






 本文介绍保持Cassandra集群健康的方法,包括健康检查、基本维护(如flush、清理、修复等)、添加和处理节点故障、备份和恢复等操作,还提及SSTable实用工具和维护工具(DataStax OpsCenter和Netflix Priam),以帮助自动完成任务、加快维护并减少错误。
本文介绍保持Cassandra集群健康的方法,包括健康检查、基本维护(如flush、清理、修复等)、添加和处理节点故障、备份和恢复等操作,还提及SSTable实用工具和维护工具(DataStax OpsCenter和Netflix Priam),以帮助自动完成任务、加快维护并减少错误。
在本章中,我们将介绍一些可以保持Cassandra集群健康的方法。我们的目标是提供可用的各种维护任务的概述。由于这些任务的具体过程在发行版之间略有变化,因此您需要确保查阅DataStax文档以了解您正在使用的版本,以确保您不会遗漏任何新步骤。
让我们开始操作hats 吧!
健康检查
您需要寻找一些基本的东西来确保群集中的节点是健康的:
-
使用nodetool status确保所有节点都已启动并报告正常状态。检查每个节点上的负载以确保群集平衡良好。每个机架的节点数量不均匀可能会导致群集不平衡。
-
检查节点上的nodetool tpstats是否有丢弃的消息,尤其是突变,因为这表明数据写入可能会丢失。越来越多的被阻塞的刷新写入器表明该节点正在以比刷新到磁盘更快的速度将数据提取到内存中。这两个条件都表明Cassandra无法跟上负载。与数据库一样,一旦这些问题开始出现,它们往往会继续呈下降趋势。可以改善这种情况的三件事是负载减少,扩展(添加更多硬件)或扩展(添加另一个节点和重新平衡)。
如果这些检查表明存在问题,您可能需要深入挖掘以获取有关正在发生的事情的更多信息:
-
检查日志以查看在ERROR或WARN级别没有任何报告(例如,OutOfMemoryError)。当Cassandra检测到错误或过时的配置设置,未成功完成的操作以及内存或数据存储问题时,会生成警告日志。
-
查看Cassandra节点的cassandra.yaml和cassandra-env.sh文件的配置,以确保它们符合您的预期设置。例如,堆应设置为其建议的8 GB大小。
-
验证密钥空间和表配置设置。例如,频繁的配置错误是在添加新数据中心时忘记更新密钥空间复制策略。
-
除了Cassandra节点的运行状况之外,了解系统的整体运行状况和配置总是有帮助的,包括确保网络连接和网络时间协议(NTP)服务器正常运行。
这些是Cassandra运营商学会寻找的一些最重要的事情。随着您获得自己部署的经验,您可以使用适合您自己环境的其他运行状况检查来扩充此列表。
基本维护
在执行更具影响力的任务之前或之后,您需要执行一些任务。例如,仅在执行刷新后才拍摄快照。因此,在本节中,我们将介绍其中一些基本维护任务。
我们在本章中看到的许多任务在某种程度上有所不同,具体取决于您使用的是虚拟节点还是单个令牌节点。由于vnodes是默认的,我们将主要关注这些节点的维护,但如果您使用单个令牌节点,则提供指针。
flush
要强制Cassandra将其memtables中的数据写入文件系统上的SSTables,可以在nodetool上使用flush命令,如下所示:
$ nodetool flush
如果检查服务器日志,您将看到一系列与此类似的输出语句,每个表存储在节点上一个:
DEBUG [RMI TCP Connection(297)-127.0.0.1] 2015-12-21 19:20:50,794 StorageService.java:2847 - Forcing flush on keyspace hotel, CF reservations_by_hotel_date
您可以通过在命令行上命名来有选择地刷新键空间中的特定键空间甚至特定表:
$ nodetool flush hotel
$ nodetool flush hotel reservations_by_hotel_date hotels_by_poi
运行flush还允许Cassandra清除commitlog段,因为数据已写入SSTables。
nodetool drain命令类似于flush。此命令实际执行刷新,然后指示Cassandra停止侦听来自客户端和其他节点的命令。 drain命令通常用作Cassandra节点的有序关闭的一部分,并帮助节点启动更快地运行,因为没有要重播的提交日志。
清理
cleanup命令扫描节点上的所有数据,并丢弃该节点不再拥有的任何数据。您可能会问为什么节点会拥有它不拥有的任何数据。
假设您已经运行了一段时间,并且您想要更改复制因子或复制策略。如果减少任何数据中心的副本数量,则该数据中心中的节点将不再作为辅助范围的副本。
或者,您可能已向群集添加了节点,并减少了每个节点拥有的令牌范围的大小。然后,每个节点可以包含来自其不再拥有的令牌范围的部分的数据。
在这两种情况下,如果节点在维护过程中出现故障,Cassandra不会立即删除多余的数据。相反,正常的压缩过程最终会丢弃这些数据。
但是,您可能希望更快地回收此多余数据使用的磁盘空间,以减轻群集的压力。为此,您可以使用nodetool cleanup命令。
与flush命令一样,您可以选择清除特定的键空间和表。您不需要自动运行清理,因为如果您已执行前面描述的某个操作,则只需运行它。
修复
正如我们在第6章中讨论的那样,Cassandra的可调一致性意味着群集中的节点可能会随着时间的推移而失去同步。例如,即使某些节点没有响应,一致性级别低于ALL的写入也可能成功,尤其是当群集负载很重时。如果节点因为存储提示的时间窗口关闭或无法访问的时间长,也可能错过突变。结果是,不同分区的不同副本可能具有不同版本的数据。
