






前言
本文先简述了达梦数据库主备同步主备实现原理,然后描述了如何搭建达梦数据库主备集群的自动切换模式和自动切换模式
目录
手动切换模式下,网络异常手动切主后对导致集群分裂(split)
主备同步原理
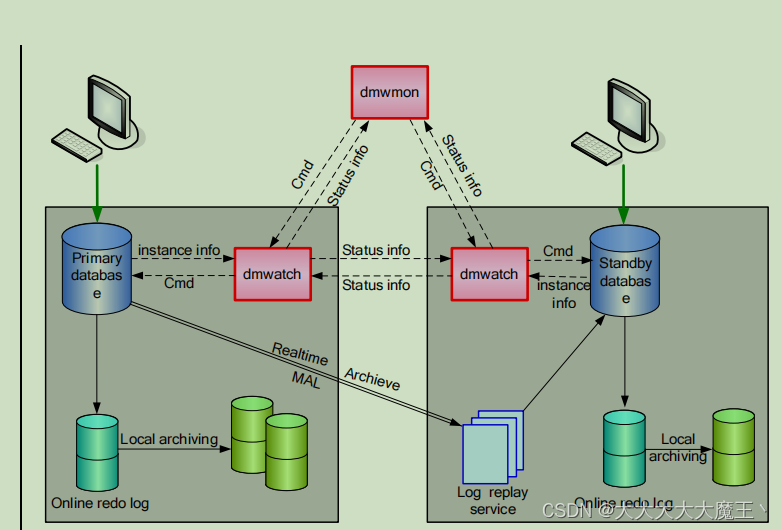
上图为达梦数据库主备同步的架构图。达梦数据库的主备同步是通过在备库重放主库的redo日志实现的。下面为几个重要名词的解析:
- 在线REDO日志系统(online redo log)
- 主要负责生成最近的redo日志
- 本地REDO日志归档服务
主要负责归档redo日志
实时REDO日志归档服务
主要负责实时传输主库的redo 日志
REDO日志重做服务
主要负责在备库上重做从主库传输过来的redo日志
MAL系统
过 MAL 系统实现 REDO 日志传输(实时归档日志)。MAL 系统是基于 TCP 协议实的一种内部通信机制,具有可靠、灵活、高效的特性。 - 守护进程 dmwatcher
在基于守护进程的数据守护方案中,主备机上各自配置一个守护进程,通过守护进程之间的通信处理主备的检测、故障切换和恢复
监视器 DMWMON
监控dmwatcher状态
上述的几个日志归档服务是DmServer进程内部的不同模块,守护进程 dmwatcher 和监视器 DMWMON 为独立的进程。
主备集群搭建操作步骤
| hostname | 用途 |
| dameng01 | 搭建主库 |
| dameng02 | 搭建备库 |
| dameng03 | 用于搭建自动切换模式下的DMWMON |
主库准备
搭建好一套主库
略
开启主库归档
dameng01执行:通过disql 或者 DM 管理工具连接数据库,然后执行以下SQL
ALTER DATABASE MOUNT;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE ADD ARCHIVELOG 'DEST=/opt/dmdbms/data/DAMENG/arch, TYPE=LOCAL, FILE_SIZE=1024, SPACE_LIMIT=51200';
ALTER DATABASE OPEN;主库导出备份数据
dameng01执行:通过disql 或者 DM 管理工具连接主库,然后执行以下SQL,导出备份数据没用于备库的初始化
BACKUP DATABASE BACKUPSET '/opt/dmdbms/data/DAMENG/bak/BACKUP_FILE';注意点: 备份需要依赖 dmap ,如果未安装,会报 [-7170]:bakres连接DMAP失败,处理方法详见:
https://eco.dameng.com/community/training/94d007624e4fe04538c850850af7e554
另外达梦的社区还是做的不错的,搭建过程遇到的问题几乎都可以在达梦社区上找到解决方法
修开主库主备同步相关配置
以下命令都在dameng01执行
1.修改配置 配置
通过disql 或者 DM 管理工具连接主库,然后执行以下SQL
SP_SET_PARA_VALUE (2,'PORT_NUM',5236);
SP_SET_PARA_VALUE (2,'DW_INACTIVE_INTERVAL',60);
SP_SET_PARA_VALUE (2,'ALTER_MODE_STATUS',0);
SP_SET_PARA_VALUE (2,'ENABLE_OFFLINE_TS',2);
SP_SET_PARA_VALUE (2,'MAL_INI',1);
SP_SET_PARA_VALUE (2,'RLOG_SEND_APPLY_MON',64);2.关闭数据库实例
DmServiceDMSERVER stop
注意: DmServiceDMSERVER 请改成你的注册的服务,也可以直接通过kill 把DmServer杀掉
3.修改dmarch.ini
