









在之前的文章中提到了,使用 Spark Streaming + Kafka-spark-consumer 来应对Driver程序代码改变,无法从checkpoint中反序列化的问题,即其会自动将kafka的topic中,每个partition的消费offset写入到zookeeper中,当应用重新启动的时候,其可以直接从zookeeper中恢复,但是其也存在一个问题就是:Kafka Manager 无法进行监控了。
一、Kafka Manager 无法监控的原因?
Kafka Manager 在对consumer进行监控的时候,其监控的是zookeeper路径为
/consumers/<consumer.id>/offsets/<topic>/
的路径,而 Kafka-spark-consumer 使用的则是 /kafka_spark_consumer/<consumer.id>/<topic>/
目录,如下图所示:
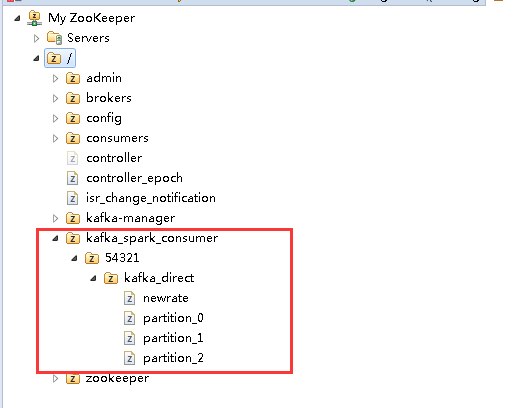
所以Kafka Manager 无法进行监控。
二、解决办法
由于问题的出现跟 Kafka Manager 和 Kafka-spark-consumer 这两个项目有关系,那解决办法也有两个:
第一个:修改 kafka Manager 中关于 consumer 获得数据的来源方式,增加 /kafka_spark_consumer 的处理。
第二个:修改 Kafka-spark-consumer 中在写入offsets位置信息时,同时向原来 Kafka 的consumers进行写入。
以上这两种方法都要对两个开源项目进行二次开发,而我的见意是对 Kafka Manager 进行修改,原因在于 Kafka-spark-consumer 会随着项目进行发布,会非常多,维护和升级会很麻烦,由其当项目不受个人控制的时候;而Kafka Manager就不一样,一个Kafka 集群只会部署一个,那对其做改造和升级就容易多了。
说明:本次,我先对 Kafka-spark-consumer 进行二次开发,也就是上面的第二个解决方案。
三、Kafka-spark-consumer 二次开发
3.1、其实功能很简单,就是 kafka-spark-consumer 向Zookeeper中写入内容的时候,同时向 /consumers/<consumer.id>/offsets/<topic>/
写内容即可。
经过分析其主要内容在PartitionManager.java这个类中,其原始代码如下:
//此处是将offset相关信息写入到 zookeeper 中的方法
public void commit() {
LOG.info("LastComitted Offset : " + _lastComittedOffset);
LOG.info("New Emitted Offset : " + _emittedToOffset);
LOG.info("Enqueued Offset :" + _lastEnquedOffset);
if (_lastEnquedOffset > _lastComittedOffset) {
//拼装某个partition写入的内容,JSON格式
LOG.info("Committing offset for " + _partition);
Map<Object, Object> data =
(Map<Object, Object>) ImmutableMap.builder().put(
"consumer",
ImmutableMap.of("id", _ConsumerId)).put(
"offset",
_emittedToOffset).put("partition", _partition.partition).put(
"broker",
ImmutableMap.of(
"host",
_partition.host.host,
"port",
_partition.host.port)).put("topic", _topic).build();
try {
//执行写入操作,此处也是我们需要改动的地方
_state.writeJSON(committedPath(), data);
LOG.info("Wrote committed offset to ZK: " + _emittedToOffset);
_waitingToEmit.clear();
_lastComittedOffset = _emittedToOffset;
} catch (Exception zkEx) {
LOG.error("Error during commit. Let wait for refresh "
+ zkEx.getMessage());
}
LOG.info("Committed offset "
+ _lastComittedOffset
+ " for "
+ _partition
+ " for consumer: "
+ _ConsumerId);
// _emittedToOffset = _lastEnquedOffset;
} else {
LOG.info("Last Enqueued offset "
+ _lastEnquedOffset
+ " not incremented since previous Comitted Offset "
+ _lastComittedOffset
+ " for partition "
+ _partition