当错过的突变是缺失时,这尤其具有挑战性。当删除发生并且保持脱机状态的时间超过为相关表定义的gc_grace_秒时,该节点可以在数据重新联机时“恢复”数据。
幸运的是,Cassandra提供了多种反熵机制来帮助缓解不一致性。我们已经讨论了如何使用读取修复和更高的读取一致性级别来提高一致性。 Cassandra武器库的最后一个关键要素是反熵修复或手动修复,我们使用nodetool repair命令执行。
我们可以按如下方式执行基本修复:
$ nodetool repair
[2016-01-01 14:47:59,010] Nothing to repair for keyspace 'hotel'
[2016-01-01 14:47:59,018] Nothing to repair for keyspace 'system_auth'
[2016-01-01 14:47:59,129] Starting repair command #1, repairing
keyspace system_traces with repair options (parallelism: parallel,
primary range: false, incremental: true, job threads: 1,
ColumnFamilies: [], dataCenters: [], hosts: [], # of ranges: 510)
...
当然,这将根据群集的当前状态而有所不同。这个特殊的命令迭代我们集群中的所有键空间和表,修复每个键空间和表。我们还可以通过语法指定特定键空间甚至一个或多个特定表来修复:nodetool repair {<table(s)>}。例如:nodetool repair hotel hotels_by_poi。
可以通过-local选项(也可以通过较长的形式–in-local-dc指定)在本地数据中心中运行修复命令,或者通过-dc 在命名数据中心中运行修复命令。选项(或–in-dc )。
让我们看一下在节点上运行nodetool修复时幕后发生的事情。运行该命令的节点充当请求的协调节点。 org.apache.cassandra.service.ActiveRepairService类负责管理协调器节点上的修复并处理传入的请求。 ActiveRepairService首先执行主要压缩的只读版本,也称为验证压缩。在验证压缩期间,节点检查其本地数据存储并创建包含散列值的Merkle树,该散列值表示正在修复的一个表中的数据。在磁盘I / O和内存使用方面,这部分过程通常很昂贵。
接下来,节点发起TreeRequest / TreeResponse对话以与相邻节点交换Merkle树。如果来自不同节点的树不匹配,则必须对它们进行协调,以确定它们应该被设置为的最新数据值。如果发现任何差异,则节点将数据彼此流式传输以用于不同意的范围。当节点接收要修复的数据时,它会将其存储在SSTable中。
请注意,如果表中有大量数据,Merkle树的分辨率将不会下降到单个分区。例如,在具有一百万个分区的节点中,Merkle树的每个叶节点将代表大约30个分区。即使只有一个分区需要修复,也必须对每个分区进行流式处理。这种行为被称为过度夸大。由于这个原因,该过程的流式传输部分在网络I / O方面通常很昂贵,并且可能导致实际上不需要修复的数据的重复存储。
对于每个包含的密钥空间和表,在每个节点上重复此过程,直到集群中的所有令牌范围都已修复为止。
虽然维修可能是一项昂贵的操作,但Cassandra提供了多种选项,可以灵活地分配工作。
全面修复,增量修复和抗压实
在2.1之前的Cassandra版本中,执行修复意味着节点中的所有SSTable都在修复中进行检查,现在称为完全修复。 2.1版本引入了增量修复。通过增量修复,已修复的数据与尚未修复的数据分离,这一过程称为反压缩。
这种增量方法可以提高修复过程的性能,因为每次修复时搜索的SSTable都会减少。 此外,缩减搜索意味着更少的分区在范围内,导致更小的Merkle树和更少的过度注意。
Cassandra为每个SSTable文件添加了一些元数据,以便跟踪其修复状态。 您可以使用sstablemetadata工具查看修复时间。 例如,检查我们酒店数据的SSTable表示其中包含的数据尚未修复:
$ tools/bin/sstablemetadata data/data/hotel/
hotels-d089fec0677411e59f0ba9fac1d00bce/ma-5-big-Data.db
SSTable: data/data/hotel/hotels-d089fec0677411e59f0ba9fac1d00bce/ma-5-big
Partitioner: org.apache.cassandra.dht.Murmur3Partitioner
Bloom Filter FP chance: 0.010000
Minimum timestamp: 1443619302081305
Maximum timestamp: 1448201891587000
SSTable max local deletion time: 2147483647
Compression ratio: -1.0
Estimated droppable tombstones: 0.0
SSTable Level: 0
Repaired at: 0
ReplayPosition(segmentId=1449353006197, position=326)
Estimated tombstone drop times:
2147483647: 37
...
