







文章目录
一.关于MapReduce
(一)什么是MapReduce?
MapReduce是一个分布式计算框架
- 它将大型数据操作作业分解为可以跨服务器集群并行执行的单个任务。
- 起源于Google,它是一个编程模型,用于大数据量的计算
适用于大规模数据处理场景
- 每个节点处理存储在该节点的数据
每个job包含Map和Reduce两部分
(二) MapReduce的设计思想
分而治之
- 简化并行计算的编程模型,即把对大规模数据集的操作分发给一个主节点管理下的各个子节点共同完成,然后整合各个子节点的中间结果,
- 从而得到最终的计算结果
构建抽象模型:Map和Reduce
- 开发人员专注于实现Mapper和Reducer函数
隐藏系统层细节
- 开发人员专注于业务逻辑实现
(三) MapReduce特点
优点
- 1)易于编程
- MapReduce只需简单地实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机上运行
- 2)良好的可扩展性
- 当计算机资源得不到满足的时候,可以通过简单的增加机器来扩展它的计算能力
- 3)高容错性
- 比如一台机器挂了,可以把它上面的计算任务转移到另一个节点上运行,不至于整个任务运行失败,而且这个过程不需要人工干预,
- 完全由hadoop内部完成
- 4)高吞吐量
- 能对PB量级以上海量数据进行离线处理.适合离线处理而不适合实时处理,比如要求毫秒级返回一个结果,会很难做到
不适用领域 - 难以实时计算
- 不适合流式计算
- DAG(有向图)计算
(四)MapReduce实现WordCount