[dmdba@~]$ vi /opt/dmdbms/data/DAMENG/dmarch.ini
ARCH_WAIT_APPLY = 0 #0:高性能 1:事务一致
[ARCHIVE_LOCAL]
ARCH_TYPE = LOCAL #本地归档类型
ARCH_DEST = /opt/dmdbms/data/DAMENG/arch/ #本地归档存放路径
ARCH_FILE_SIZE = 1024 #单个归档大小,单位 MB
ARCH_SPACE_LIMIT = 51200 #归档上限,单位 MB
[ARCHIVE_REALTIME1]
ARCH_TYPE = REALTIME #实时归档类型
ARCH_DEST = GRP1_RT_02 #实时归档目标实例名注意按实际修改你的ARCH_DEST
4.创建 dmmal.ini
[dmdba@~]$ vi /opt/dmdbms/data/DAMENG/dmmal.ini
MAL_CHECK_INTERVAL = 10 #MAL 链路检测时间间隔
MAL_CONN_FAIL_INTERVAL = 10 #判定 MAL 链路断开的时间
MAL_TEMP_PATH = /opt/dmdbms/data/malpath/ #临时文件目录
MAL_BUF_SIZE = 512 #单个 MAL 缓存大小,单位 MB
MAL_SYS_BUF_SIZE = 2048 #MAL 总大小限制,单位 MB
MAL_COMPRESS_LEVEL = 0 #MAL 消息压缩等级,0 表示不压缩
[MAL_INST1]
MAL_INST_NAME = GRP1_RT_01 #实例名,和 dm.ini 的 INSTANCE_NAME 一致
MAL_HOST = 192.168.1.1 #MAL 系统监听 TCP 连接的 IP 地址
MAL_PORT = 5336 #MAL 系统监听 TCP 连接的端口
MAL_INST_HOST = 172.16.1.1 #实例的对外服务 IP 地址
MAL_INST_PORT = 5236 #实例对外服务端口,和 dm.ini 的 PORT_NUM 一致
MAL_DW_PORT = 5436 #实例对应的守护进程监听 TCP 连接的端口
MAL_INST_DW_PORT = 5536 #实例监听守护进程 TCP 连接的端口
[MAL_INST2]
MAL_INST_NAME = GRP1_RT_02
MAL_HOST = 192.168.1.2
MAL_PORT = 5336
MAL_INST_HOST = 172.16.1.2
MAL_INST_PORT = 5236
MAL_DW_PORT = 5436
MAL_INST_DW_PORT = 5536MAL_INST1 填主库相关信息;MAL_INST2填备库相关信息
5.创建dmwatcher.ini
[dmdba@~]$ vi /opt/dmdbms/data/DAMENG/dmwatcher.ini
[GRP1]
DW_TYPE = GLOBAL #全局守护类型
DW_MODE = MANUAL #MANUAL:故障手切 AUTO:故障自切
DW_ERROR_TIME = 20 #远程守护进程故障认定时间
INST_ERROR_TIME = 20 #本地实例故障认定时间
INST_RECOVER_TIME = 60 #主库守护进程启动恢复的间隔时间
INST_OGUID = 45331 #守护系统唯一 OGUID 值
INST_INI = /opt/dmdbms/data/DAMENG/dm.ini #dm.ini 文件路径
INST_AUTO_RESTART = 1 #打开实例的自动启动功能
INST_STARTUP_CMD = /opt/dmdbms/bin/dmserver #命令行方式启动
RLOG_SEND_THRESHOLD = 0 #指定主库发送日志到备库的时间阈值,默认关闭
