ps auxf|grep redis |grep -v grep|xargs kill -9 杀死所有redis的进程
本文例子是 3对主从,也就是3组分片,也就是3组主从进行分片集群的
步骤1:
cp /usr/local/soft/redis-4.0.6/src/redis-trib.rb /usr/local/redis 先复制edis-trib.rb
步骤2:
1:/usr/local/redis 下新建 clusterconf
6389
为
6379
的从节点,
6390
为
6380
的从节点,
6391
为
6381
的从节点
2
,分别修改
6379
、
6380
、
7381
、
6389
、
6390
、
6391
配置文件
port 6379
//
节点端口
cluster-enabled yes
//
开启集群模式
cluster-node-timeout 15000
//
节点超时时间(接收
pong
消息回复的时间)
cluster-config-file /usrlocalbin/cluster/data/nodes-6379.conf
集群内部配置文件
其它节点的配置和这个一致,改端口即可
3
,配置完后,
启动
6
个
redis
服务
4
,
自动安装模式:
在
/usr/local
新建目录:
ruby
下载链接:
https://pan.baidu.com/s/1kWsf3Rh
密码:
n3pc
从这个链接下载
ruby-2.3.1.tar.gz
和
redis-3.3.0.gem
tar -zxvf ruby-2.3.1.tar.gz
a, cd ruby-2.3.1
b, ./configure -prefix=/usr/local/ruby
c, make && make install
//
过程会有点慢,大概
5
-
10
分钟
d,
然后
gem install -l redis-3.3.0.gem //
没有
gem
需要安装
yum install gem
e,
准 备 好
6
个 节 点 ,( 注 意 不 要 设 置
requirepass
)
,
将
/usr/local/bin/clusterconf/data
的
config-file
删 除 ; 依 次 启 动
6 个 节 点:
./redis-server clusterconf/redis6379.conf
如果之前
redis
有数据存在,
flushall
清空;
(
坑
:
不需要
cluster meet ..
)
f,
进入
cd /usr/local/bin,
执行以下:
1
代表从节点的个数
./redis-trib.rb create --replicas 1 192.168.120.129:6379 192.168.120.129:6380 192.168.120.129:6381 192.168.120.129:6389 192.168.120.129:6390 192.168.120.129:6391
执行成功 后,如下
随便进入 一个节点
主从分配,
6379
是
6389
的从节点 查看所有主从
cluster nodes
貌似只有主节点可读写,从节点不可以
主节点死后,从节点变成主节点
e,
集群健康检测:
redis-trib.rb check 192.168.120.129:6379 (注:
redis
先去注释掉
requirepass,不然 连不上
)
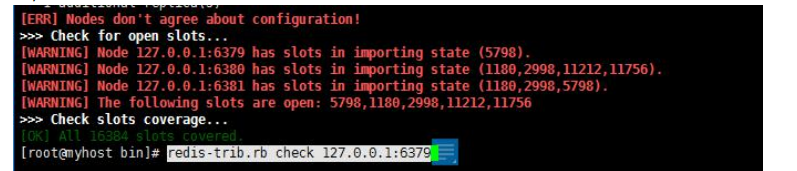
如此出现了这个问题,
6379
的
5798
槽位号被打开了
解决如下:
6379
,
6380
,
6381
的有部分槽位被打开了,分别进入这几个节点,执行
6380:>cluster setslot 1180 stable
cluster setslot 2998 stable
cluster setslot 11212 stable
其它也一样,分别执行修复完后:
此时修复后的健康正常;
当停掉
6379
后,过会
6389
变成主节点
注意:使用客户端工具查询时要加
-c
./redis-cli -h 192.168.120.129 -p 6379
-c
mset aa bb cc dd,
批设置对应在不同的
solt
上,缺点
14,
集群正常启动后,在每个
redis.conf
里加上
masterauth “123456”
requiredpass “123456”
当主节点下线时,从节点会变成主节点,用户和密码是很有必要的,设置成一致
15,
这上面是一主一从,那能不能一主多从呢?