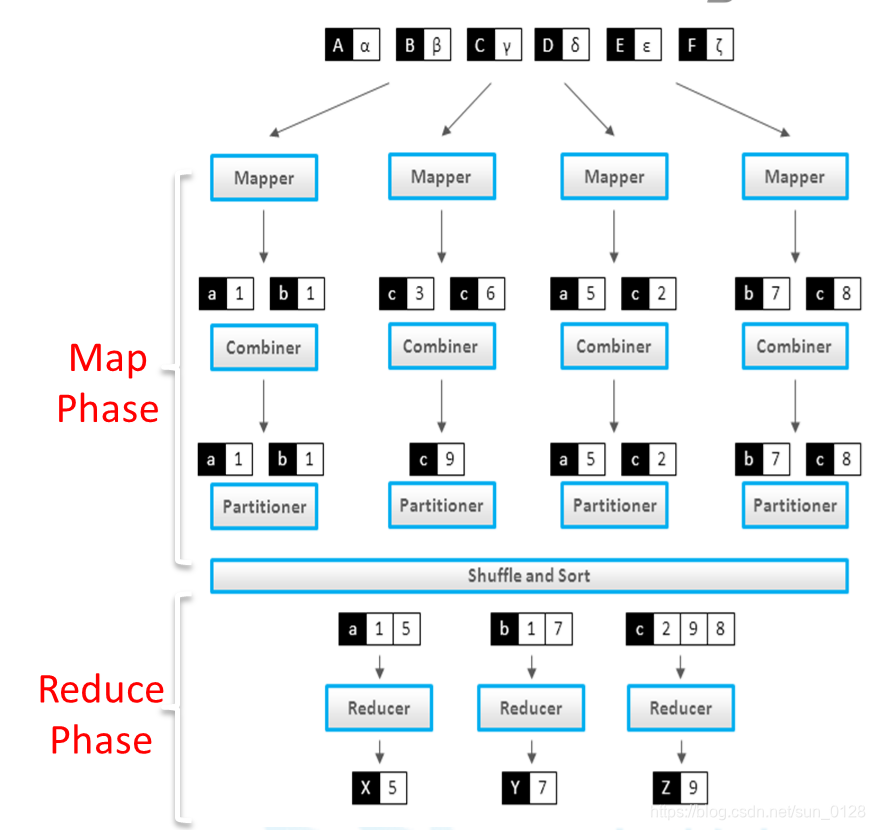
(五)MapReduce执行过程
数据定义格式
- map: (K1,V1) → list (K2,V2)
- reduce: (K2,list(V2)) → list (K3,V3)
MapReduce执行过程
- Mapper
- Combiner
- Partitioner
- Shuffle and Sort
- Reducer
(六)Key&Value类型
必须可序列化(serializable hadoop实现的是Writable接口)
- 作用:网络传输以及持久化存储
- IntWritable、LongWriteable、FloatWritable、Text、DoubleWritable, BooleanWritable、NullWritable等
都继承了Writable接口
- 并实现write()和readFields()方法
Keys必须实现WritableComparable接口
- Reduce阶段需要sort
- keys需要可比较
二.MapReduce编程模型
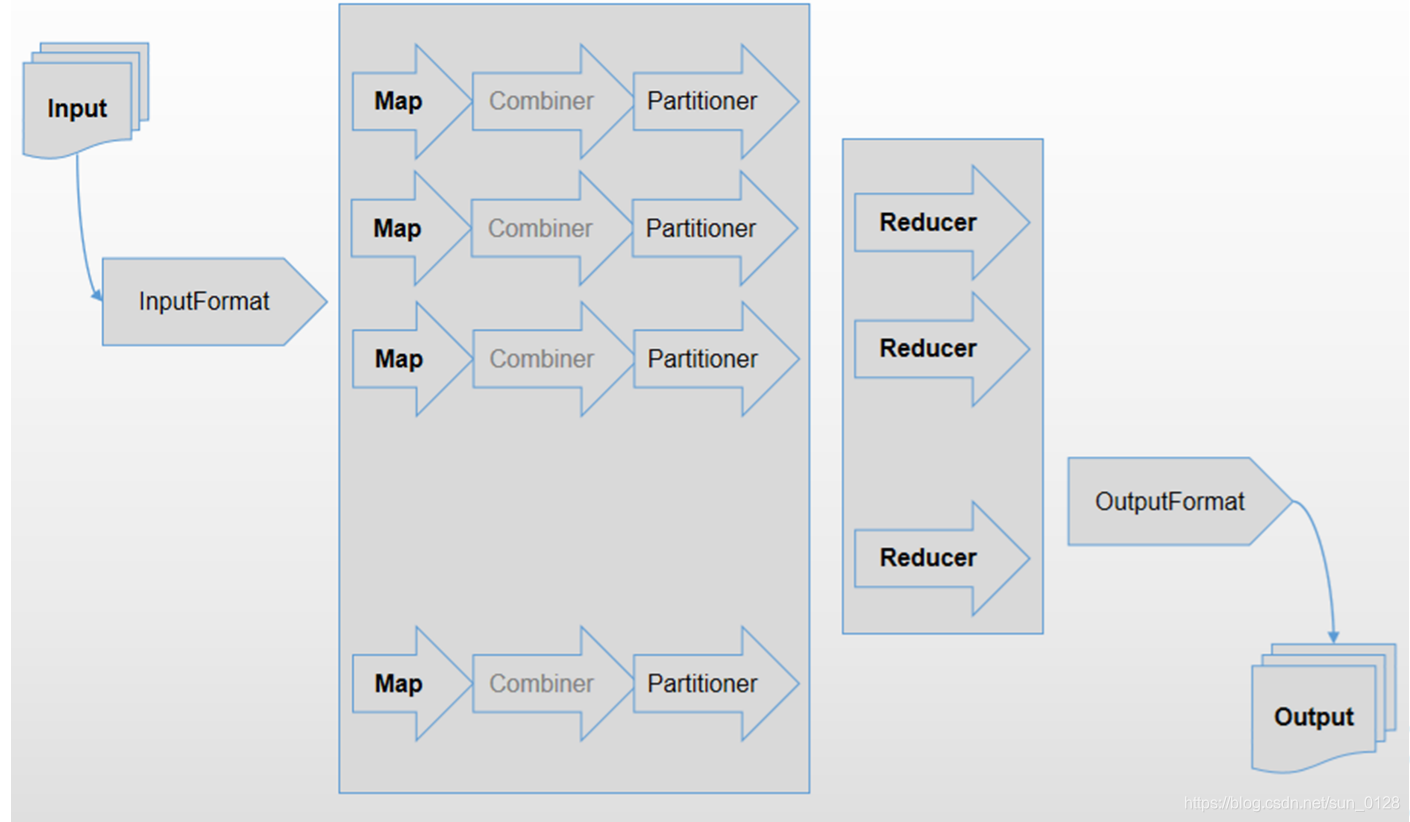
(一)InputFormat接口
InputSplit(数据切片)
- 1.找到你输入数据存储的目录
- 2.开始遍历目录下每一个文件
- 3.遍历第一个文件,wc.txt
- 4.获取文件大小
- 5.计算切片的大小,默认情况下切片大小会等于块大小
- 6.开始切片(假设260M文件,0-128M,128-256M,256M-260M,判断剩下的部分是否大于块的1.1倍,如果不大于1.1,就直接划分为一个切片)
切片和数据块区别?