增量修复成为2.2版本中的默认修复,您必须使用-full选项来请求完全修复。如果您使用的是2.2之前的Cassandra版本,请务必参阅发行文档,以了解准备群集以进行增量修复的任何其他步骤。
顺序和并行修复
顺序修复一次修复一个节点,而并行修复同时修复具有相同数据的多个节点。顺序修复是2.1版本的默认修复,并行修复成为2.2版本中的默认修复。
使用-seq选项启动顺序修复时,将在协调器节点和每个副本节点上获取数据快照,并使用快照构建Merkle树。按顺序在协调器节点和每个副本之间执行修复。在连续修复期间,Cassandra的动态探测器有助于保持性能。由于未主动参与当前修复的副本能够更快地响应请求,因此动态小报将倾向于将请求路由到这些节点。
使用-par选项启动并行修复。在并行修复中,所有副本都同时参与修复,不需要快照。与顺序修复相比,并行修复在集群上的负载更加密集,但也可以更快地完成修复。
分区范围修复
在节点上运行修复时,默认情况下,Cassandra会修复节点为副本的所有令牌范围。这适用于您有一个需要修复的节点的情况 - 例如,已经关闭并准备重新联机的节点。
但是,如果您按照建议对预防性维护进行定期维修,则修复每个节点的所有令牌范围意味着您将对每个范围进行多次修复。因此,nodetool repair命令提供-pr选项,该选项允许您仅修复主令牌范围或分区器范围。如果修复每个节点的主要范围,整个环将被修复。
子修复
即使使用-pr选项,修复仍然可能是一项昂贵的操作,因为节点的主要范围可能代表大量数据。出于这个原因,Cassandra通过将节点的令牌范围分成更小的块来支持修复的能力,这个过程称为子范围修复。
子修复也解决了过度兴奋的问题。由于Merkle树的全分辨率应用于较小的范围,因此Cassandra可以精确识别需要修复的各个行。
要启动子范围修复操作,您将需要要修复的范围的起始标记(-st)和结束标记(-et)。
$ nodetool repair -st <start token> -et <end token>
您可以通过DataStax Cassandra驱动程序以编程方式获取范围的标记。 例如,Java驱动程序提供操作以获取给定主机和键空间的令牌范围,并将令牌范围拆分为子范围。 您可以使用这些操作来自动化每个子范围的修复请求,或者只打印范围,就像我们在此示例中所做的那样:
for (Host host : cluster.getMetadata().getAllHosts())
{
for (TokenRange tokenRange :
cluster.getMetadata().getTokenRanges("hotel", host))
{
for (TokenRange splitRange : tokenRange.splitEvenly(SPLIT_SIZE))
{
System.out.println("Start: " + splitRange.getStart().getValue() +
", End: " + splitRange.getEnd().getValue());
}
}
}
使用子范围修复的类似算法由OpsCenter修复服务实现,我们将立即检查。
在实践中,选择和执行适当的修复策略是维护Cassandra集群中比较困难的任务之一。这是一份帮助指导您做出决策的清单:
-
修复频率
请记住,应用程序将遵循的数据一致性取决于您使用的读写一致性级别,还取决于您实施的修复策略。如果您愿意使用不保证即时一致性的读/写一致性级别,则需要进行更频繁的修复。
-
修理计划
通过在应用程序的非高峰时间安排修复对应用程序的影响,最大限度地减少修复对应用程序的影响。或者,通过在不同的开始时间对各种键空间和表使用子范围修复或交错修复来扩展该过程。
-
需要维修的操作
不要忘记某些操作 - 例如更改群集上的snitch或更改键空间上的复制因子 - 将需要完全修复。
-
避免相互冲突的维修
Cassandra不允许在给定的令牌范围内进行多个同时修复,因为定义修复涉及节点之间的交互。因此,最好从群集外部的单个位置管理修复,而不是尝试在每个节点上实施自动化流程来修复其本地拥有的范围。
在建立更强大的修复状态机制之前(例如,参见JIRA问题CASSANDRA-10302),您可以使用nodetool netstats监视正在进行的修复。
重建索引
如果您正在使用二级索引,它们可能会像其他任何数据一样失去同步。虽然Cassandra确实将二级索引存储为幕后的表,但索引表仅引用存储在本地节点上的值。因此,Cassandra的修复机制无法使索引保持最新状态。