RLOG_APPLY_THRESHOLD = 0 #指定备库重演日志的时间阈值,默认关闭注意按实际情况修改路径
注册服务
#重新注册DmServer服务,以mount 方式启动
/data01/dmdbms/script/root/dm_service_installer.sh -t dmserver -p DMSERVER -dm_ini /data01/dmdata/DAMENG/dm.ini -m mount
#注册data watcher
/data01/dmdbms/script/root/dm_service_installer.sh -t dmwatcher -p Watcher -watcher_ini /data01/dmdata/DAMENG/dmwatcher.ini重新注册dmserver前,注意先把旧的服务卸载了
/opt/dmdbms/script/root/dm_service_uninstaller.sh -n [你的DmServer服务名,如DmService]
备库准备
搭建一套DM
略。注意修改dm.ini的实例名,跟主库的dmmal.ini 要对应上
恢复全量数据
dameng02执行以下命令
#执行拷贝数据到备库
scp -r dmdba@dameng01:/data01/dm_bak/BACKUP_FILE /opt/dmdbms/data/DAMENG/bak/BACKUP_FILE
#恢复数据
/data01/dmdbms/bin/dmrman CTLSTMT="RESTORE DATABASE '/data01/dmdata/DAMENG/dm.ini' FROM BACKUPSET '/data01/dm_bak/BACKUP_FILE'"
/data01/dmdbms/bin/dmrman CTLSTMT="RECOVER DATABASE '/data01/dmdata/DAMENG/dm.ini' FROM BACKUPSET '/data01/dm_bak/BACKUP_FILE'"
/data01/dmdbms/bin/dmrman CTLSTMT="RECOVER DATABASE '/data01/dmdata/DAMENG/dm.ini' UPDATE DB_MAGIC"修改配置
替换 dmarch.ini
1.修改dmarch.ini
在dameng02执行以下命令
[dmdba@~]$ vi /opt/dmdbms/data/DAMENG/dmarch.ini
ARCH_WAIT_APPLY = 0 #0:高性能 1:事务一致
[ARCHIVE_LOCAL]
ARCH_TYPE = LOCAL #本地归档类型
ARCH_DEST = /opt/dmdbms/data/DAMENG/arch/ #本地归档存放路径
ARCH_FILE_SIZE = 1024 #单个归档大小,单位 MB
ARCH_SPACE_LIMIT = 51200 #归档上限,单位 MB
[ARCHIVE_REALTIME1]
ARCH_TYPE = REALTIME #实时归档类型
ARCH_DEST = GRP1_RT_01 #实时归档目标实例名注意按实际把arch_dest 改成主库的实例名
2.修改dm.ini
在dameng02执行,修改dm.ini
备库 dm.ini 参数修改如下:
INSTANCE_NAME = GRP1_RT_02
PORT_NUM = 5236 #数据库实例监听端口
DW_INACTIVE_INTERVAL = 60 #接收守护进程消息超时时间
ALTER_MODE_STATUS = 0 #不允许手工方式修改实例模式/状态/OGUID
ENABLE_OFFLINE_TS = 2 #不允许备库 OFFLINE 表空间
MAL_INI = 1 #打开 MAL 系统
ARCH_INI = 1 #打开归档配置
RLOG_SEND_APPLY_MON = 64 #统计最近 64 次的日志重演信息3.修改dmmal.ini 和 dmwatcher.ini
