







本文对应代码下载地址:
http://download.csdn.net/detail/sun2043430/5323248
本文参考以下两篇文章,在此表示感谢
http://blog.csdn.net/ijuliet/article/details/4206487
概要说明
Wu-Manber算法用于多模匹配,采用哈希的方式以及BM算法中的坏字符规则达到快速检索、跳跃式步进的效果。读者应该先学习BM算法中的坏字符规则再学习Wu-Manber算法。
使用该算法首先有一些约定和一些常数:
每个模式串的长度不能小于某一个值M_VALUE,一般取M_VALUE值为5。也就是每个模式串的长度都要大于等于5。
BM算法中的坏字符是一个一个的字符,但是Wu-Manber算法中的坏字符是一组一组的,组的长度B_VALUE一般取2或者3(具体使用见下文)。
Wu-Manber算法需要建立两张哈希表,以及一个前缀单链表。
哈希表1为坏字符组滑动距离表;哈希表2为关联表,其中存放前缀单链表的头结点。这样可以顺藤摸瓜得到哈希值相同的所有模式串的信息。
具体建表过程见下文。
预处理建表过程
假设现在要预处理的模式串集合为:
"abcdef"
"123456"
"ab3456"
"12cdef"
M_VALUE的值为5,意思是只预处理每个模式串的前5个字符。同时我们取组长B_VALUE = 2,上面4个模式串的前5个字符取相邻的2个字符为一组,得到下面的组合:
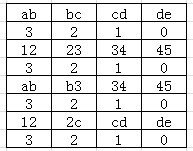
"ab","bc","cd","de",
"12","23","34","45",
"ab","b3","34","45",
"12","2c","cd","de".
我们以两个字符组成一个哈希值,则哈希值的范围是0到65535。所以我们需要开辟size为65536的shift哈希表(存储按照坏字符规则应该滑动的距离)和保存前缀链表头结点的关联哈希表。
shift哈希表以两个字符组成的哈希值为索引,按照这两个字符离第4、5字符之间的距离来填写移动的距离,得到下表:
合并在一起为:

具体的处理过程请参阅代码。需要注意一些细节,应该先初始化所有表项为M_VALUE-B_VALUE+1,也就是4。也就是说对于模式串中没有出现的哈希值,我们应该直接跳过整个字符串的前面4组字符(等同于BM算法中的坏字符规则)。然后对于重复出现的哈希值,在填表时如果发现表中对应项已经填写了小于当前值的数值,则不能用大的数值去覆盖已经存在的小的数值。
上面的shift哈希表是指导目标串往后移动的,对于每个模式串的第3,4下标字符组成的哈希值(例如“de”,“45”)在哈希表里面的对应项填写的是0,此时表示我们找到有可能匹配的位置(在我们这里至少是第3,4字符匹配上了),按理说接下来我们就应该比较整个模式串和目标串的对应位置看是否匹配上了,但是可能3,4字符相同的模式串有很多,为了加速匹配过程,我们又用哈希的方式记录了每个模式串的最开始的2个前缀字符,在进行逐字符完全匹配之前先检查前缀值是否一致,对于一致的才继续进行完全匹配。
我们以第3,4字节组成的WORD类型的哈希值为下标,在关联哈希表的对应位置保存链表的头结点,每一个节点的结构如下:
typedef struct _NODE
{
_NODE *pNext; //next node point
const char *pPattern; //pattern string
WORD wPrefix; //prefix value(0,1 byte)
}NODE, *PNODE;
这样,shift哈希表、关联哈希表 及 前缀单链表 全部建好之后,它们之间的关系如下图:
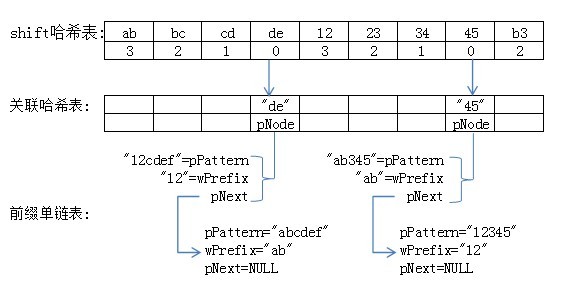
可以看出关联哈希表比较稀疏,其中的空项较多。
Wu-Manber算法匹配过程
经过预处理之后,匹配过程从目标串的开头进行,首先用目标串的第3,4字节组成的哈希值在shift哈希表进行索引,如果得到的值不为0,则根据得到的值将目标串往后滑动(目标串的比较位置往后增加),如果在shift哈希表中查询到的值为0,则转入关联哈希表,得到前缀单链表的头节点,依次遍历该单链表,先比较头2个字符的前缀值是否一样,如果一样就开始真正的逐字符比较,判断是否匹配上了对应的模式串;如果前缀值不同则继续看单链表的下一个节点。如果想查找到所有的匹配情况,则在遍历完单链表之后将目标串的下标加1,再继续进行该匹配过程。
总结来说,匹配过程为:
- 查shift哈希表进行目标串的移动。
- 如果shift哈希表对应项为0,则根据关联哈希表得到前缀单链表头结点。
- 遍历前缀单链表,对于前缀相同的模式串进行完整匹配检查,得到是否匹配的结果。
算法补充说明
本文演示的Wu-Manber算法使用的分组长度B_VALUE值为2,对于2个字节计算哈希值方面会非常简单(直接并在一起组成一个WORD值),哈希表占用的内存大小也不是很大(65536字节为64K、65536*4字节为256K、每个链表节点占10个字节,考虑内存对齐在32位系统下占12个字节,节点个数为模式串的数量)。
如果取分组长度B_VALUE值为3,则计算哈希值的方式要重新设计,不能简单的采用3字节合并的方式(2的24方字节占16M内存)。哈希算法的选取直接决定了哈希表的大小。采用3字节的分组长度哈希过程会复杂一些,但在匹配过程中遇到的可能匹配上的情况会更少一些,具体B_VALUE值是选取2还是3,我在一个代码的注释里面看到如下说明:
// Wu Manber paper suggests B is 2 or 3
// small number of patterns, use B=2, use an exact table
// for large number of patterns, use B=3 use compressed table (their code uses 400 as a cross over )
代码说明
在我上传的代码中,有一个别人实现的C++ Wu-Manber算法类 和 我自己实现的C方式Wu-Manber算法代码。
TestWuManber函数是测试Wu-Manber算法类的,TestWuManber2是测试我写的C代码的。感兴趣的读者可以对比阅读这两个实现,里面的B_VALUE选值不一样。
在目标串char text[] = "text is abcdef 123456 abx456 12xdef 12cdef ab3456 ab3457"中查找以下下几个模式串
"abcdef"
"123456"
"ab3456"
"12cdef"
执行结果如下:
0 1 2 3 4 5 6
0123456789012345678901234567890123456789012345678901234567890
text is abcdef 123456 abx456 12xdef 12cdef ab3456 ab3457
Find at 8, abcdef
Find at 15, 123456
Find at 36, 12cdef
Find at 43, ab3456本文对应代码下载地址:
http://download.csdn.net/detail/sun2043430/5323248















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