由于无法修复二级索引,并且没有简单的方法来检查其有效性,因此Cassandra提供了使用nodetool的rebuild_index命令从头开始重建它们的功能。在修复它所基于的表之后重建索引是个好主意,因为索引所基于的列可以在修复的值中表示。与修复一样,请记住重建索引是CPU和I / O密集型过程。
移动令牌
如果您已将群集配置为使用vnodes(自2.0版本以来一直是默认配置),Cassandra会处理为群集中的每个节点分配令牌范围。 这包括在从群集添加或删除节点时更改这些分配。 但是,如果您使用单个令牌节点,则需要手动重新配置令牌。
为此,首先需要使用第7章中描述的技术重新计算每个节点的令牌范围。然后我们使用nodetool move命令来分配范围。 move命令采用单个参数,该参数是节点的新起始标记:
$ nodetool move 3074457345618258600
调整每个节点的令牌后,通过在每个节点上运行nodetool cleanup来完成该过程。
添加节点
我们在第7章中简要介绍了如何使用Cassandra Cluster Manager(ccm)添加节点,这是我们快速入门的好方法。现在让我们深入探讨一下添加新节点和数据中心的一些动机和程序。
将节点添加到现有数据中心
如果您的应用程序成功,迟早您将到达需要向群集添加节点的位置。这可能是计划增加容量的一部分,或者它可能是对您在运行状况检查中观察到的某些内容的反应,例如存储空间不足,或者内存和CPU利用率较高的节点,或者增加读取并写下延迟。
无论您的扩展动机如何,您都将首先在将承载新节点的计算机上安装和配置Cassandra。该过程类似于我们在第7章中概述的过程,但请记住以下几点:
- Cassandra版本必须与群集中的现有节点相同。如果要进行版本升级,请先将现有节点升级到新版本,然后再添加新节点。
- 您将要使用与cassandra.yaml和cassandra-env.sh等文件中的其他节点相同的配置值,包括cluster_name,dynamic_snitch,partitioner和listen_address。
- 使用与其他节点中相同的种子节点。通常,您添加的新节点不是种子节点,因此无需将新节点添加到先前存在的节点中的种子列表中。
- 如果您的配置中有多个机架,则最好同时向每个机架添加节点,以保持每个机架中的节点数量平衡。出于某种原因,这总是让我想起经典的棋盘游戏Monopoly中的规则,要求房屋在房产中均匀分布。
- 如果您正在使用单个令牌节点,则必须手动计算将分配给每个节点的令牌范围,如我们在“移动令牌”中所述。保持群集平衡的一种简单有效的方法是将每个令牌范围分成两半,使群集中的节点数量增加一倍。
- 在大多数情况下,您需要配置新节点以立即开始引导 - 即声明令牌范围并从其他节点流式传输这些范围的数据。这由autobootstrap属性控制,默认为true。您可以将其添加到cassandra.yaml文件中以显式启用或禁用自动引导。
配置节点后,您可以启动它们,并使用nodetool status来确定它们何时完全初始化。
您还可以通过运行nodetool bootstrap命令来查看节点上的引导操作的进度。如果您已启动禁用自动引导的节点,则还可以在选择命令nodetool bootstrap resume时远程启动引导。
在所有新节点运行之后,请确保在每个先前存在的节点上运行nodetool cleanup以清除不再由这些节点管理的数据。
将数据中心添加到群集
您可能希望向群集添加全新数据中心的原因有多种。例如,假设您正在将应用程序部署到新的数据中心,以减少新市场中客户端的网络延迟。或者,您可能需要主动 - 主动配置才能支持应用程序的灾难恢复要求。第三个流行的用例是创建一个可用于分析的独立数据中心,而不会影响在线客户交易。
我们将在第14章进一步探讨其中的一些部署,但现在让我们关注如何将集群扩展到新的数据中心。
我们在现有数据中心中添加节点所遵循的相同基本步骤适用于在新数据中心中添加节点。在为每个节点配置cassandra.yaml文件时,您需要考虑以下一些其他事项:
- 确保使用endpoint_snitch属性和与snitch关联的任何配置文件为部署环境配置适当的snitch。希望您在首次设置群集时进行此计划,但如果没有,则需要更改初始数据中心中的snitch。如果确实需要更改告警,则首先要在现有数据中心的节点上更改它,并在添加新数据中心之前执行修复。