在dameng02 修改dmmal.ini 和 dmwatcher.ini,让这两个配置跟主库保持一致
配置监视器
达梦数据库的主备集群分为手动切换模式和自动切换模式。
- 手动切换模式:集群故障时需要人工接入切主
- 自动切换模式:集群故障时由dmmonitor辅助,完成自动切主。
手动切换模式
在dameng01和dameng02执行, bin 目录中存放非确认监视器配置文件。
[dmdba@~]$ vi /opt/dmdbms/bin/dmmonitor.ini
MON_DW_CONFIRM = 0 #0:非确认(故障手切) 1:确认(故障自切)
MON_LOG_PATH = /opt/dmdbms/log #监视器日志文件存放路径
MON_LOG_INTERVAL = 60 #每隔 60s 定时记录系统信息到日志文件
MON_LOG_FILE_SIZE = 512 #单个日志大小,单位 MB
MON_LOG_SPACE_LIMIT = 2048 #日志上限,单位 MB
[GRP1]
MON_INST_OGUID = 45331 #组 GRP1 的唯一 OGUID 值
MON_DW_IP = 192.168.1.1:5436 #IP 对应 MAL_HOST,PORT 对应 MAL_DW_PORT
MON_DW_IP = 192.168.1.2:5436注意修改日志路径和IP
自动切换模式
0.自动切换模式下,需要额外多准备一台服务器,并安装达梦数据库软件,用于搭建确认监听器。以下以dameng03表示
1.确认监听器创建配置dmmonitor.ini
dameng03执行命令
[dmdba@~]$ vi /opt/dmdbms/bin/dmmonitor.ini
MON_DW_CONFIRM = 1 #0:非确认(故障手切) 1:确认(故障自切)
MON_LOG_PATH = /opt/dmdbms/log #监视器日志文件存放路径
MON_LOG_INTERVAL = 60 #每隔 60s 定时记录系统信息到日志文件
MON_LOG_FILE_SIZE = 512 #单个日志大小,单位 MB
MON_LOG_SPACE_LIMIT = 2048 #日志上限,单位 MB
[GRP1]
MON_INST_OGUID = 45331 #组 GRP1 的唯一 OGUID 值
MON_DW_IP = 192.168.1.1:5436 #IP 对应 MAL_HOST,PORT 对应 MAL_DW_PORT
MON_DW_IP = 192.168.1.2:54362.非确认监听器配置dmmonitor.ini
dameng01和dameng02
[dmdba@~]$ vi /opt/dmdbms/bin/dmmonitor.ini
MON_DW_CONFIRM = 0 #0:非确认(故障手切) 1:确认(故障自切)
MON_LOG_PATH = /opt/dmdbms/log #监视器日志文件存放路径
MON_LOG_INTERVAL = 60 #每隔 60s 定时记录系统信息到日志文件
MON_LOG_FILE_SIZE = 512 #单个日志大小,单位 MB
MON_LOG_SPACE_LIMIT = 2048 #日志上限,单位 MB
[GRP1]
MON_INST_OGUID = 45331 #组 GRP1 的唯一 OGUID 值
MON_DW_IP = 192.168.1.1:5436 #IP 对应 MAL_HOST,PORT 对应 MAL_DW_PORT
MON_DW_IP = 192.168.1.2:54363.修改其它配置
dameng01和dameng02修改以下两个配置:
dmarch.ini: ARCH_WAIT_APPLY= 1 (是否需要等待备库做完日志,可选0和1,手动模式必须选1)
dmwatcher.ini : DW_MODE=AUTO (自动切换模式)
4.确认监听器注册服务
dameng03执行以下命令
