







 本文详细介绍了如何使用Python实现Spark Streaming与Kafka的整合,包括基于Receiver和Direct两种模型,强调了Direct方式的并行性和高效性,并提供了代码实践和调优建议,如设置合理的batchDuration、maxRatePerPartition、缓存策略和JVM GC选项等。
本文详细介绍了如何使用Python实现Spark Streaming与Kafka的整合,包括基于Receiver和Direct两种模型,强调了Direct方式的并行性和高效性,并提供了代码实践和调优建议,如设置合理的batchDuration、maxRatePerPartition、缓存策略和JVM GC选项等。
说明
Spark Streaming的原理说明的文章很多,这里不做介绍。本文主要介绍使用Kafka作为数据源的编程模型,编码实践,以及一些优化说明
spark streaming:http://spark.apache.org/docs/1.6.0/streaming-programming-guide.html
streaming-kafka-integration:http://spark.apache.org/docs/1.6.0/streaming-kafka-integration.html
演示环境
- Spark:1.6
- Kafka:kafka_2.11-0.9.0.1
- 实现语言:Python
编程模型
目前Spark Streaming 的kafka编程主要包括两种模型
1. 基于Receiver
2. Direct(无Receiver)
基于Receiver
这种方式利用接收器(Receiver)来接收kafka中的数据,其最基本是使用Kafka高阶用户API接口。对于所有的接收器,从kafka接收来的数据会存储在spark的executor中,之后spark streaming提交的job会处理这些数据
原理图
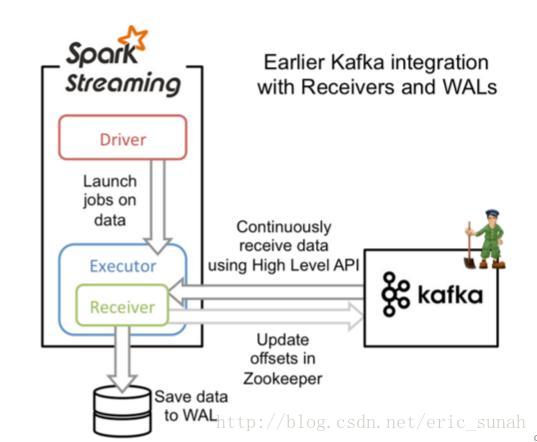
说明
- 需要借助Write Ahead Logs 来保证数据的不丢失,如果我们启用了Write Ahead Logs复制到文件系统如HDFS,那么storage level需要设置成 StorageLevel.MEMORY_AND_DISK_SER,也就是KafkaUtils.createStream(…, StorageLevel.MEMORY_AND_DISK_SER)
- 在Receiver的方式中,Spark中的partition和kafka中的partition并不是相关的,所以如果我们加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度。
- 对于不同的Group和topic我们可以使用多个Receiver创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream。
Direct(无Receiver)
在spark1.3之后,引入了Direct方式。不同于Receiver的方式,Direct方式没有receiver这一层,其会周期性的获取Kafka中每个topic的每个partition中的最新offsets,之后根据设定的maxRatePerPartition来处理每个batch
不同于Receiver的方式(是从Zookeeper中读取offset值,那么自然zookeeper就保存了当前消费的offset值,那么如果重新启动开始消费就会接着上一次offset值继续消费)。而在Direct的方式中,是直接从kafka来读数据,那么offset需要自己记录,可以利用checkpoint、数据库或文件记录或者回写到zookeeper中进行记录
原理图
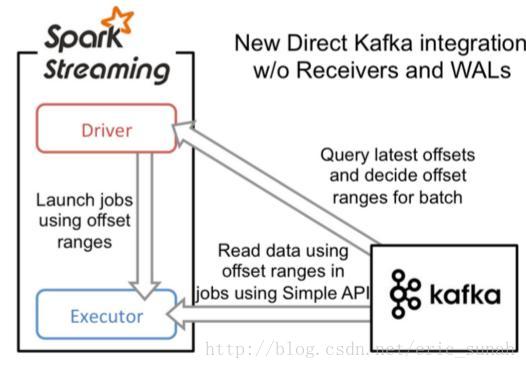
说明
- 简化的并行:在Receiver的方式中我们提到创建多个Receiver之后利用union来合并成一个Dstream的方式提高数据传输并行度。而在Direct方式中,Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据,这种映射关系也更利于理解和优化。
- 高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据,浪费!而第二种方式不存在这个问题,只要我们Kafka的数据保留时间足够长,我们都能够从Kafka进行数据恢复。
- 精确一次:在Receiver的方式中,使用的是Kafka的高阶API接口从Zookeeper中获取offset值,这也是传统的从Kafka中读取数据的方式,但由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费。而第二种方式,直接使用了简单的低阶Kafka API,Offsets则利用Spark Streaming的checkpoints进行记录,消除了这种不一致性。
代码实践
Kafka生产者
package com.eric.kafka.producer;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerCon 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3090
3090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