- 选择新数据中心中的几个节点作为种子,并相应地配置其他节点中的种子属性。每个数据中心都应拥有独立于其他数据中心的种子。
- 新数据中心不需要具有与群集中任何现有数据中心相同的令牌范围配置。如果需要,您可以选择不同数量的vnode或使用单令牌节点。
- 通过查找(或添加)autobootstrap选项并将其设置为false来禁用自动引导。这将阻止我们的新节点在准备好之前尝试流式传输数据。
在新数据中心中的所有节点都联机后,您可以为要复制到新数据中心的所有键空间配置NetworkTopologyStrategy的复制选项。
例如,要将我们的酒店密钥空间扩展到其他数据中心,我们可能会执行以下命令:
cqlsh> ALTER KEYSPACE hotel WITH REPLICATION =
{'class' : 'NetworkTopologyStrategy', 'dc1' : 3, 'dc2' : 2};
请注意,NetworkTopologyStrategy允许我们为每个数据中心指定不同数量的副本。
接下来,在新数据中心的每个节点上运行nodetool rebuild命令。 例如,以下命令使节点通过从数据中心dc1流式传输来重建其数据:
$ nodetool rebuild -- dc1
如果需要,您可以并行重建多个节点;在执行此操作之前,请记住考虑对群集的影响。
重建完成后,您的新数据中心即可使用。不要忘记为新数据中心中的每个节点重新配置cassandra.yaml文件以删除autobootstrap:false选项,以便在重新启动时节点将成功恢复。
您还需要考虑添加另一个数据中心如何影响现有客户端以及它们对LOCAL_ *和EACH_ *一致性级别的使用。例如,如果客户端使用QUORUM一致性级别进行读取或写入,那么过去仅限于单个数据中心的查询现在将涉及多个数据中心。您可能希望切换到LOCAL_QUORUM以限制延迟,或者切换到EACH_QUORUM以确保每个数据中心的强一致性。
处理节点故障
有时,Cassandra节点可能会失败。可能由于各种原因而发生故障,包括:硬件故障,崩溃的Cassandra进程或已停止或销毁的虚拟机。遇到网络连接问题的节点可能会在八卦中标记为失败,并在nodetool状态下报告为down,但如果连接性改善,它可能会重新联机。
在本节中,我们将研究如何修复或替换故障节点,以及如何从群集中正常删除节点。
修复节点
当您观察到失败的节点时,首先要做的是尝试确定节点已关闭多长时间。这是一个快速的经验法则,知道是否需要维修或更换:
- 如果节点已经关闭小于max_hint_window_in_ms属性指定的提示传递窗口,则提示的切换机制应该能够恢复节点。重新启动节点,看它是否能够恢复。您可以使用nodetool status查看节点的日志或跟踪其进度。
- 如果节点已经关闭少于修复窗口,为其任何包含的表定义了最低值gc_grace_seconds,则重新启动该节点。如果成功启动,请运行nodetool修复。
- 如果节点已经关闭的时间长于修复窗口,则应该更换它,以避免墓碑复活。
从磁盘故障中恢复
磁盘故障是节点可以从中恢复的一种形式的硬件故障。如果您的节点配置为使用具有多个磁盘(JBOD)的Cassandra,则disk_failure_policy设置将确定磁盘发生故障时采取的操作以及您可以如何检测故障:
- 如果策略设置为默认值(停止),则节点将停止闲聊,这将使其在nodetool状态下显示为已关闭的节点。您仍然可以通过JMX连接到节点。
- 如果策略设置为die,则JVM退出,节点将在nodetool状态中显示为已关闭的节点。
- 如果策略设置为忽略,则无法立即检测到故障。
- 如果策略设置为best_effort,则Cassandra将继续使用其他磁盘运行,但会写入WARN日志条目,如果您使用的是日志聚合工具,则可以检测该日志条目。或者,您可以使用JMX监视工具来监视org.apache.cassandra.db.BlacklistedDirectories MBean的状态,该状态列出了节点记录失败的目录。
- 如果在节点启动时检测到磁盘故障且策略是best_effort之外的任何内容,则该节点会写入ERROR日志条目并退出。
一旦检测到磁盘故障,您可能需要尝试重新启动Cassandra进程或重新启动服务器。但是如果故障仍然存在,则必须更换磁盘并删除其余磁盘中的数据/系统目录的内容,以便在重新启动节点时,它会以一致的状态出现。节点启动时,运行修复。