/data01/dmdbms/script/root/dm_service_installer.sh -t dmmonitor -p Monitor -monitor_ini /data01/dmdbms/bin/dmmonitor.ini
启动服务
主库执行
SP_SET_OGUID(45331);
ALTER DATABASE PRIMARY;备库执行
SP_SET_OGUID(45331);
ALTER DATABASE standby;启动dmwatch (主备执行)
/data01/dmdbms/bin/DmWatcherServiceWatcher start (启动后会自动拉起server)
启动monitor
dameng01和dameng02启动监听器:
/data01/dmdbms/bin/DmMonitorServiceMonitor start(后台模式)
/data01/dmdbms/bin/dmmonitor path=/data01/dmdbms/bin/dmmonitor.ini (前台启动模式)
异常场景测试
手动模式
手动切换
- 启动sdbmonitor
- login
- switchover GRP1.DMSERVER_BAK
主库进程异常(挂起/shutdown)
主库/备库 shutdown
通过kill 命令,杀死dmserver 。 shutdown 30S后DmServer被watcher 自动拉起,拉起后读写正常



自动模式
主库/备库 shutdown
通过kill 命令,杀死dmserver 。 shutdown 30S后DmServer被watcher 自动拉起,拉起后读写正常。
主库宕机
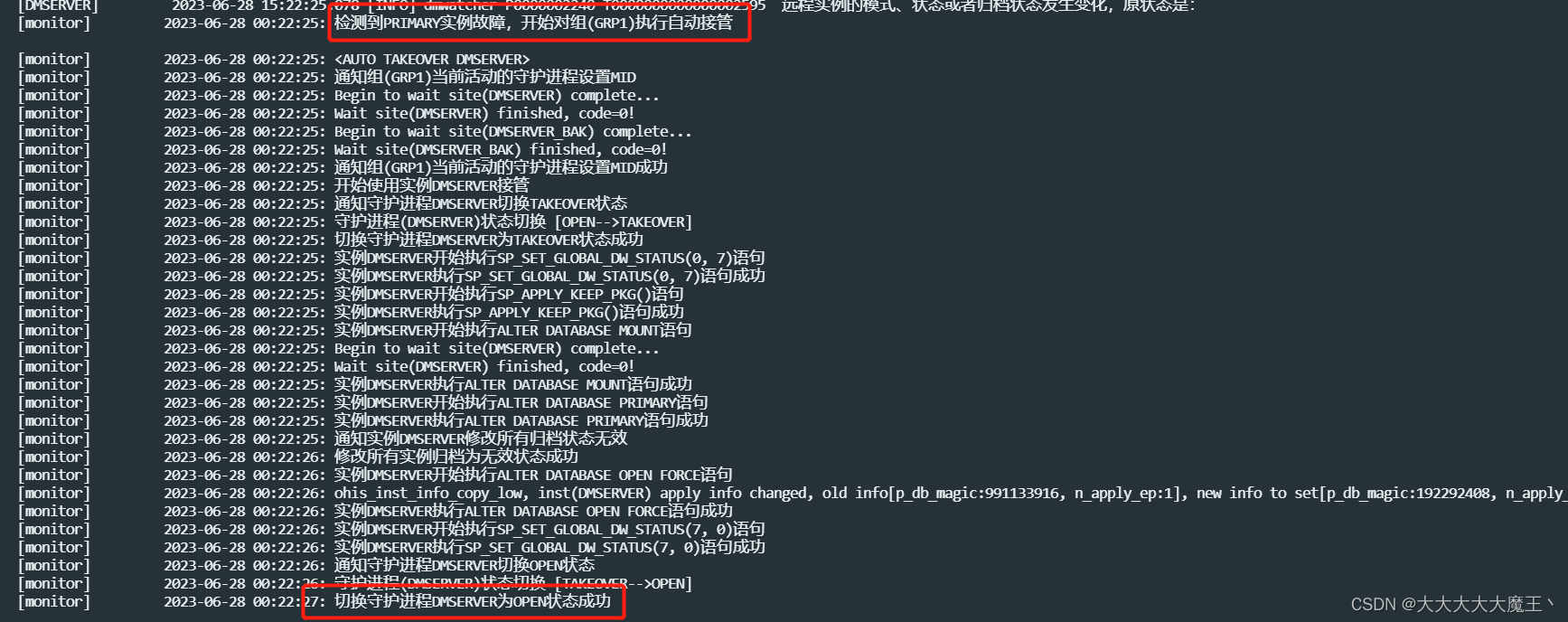
关闭主库服务器。服务器关闭后,主备完成自动切主
常见问题
以下为搞主在搭建过程中遇到的问题及解决方法
备库无法启动导致主库一直mount

dmmonitor执行 check open GRP1.DMSERVER 打印报错如下:
[monitor] 2023-07-04 09:38:48: 实例(dmserver)的检测结果:Dmwatcher(DMSERVER) has not received any other dmwatcher messages, dmwatcher cannot notify instance(DMSERVER) to open or switch self to OPEN status!
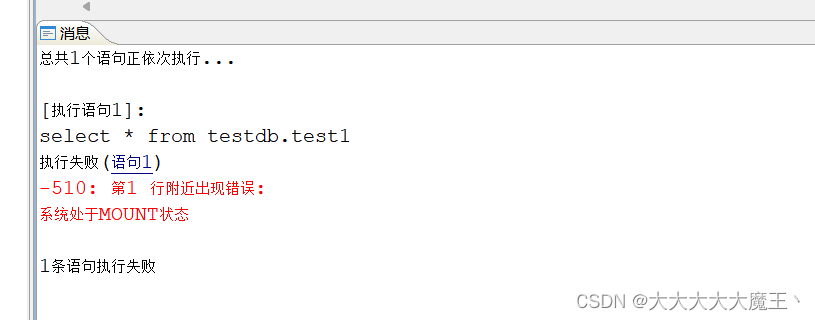
这个原因是,在集群启动时,只启动了一个库,另外一个库未启动。在只有一个库的情况下本地watcher 不知道哪个库的数据是最新的,不能无脑地让本地库直接对外服务,否则很可能出现脑裂。因此,需要保证在集群启动时,所有实例都是正常的。
配置完主备后,一直处于mount 状态
现象:
配置完主备后,一直处于mount 状态。无法执行SQL。在dmmonitor 执行check open ,显示local dmwatcher's act_type is ACT_KEEP, need user to intervene。
原因:
备库的虚拟机是通过克隆生成的,当时以为不用恢复数据了,忽略了恢复数据步骤
解决方法:
停止备库,执行数据恢复命令,然后执行ALTER DATABASE standby; 。
手动切换模式下,网络异常手动切主后对导致集群分裂(split)
搞主在测试时,模拟了网络异常并强制切主导致集群分裂(split)
现象:网络恢复后,存在两个primary

解决方法:
- 网络异常情况下先解决网络问题,短时间内无法解决才手动切主
- 人工介入,处理split 问题。(简单方法就是重新初始化备库)















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