./redis-trib.rb create --replicas 2
192.168.120.129:6379 192.168.120.129:6380 192.168.120.129:6381
192.168.120.129:6479 192.168.120.129:6480 192.168.120.129:6481
192.168.120.129:6579 192.168.120.129:6580 192.168.120.129:6581
5
,集群扩容 (
在没有任何数据下的情况下成功了
)
这也是分布式存储最常见的需求,当我们存储不够用时,要考虑扩容
扩容步骤如下:
A
,准备好新节点
1),
同目录下新增
redis6382.conf
、
redis6392.conf
两
启动两个新
redis
节点
./redis-server clusterconf/redis6382.conf &
(新主节点)
./redis-server clusterconf/redis6392.conf &
(新从节点)
2),
新增主节点
./redis-trib.rb add-node 192.168.120.129:6382 192.168.120.129:6379
6379
是原存在的主节点,
6382
是新的主节点
3),
添加从节点
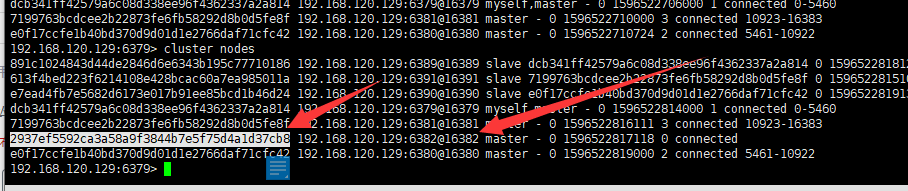
./redis-trib.rb add-node --slave --master-id 2937ef5592ca3a58a9f3844b7e5f75d4a1d37cb8 192.168.120.129:6392 192.168.120.129:6379
--slave
,表示添加的是从节点
--master-id 2937ef5592ca3a58a9f3844b7e5f75d4a1d37cb8 表示主节点
6382
的
进入客户端就可以了看到了输入 cluster nodes
master_id
192.168.120.129:6392,新从节点
192.168.120.129:6379 集群原存在的旧节点
4),./redis-trib.rb reshard 192.168.120.129:6382
//
为新主节点重新分配
solt
How many slots do you want to move (from 1 to 16384)?
1000
//
设置
slot
数
1000
What is the receiving node ID?
2937ef5592ca3a58a9f3844b7e5f75d4a1d37cb8
//新节点 node id
Source node #1:
all
//
表示全部节点重新洗牌
新增完毕!
3
,集群减缩节点:
集群同时也支持节点下线掉
下线的流程如下:
删除节点也分两种:
一种是主节点
6382
,一种是从节点
6392
。
在从节点
6392
中,没有分配哈希槽,执行
./redis-trib.rb del-node 192.168.120.129:6392
2937ef5592ca3a58a9f3844b7e5f75d4a1d37cb8
有两个参数 ip
:
port
和节点的
id
。 从节点
6392
从集群中删除了。
主节点
6382
删除步骤:
1
,./redis-trib.rb reshard 192.168.120.129:6382
问我们有多少个哈希槽要移走,因为我们这个节点上刚分配了
1000
个所以我们这里输入
1000
2
,最后
./redis-trib.rb del-node 192.168.120.129:6382
2937ef5592ca3a58a9f3844b7e5f75d4a1d37cb8
此时节点下线完成……
解决方法:删除此目录下的.conf文件,并有flushall 和 cluster reset
遇到的问题如下:

错误提示: slot插槽被占用了(这是搭建redis集群前,以前redis的旧数据和配置信息没有清理干净。)
解决方法: 使用redis-cli 登录到每个节点执行 flushall 和 cluster reset 命令就可以了。
登陆客户端命令: redis-cli
清除所有缓冲区命令: flushall
重置redis集群命令: cluster reset
完成后重新使用创建集群的命令即可。
命令:./redis-trib.rb create --replicas 1 192.168.120.129:6379 192.168.120.129:6380 192.168.120.129:6381 192.168.120.129:6389 192.168.120.129:6390 192.168.120.129:6391

注意执行 这种命令./redis-trib.rb 之前 requirepass 和 masterauth 和bind(0.0.0.0也行)要先注释掉。成功之后再打开

然后用命令redis-trib.rb fix 192.168.120.129:6382都fix一遍,然后好了.
测试代码:
@Test
public void testBasic() throws IOException{
Set<HostAndPort> jedisClusterNodes = new HashSet<HostAndPort>();
jedisClusterNodes.add(new HostAndPort("192.168.120.129", 6379));
jedisClusterNodes.add(new HostAndPort("192.168.120.129", 6380));
jedisClusterNodes.add(new HostAndPort("192.168.120.129", 6381));
jedisClusterNodes.add(new HostAndPort("192.168.120.129", 6389));
jedisClusterNodes.add(new HostAndPort("192.168.120.129", 6390));
jedisClusterNodes.add(new HostAndPort("192.168.120.129", 6391));
JedisCluster jc = new JedisCluster(jedisClusterNodes);
jc.set("my:age", "181");
System.out.println("==set successful!!");
String value = jc.get("my:age");
System.out.println(value);
jc.close();
}
成功如下:

在6379端口下没取到,在6380下面取得。说明分片集群成功.
































 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