替换节点
如果您确定无法修复节点,则很可能需要更换节点以保持群集平衡并保持相同的容量。
虽然我们可以通过删除旧节点(如下一节)和添加新节点来替换节点,但这不是一种非常有效的方法。删除然后添加节点会导致过多的数据流,首先将数据从旧节点移开,然后再将其移回新节点。
更有效的方法是添加一个接管现有节点的令牌范围的节点。为此,我们遵循先前概述的添加节点的过程,并添加一个节点。编辑新节点的cassandra-env.sh文件以添加以下JVM选项(其中
是要替换的节点的IP地址或主机名):JVM_OPTS="$JVM_OPTS -Dcassandra.replace_address=<address>"
替换节点完成引导后,您可以删除此选项,因为后续重新启动节点不需要此选项。
如果您使用的是使用属性文件记录集群拓扑的snitch,例如GossipingPropertyFileSnitch或PropertyFileSnitch,则需要将新节点的地址添加到每个节点上的属性文件中并执行滚动重新启动集群中的节点建议您在删除旧节点的地址之前等待72小时,以免混淆闲聊。
如果要替换的节点是种子节点,请选择现有的非种子节点以提升到种子节点。您需要将提升的种子节点添加到现有节点的cassandra.yaml文件中的seeds属性。
通常,这些将是同一数据中心中的节点,假设您遵循每个数据中心使用不同种子列表的建议。这样,我们创建的新节点将是非种子节点,并且可以正常引导。
如果您使用Cassandra的软件包安装,还有一些其他细节;有关其他详细信息,请参阅特定版本的文档。
删除节点
如果您决定不立即更换已关闭的节点,或者只是想缩小群集的大小,则需要删除或停用该节点。正确的删除技术取决于被删除的节点是在线还是能够联机。我们将按照偏好顺序查看三种技术:退役,删除和暗杀。
退役节点
如果节点报告为up,我们将停用该节点。停用节点意味着将其停止服务。执行nodetool decommission命令时,您将在Cassandra的StorageService类上调用decommission操作。退役操作将节点负责的令牌范围分配给其他节点,然后将数据流式传输到这些节点。这实际上与自举操作相反。
当退役正在运行时,节点将通过代码UL(向上,离开)报告它处于nodetool状态的离开状态:
$ nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID Rack
UN 127.0.0.1 340.25 KB 256 ? 31d9042b-6603-4040-8aac-... rack1
UN 127.0.0.2 254.31 KB 256 ? caad1573-4157-43d2-a9fa-... rack1
UN 127.0.0.3 259.45 KB 256 ? e78529c8-ee9f-46a4-8bc1-... rack1
UL 127.0.0.4 116.33 KB 256 ? 706a2d42-32b8-4a3a-85b7-... rack1
您可以检查已停用节点的服务器日志以查看进度。 例如,您将看到一系列这样的语句,表示每个令牌范围的新主页:
DEBUG [RMI TCP Connection(4)-127.0.0.1] 2016-01-07 06:00:20,923
StorageService.java:2369 - Range (-1517961367820069851,-1490120499577273657]
will be responsibility of /127.0.0.3
在此之后,您将看到另一个日志语句,指示将数据流传输到其他节点的开始:
INFO [RMI TCP Connection(4)-127.0.0.1] 2016-01-07 06:00:21,274
StorageService.java:1191 - LEAVING: replaying batch log and
streaming data to other nodes
您还可以使用nodetool netstats来监视数据流到新副本的进度。
当流式传输完成时,节点宣布其离开群集的其余部分30秒,然后停止:
INFO [RMI TCP Connection(4)-127.0.0.1] 2016-01-07 06:00:22,526
StorageService.java:3425 - Announcing that I have left the ring for 30000ms
...