- 切片:MapReduce中的逻辑概念,一个切片就是一个Mapper任务
- 数据库Block:hdfs上的物理切割,是一个物理概念
- split划分是在记录的边界处
- 通常情况下切片的个数等于(不应大于)数据块的个数
定义了如何将数据读入Mapper
- InputSplit[] getSplits
- InputSplit表示由单个Mapper处理的数据
- getSplits方法将一个大数据在逻辑上拆分为InputSplit
- RecordReader<K,V> getRecordReader
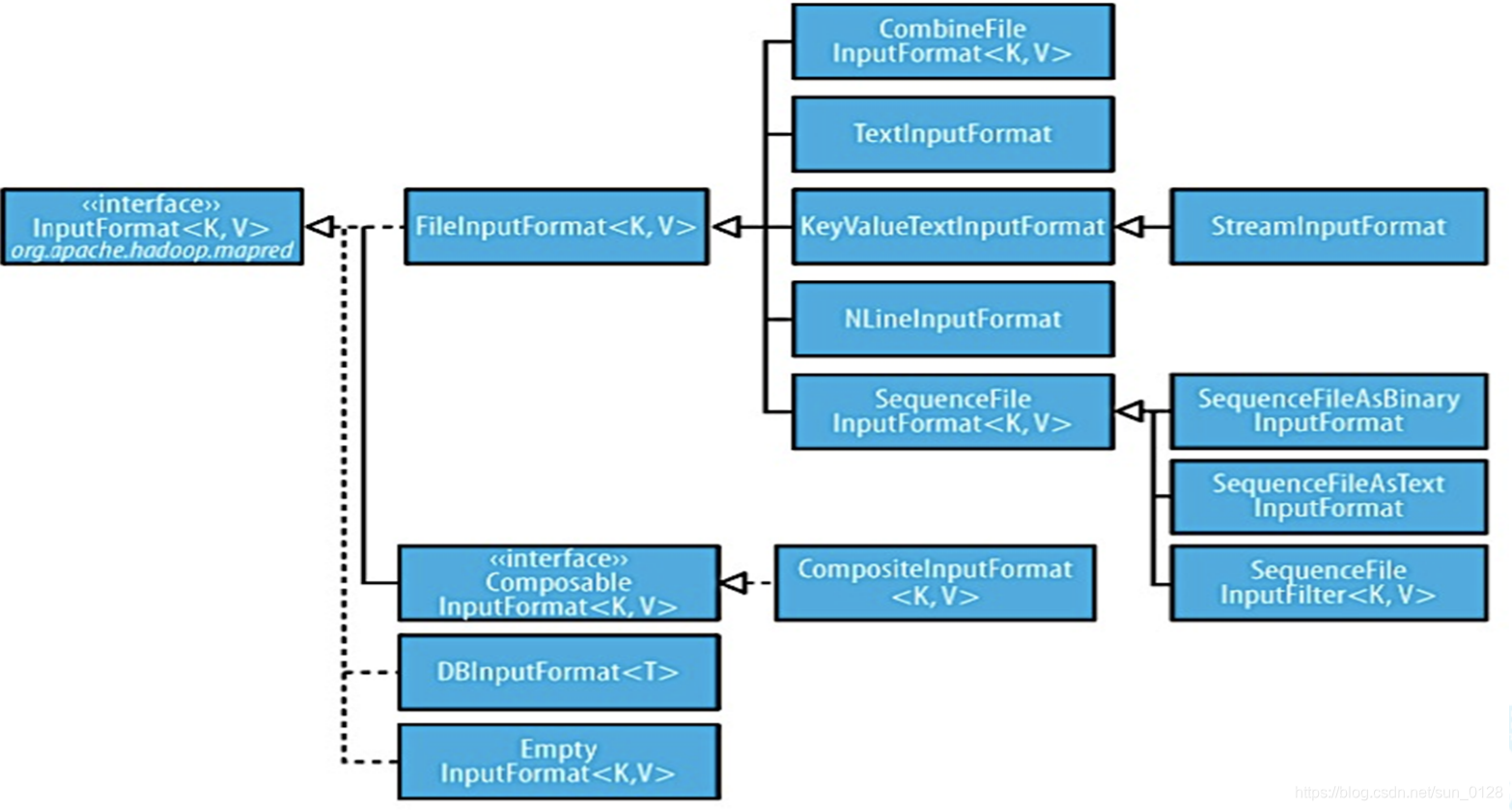
常用InputFormat接口实现类
- TextInputFormat
- FileInputFormat
- KeyValueInputFormat
(二)Mapper类
Mapper主要方法
- void setup(Context context)
- org.apache.hadoop.mapreduce.Mapper.Context
- void map(KEY key, VALUE value, Context context)
- 为输入分片中的每个键/值对调用一次
- void cleanup(Context context)
- void run(Context context)
- 可通过重写该方法对Mapper进行更完整控制
代码示例如下:
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable>
{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context ctx)
throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer( value.toString() );
while ( itr.hasMoreTokens() )
{
word.set( itr.nextToken() );
ctx.write( word, one);
}
}
}
(三)Combiner类
Combiner相当于本地化的Reduce操作
- 在shuffle之前进行本地聚合
- 用于性能优化,可选项
- 输入和输出类型一致
Reducer可以被用作Combiner的条件
- 符合交换律和结合律
实现Combiner
- 1.先写一个Combiner类(逻辑和reduce类一样可直接拷贝代码)
- 2.在Driver类中设置位置:
job.setCombinerClass(WCCombiner.class)
(四)Partitioner类
用于在Map端对key进行分区
- 默认使用的是HashPartitioner
- 1)获取key的哈希值
- 2)使用key的哈希值对Reduce任务数求模
- 决定每条记录应该送到哪个Reducer处理