+ " for Consumer "
+ _ConsumerId
+ ". Some issue in Process!!");
}
}
/**
*从名字上可以看出,是获取 kafka-spark-consumer 的 zookeeper保存路径的
*/
private String committedPath() {
return _stateConf.get(Config.ZOOKEEPER_CONSUMER_PATH)
+ "/"
+ _stateConf.get(Config.KAFKA_CONSUMER_ID)
+ "/"
+ _stateConf.get(Config.KAFKA_TOPIC)
+ "/"
+ _partition.getId();
}改动如下:
public void commit() {
LOG.info("LastComitted Offset : " + _lastComittedOffset);
LOG.info("New Emitted Offset : " + _emittedToOffset);
LOG.info("Enqueued Offset :" + _lastEnquedOffset);
if (_lastEnquedOffset > _lastComittedOffset) {
LOG.info("Committing offset for " + _partition);
Map<Object, Object> data =
(Map<Object, Object>) ImmutableMap.builder().put(
"consumer",
ImmutableMap.of("id", _ConsumerId)).put(
"offset",
_emittedToOffset).put("partition", _partition.partition).put(
"broker",
ImmutableMap.of(
"host",
_partition.host.host,
"port",
_partition.host.port)).put("topic", _topic).build();
try {
_state.writeJSON(committedPath(), data);
//增加写入kafka的位置信息
_state.writeBytes(kafkaConsumerCommittedPath(), _emittedToOffset.toString().getBytes());
LOG.info("Wrote committed offset to ZK: " + _emittedToOffset);
_waitingToEmit.clear();
_lastComittedOffset = _emittedToOffset;
} catch (Exception zkEx) {
LOG.error("Error during commit. Let wait for refresh "
+ zkEx.getMessage());
}
LOG.info("Committed offset "
+ _lastComittedOffset
+ " for "
+ _partition
+ " for consumer: "
+ _ConsumerId);
// _emittedToOffset = _lastEnquedOffset;
} else {
LOG.info("Last Enqueued offset "
+ _lastEnquedOffset
+ " not incremented since previous Comitted Offset "
+ _lastComittedOffset
+ " for partition "
+ _partition
+ " for Consumer "
+ _ConsumerId
+ ". Some issue in Process!!");
}
}
//获得kafka的consumer路径
private String kafkaConsumerCommittedPath(){
return "/consumers"
+ "/"
+ _stateConf.get(Config.KAFKA_CONSUMER_ID)
+ "/offsets/"
+ _stateConf.get(Config.KAFKA_TOPIC)
+ "/"
+ _partition.getId().substring(_partition.getId().lastIndexOf("_")+1);
}3.2、准备测试环境。
通过 kafka Manager 查看 consumers 情况:
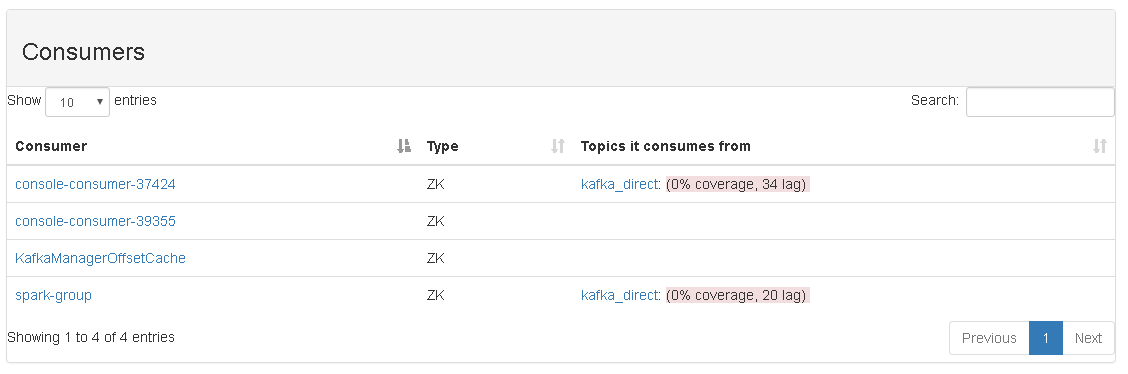
2.4、运行 Spark Streaming + Kafka-spark-consumer 中的 Spark Streaming 程序。
注意:一定要使用自定义的class,否则是没有效果的。我的做法是,将原来jar包中的class删除了,这样就可以保存classpath下只有我们自定义的class了。
再次查看 Kafka Manager 监控程序,如下图:
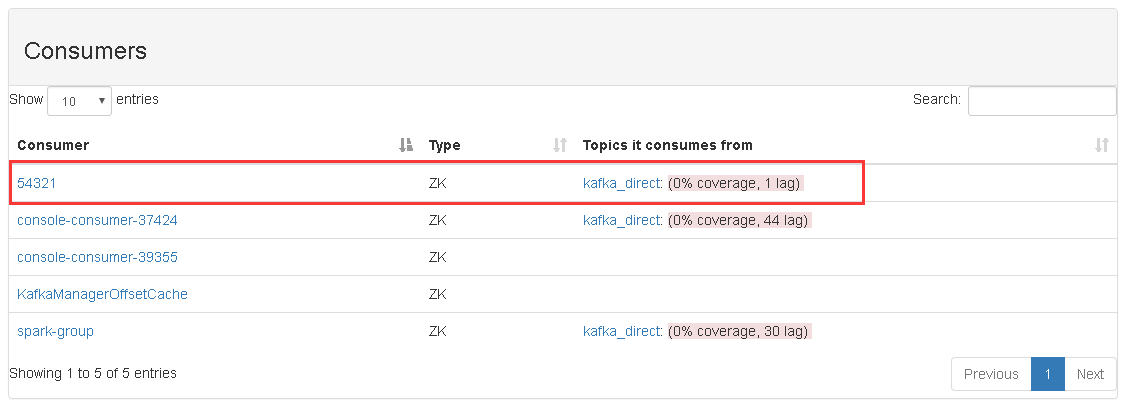
从图片中可以看到,consumer 为 54321 的信息已经显示出来了。















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