WARN [RMI TCP Connection(4)-127.0.0.1] 2016-01-07 06:00:52,529
Gossiper.java:1461 - No local state or state is in silent shutdown, not
announcing shutdown
Finally, the decommission is complete:
INFO [RMI TCP Connection(4)-127.0.0.1] 2016-01-07 06:00:52,662
StorageService.java:1191 - DECOMMISSIONED
如果您在无法解除授权的节点上调用decommission(即,尚未退出的节点,或在唯一可用的节点上),您将看到相应的错误消息。
请注意,数据不会自动从已停用的节点中删除。如果您决定要将先前已停用的节点重新引入具有不同范围的环中,则需要先手动删除其数据。
删除节点
如果节点已关闭,则必须使用nodetool removenode命令而不是停用。如果您的群集使用vnode,则removenode命令会导致Cassandra重新计算剩余节点的新令牌范围,并将数据从当前副本流式传输到每个令牌范围的新所有者。
如果您的群集不使用vnode,则在运行removenode以执行流式传输之前,您需要手动调整分配给每个剩余节点的令牌范围(如“移动令牌”中所述)。 removenode命令还提供 - 状态选项,以允许您监视流式传输的进度。
大多数nodetool命令直接在通过-h标志标识的节点上运行。 removenode命令的语法略有不同,因为它必须在不被删除的节点上运行。目标节点通过其主机ID识别,而不是IP地址,您可以通过nodetool status命令获取该主机ID:
$ nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns Host ID
UN 127.0.0.1 244.71 KB 256 ? 31d9042b-6603-4040-8aac-fef0a235570b
UN 127.0.0.2 224.96 KB 256 ? caad1573-4157-43d2-a9fa-88f79344683d
DN 127.0.0.3 230.37 KB 256 ? e78529c8-ee9f-46a4-8bc1-3479f99a1860
$ nodetool removenode e78529c8-ee9f-46a4-8bc1-3479f99a1860
暗杀一个节点
如果nodetool removenode操作失败,您还可以运行nodetool assassinate作为最后的手段。 assassinate命令与removenode类似,不同之处在于它不会重新复制已删除节点的数据。 这使您的群集处于需要修复的状态。
与removenode的另一个关键区别是assassinate命令使用节点的IP地址来暗杀,而不是主机ID:
$ nodetool assassinate 127.0.0.3
每当删除种子节点时,请确保更新其余节点上的cassandra.yaml文件以删除已删除的节点的IP地址。您还需要确保仍有足够数量的种子节点(每个数据中心至少有两个)。
升级卡桑德拉
由于Cassandra是一种不断发展壮大的技术,因此可以定期提供新版本,提供新功能,改进性能和修复错误。就像Apache社区已经为其常规版本建立节奏一样,您也需要计划采用这些版本。
在选择Cassandra版本时,你会想要避免“太热”和“太冷”的极端情况。
例如,最好避免在首次发布时部署主要版本号版本。从历史上看,主要的新功能在首次发布时往往不稳定,您可能不希望自愿生产系统以帮助解决问题。
另一方面,您也不希望太过落后,因为等待的时间越长,升级路径就会变得越来越复杂。当新版本中经常提供修复时,Cassandra电子邮件列表存档充斥着针对旧版本提出的问题和问题。
当您确定升级时间时,请务必查阅新版本的基本目录中的NEWS.txt文件,并按照当前版本和新版本之间的版本升级说明进行操作。升级可能是一个复杂的过程,如果不仔细遵循说明,很容易对集群造成大量损害。
您还应该查阅DataStax发布的整体升级指南。本指南提供了升级过程的完美概述,以及为了更新各种版本而需要的任何中间升级的摘要。
Cassandra集群通过称为滚动升级的过程进行升级,因为每个节点一次升级一个。要执行滚动升级,请使用以下步骤:
- 首先,在节点上运行nodetool drain以清除仍需要刷新到磁盘并停止接收新写入的任何写入。
- 停止节点。
- 制作配置文件的备份副本,例如cassandra.yaml和cassandra-env.sh,这样它们就不会被覆盖。
- 安装新版本。
- 更新配置文件以匹配您的特定部署。
如果您要升级您的Cassandra版本,您可能会尝试重用之前部署中的cassandra.yaml。这种方法的问题在于大多数版本都提供了一些额外的配置选项。此外,配置参数的默认值偶尔会发生变化。在这两种情况下,您都无法利用这些更改。如果你进行了重大的跳跃,那么Cassandra甚至可能无法正常使用你的旧配置文件。