自定义Partitioner
- 1.新建一个类继承抽象类Partitioner,重写getPartition方法
- 2.在Driver类中设置位置:
job.setPartitionerClass(ProvincePartitioner.class); - 3.设置reduce的任务数:
job.setNumReduceTasks(5); - 4.分区数量假设为5和reduce任务数关系:
1或>=5的任务数,最好是等于 reduce的数量最好是等于分区的数量,多余的话分区会有空白文件,如果小于会报错,值为1只有一个分区
具体代码如下:
package hadoop.hdfs.flowcount.partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @author sunyong
* @date 2020/07/02
* @description
*/
public class ProvincePartitioner extends Partitioner<Text,FlowBean> {
//按手机号前三位分区
@Override
public int getPartition(Text key, FlowBean value, int i) {
//取出手机号前三位
String proNum = key.toString().substring(0,3);
int partition = 4;
//判断属于哪个省,返回分区号
if("136".equals(proNum)){
partition = 0;
}else if("137".equals(proNum)){
partition=1;
}else if("138".equals(proNum)){
partition=2;
}else if("139".equals(proNum)){
partition=3;
}
return partition;
}
}
(五)Reducer类
Reducer主要方法如下:
void setup(Context context)
- org.apache.hadoop.mapreduce.Reducer.Context
void reduce(KEY key, Iterable values, Context context)
- 为每个key调用一次
void cleanup(Context context)
void run(Context context)
- 可通过重写该方法来控制reduce任务的工作方式
(六)OutputFormat接口
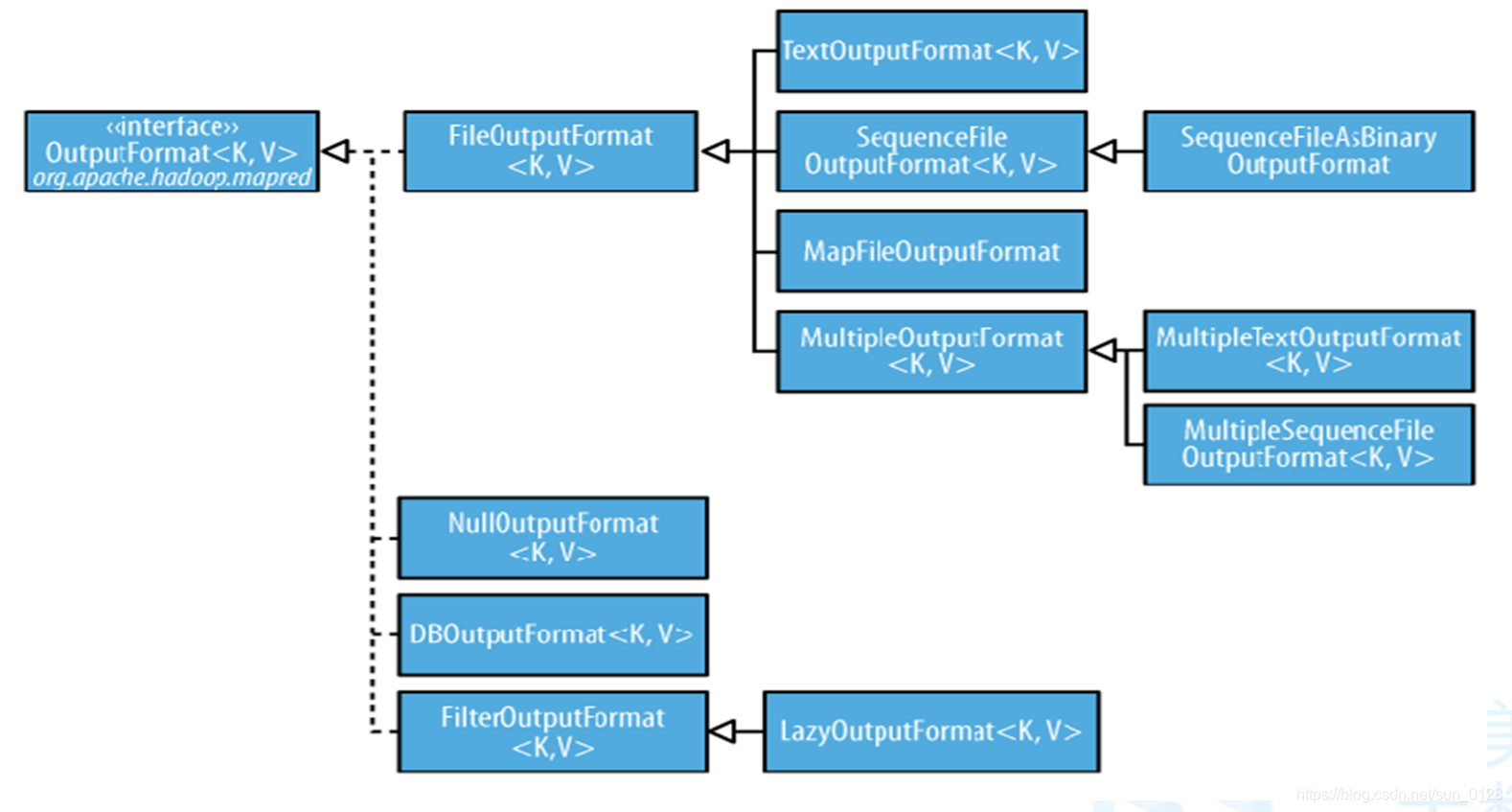
定义了如何将数据从Reducer进行输出
- RecordWriter<K,V> getRecordWriter-->将Reducer的<key,value>写入到目标文件
- checkOutputSpecs-->判断输出目录是否存在
