DataFrame
df = pd.DataFrame(metrics, index=products)
# 标准化数据
df_normalized = (df - df.min()) / (df.max() - df.min())
# 创建图形
plt.figure(figsize=(12, 8))
# 为每个指标绘制点
colors = ['blue', 'green', 'red', 'purple']
for (metric, color) in zip(metrics.keys(), colors):
plt.scatter(df_normalized[metric], range(len(products)),
s=100, color=color, alpha=0.6, label=metric)
for i, value in enumerate(df_normalized[metric]):
plt.hlines(i, 0, value, colors=color, linestyles='--', alpha=0.3)
plt.yticks(range(len(products)), products)
plt.title('产品多维度分析', fontsize=14)
plt.xlabel('标准化得分', fontsize=12)
plt.legend()
plt.grid(True, axis='x', linestyle='--', alpha=0.3)
plt.tight_layout()
plt.show()
if __name__ == '__main__':
print("运行基础克利夫兰点图示例...")
create_basic_cleveland_plot()
print("\n运行多数据序列克利夫兰点图示例...")
create_multi_series_cleveland_plot()
print("\n运行多维度指标克利夫兰点图示例...")
create_multi_metrics_cleveland_plot()
这个完整的代码包含了三个主要函数:
create_basic_cleveland_plot(): 创建基础克利夫兰点图create_multi_series_cleveland_plot(): 创建多数据序列克利夫兰点图create_multi_metrics_cleveland_plot(): 创建多维度指标克利夫兰点图
运行代码时会依次展示这三种不同类型的克利夫兰点图,帮助读者理解不同场景下的应用。
参考资料
- Matplotlib官方文档
- 数据可视化最佳实践指南
- Cleveland Dot Plot的历史与应用
希望这篇文章能帮助你理解并掌握克利夫兰点图的创建方法。如果你有任何问题或建议,欢迎在评论区留言讨论。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