常用OutputFormat接口实现类
- TextOuputFormat
- SequenceFileOuputFormat
- MapFileOuputFormat
(七)Job类执行任务,代码如下:
//创建Job
Job job = Job.getInstance(getConf(), "WordCountMR" );
//设置jar一般为加载当前类
job.setJarByClass(类名.class);
//设置输入
FileInputFormat.addInputPath(job, new Path(args[0]) );
job.setInputFormatClass( TextInputFormat.class );
//设置输出
FileOutputFormat.setOutputPath( job, new Path(args[1]) );
job.setOutputFormatClass( TextOutputFormat.class );
//设置map
job.setMapperClass( WCMapper.class );
job.setMapOutputKeyClass( Text.class );
job.setMapOutputValueClass( IntWritable.class );
//设置reduce
job.setReducerClass( WCReducer.class );
job.setOutputKeyClass( Text.class );
job.setOutputValueClass( IntWritable.class );
//提交程序运行
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
(八)使用MapReduce实现 SQL Join操作
1.reduce join
- Map端读取所有的文件,并在输出的内容里加上标识,代表数据从哪个文件里来的
- 在reduce处理函数中,按照标识对数据进行处理
- 然后根据key用join来求出结果直接输出
- 缺点:shuffle阶段出现 大量的数据传输,效率很低
2.map join
- 使用场景:一张表十分小、一张表很大
- 在map端缓存多张表,提前处理业务逻辑,这样增加map端业务,减少reduce 端数据的压力,尽可能的减少数据倾斜
mapreduce的join案例
(九)使用Hadoop推测执行
问题
- 程序bug或负载不均时,部分任务成为短板
- 如:100个map任务中的99个完成,剩下1个停留10%
使用推测执行启动备份任务
- 取最先完成的作为最终结果
- 利用资源来换取时间的一种优化策略
- 资源很紧张时不适用















 3490
3490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