升级的最佳实践是从新版本附带的cassandra.yaml文件开始,并从旧配置文件(例如群集名称,种子列表和分区程序)合并您为环境所做的自定义更改。请记住,无法在包含数据的群集上更改分区程序。
如果您使用的是基于Unix的系统,通常可以通过使用diff命令识别更改来手动完成合并。或者,您可以使用源代码配置工具或集成开发环境(IDE)提供的合并工具。
升级主版本号(以及一些次要版本升级)要求您运行nodetool upgradesstables命令以将存储的数据文件转换为最新格式。与我们检查的其他nodetool命令一样,您可以在要升级的键空间中指定键空间甚至表,但通常您需要升级所有节点的表。您还可以通过bin / sstableupgrade脚本在节点脱机时更新节点的表。
对群集中的每个节点重复这些步骤。尽管在滚动升级过程中群集仍然可以运行,但您应该仔细规划升级计划,同时考虑群集的大小。虽然群集仍在升级,但您应该避免进行架构更改或运行任何修复。
备份和恢复
Cassandra具有高度的故障恢复能力,支持可配置的复制和多个数据中心。但是,备份数据仍有很多好的理由:
- 应用程序逻辑中的缺陷可能导致良好的数据被覆盖并在情况变为已知之前复制到所有节点。
- SSTables可能会损坏。
- 多数据中心故障可能会消除您的灾难恢复计划。
Cassandra提供了两种备份数据的机制:快照和增量备份。快照提供完整备份,而增量备份提供了一次备份更改的方法。
数据库备份方法通常采用以下三种形式之一:
- 完整备份包括数据库的整个状态(或数据库中的特定表),并且创建成本最高。
- 增量备份包括一段时间内所做的更改,通常是自上次增量备份以来的时间段。总之,一系列增量备份提供差异备份。
- 差异备份包括自上次完全备份以来所做的所有更改。
请注意,Cassandra不提供内置的差异备份机制,而是专注于完全备份和增量备份。
Cassandra的快照和备份是互补技术,它们一起用于支持强大的备份和恢复方法。
快照和备份机制都会创建到SSTable文件的硬链接,从而避免在短期内创建额外的文件。但是,随着压缩的发生,这些文件会随着时间的推移而累积,并且仍然通过硬链接保留从数据目录中删除的文件。
将这些文件复制到另一个位置并删除它们以便它们不填满磁盘空间的任务留给用户。但是,这些任务很容易实现自动化,并且有各种支持它的工具,例如DataStax OpsCenter,我们将暂时介绍它们。开源示例是Jeremy Grosser的Tablesnap。
拍摄快照
快照的目的是复制节点中的部分或全部键空间和表,并将其保存到本质上是单独的数据库文件中。这意味着您可以将密钥空间备份到其他位置或将它们留在原地,以防您以后需要还原它们。拍摄快照时,Cassandra首先执行刷新,然后为每个SSTable文件创建一个硬链接。
拍摄快照非常简单:
$ nodetool snapshot
Requested creating snapshot(s) for [all keyspaces] with snapshot name
[1452265846037]
Snapshot directory: 1452265846037
这里,已经为服务器上的所有键空间拍摄了快照,包括Cassandra的内部系统键空间。 如果只想指定一个键空间来拍摄快照,可以将其作为附加参数传递:nodetool snapshot hotel。 或者,您可以使用-cf选项列出特定表的名称。
我们可以列出使用nodetool listsnapshots命令拍摄的快照:
$ nodetool listsnapshots
Snapshot name Keyspace name Column family name True size Size on disk
1452265846037 hotel pois_by_hotel 0 bytes 13 bytes
1452265846037 hotel hotels 0 bytes 13 bytes
...
Total TrueDiskSpaceUsed: 0 bytes
要在文件系统上查找这些快照,请记住数据目录的内容是在键空间和表的子目录中组织的。每个表的目录下都有一个snapshots目录,每个快照都存储在一个目录中,该目录以获取它的时间戳命名。例如,我们可以在以下位置找到酒店表快照:
$CASSANDRA_HOME/data/data/hotel/hotels-b9282710a78a11e5a0a5fb1a2fbefd47/snapshots/1452265846037/
每个快照还包含一个manifest.json文件,该文件列出了快照中包含的SSTable文件。这用于确保存在快照的全部内容。
nodetool snapshot命令仅在单个服务器上运行。如果您需要使用并行ssh工具(如pssh)进行时间点快照,则需要在多个服务器上同时运行此命令。
Cassandra还提供自动快照功能,可在每个DROP KEYSPACE,DROP TABLE或TRUNCATE操作上获取快照。默认情况下,此功能通过cassandra.yaml文件中的auto_snapshot属性启用,以防止意外数据丢失。还有一个属性snapshot_before_compaction,默认为false。
清除快照
您还可以删除您在其他地方备份到永久存储后所创建的任何快照。在创建新快照之前删除旧快照是个好主意。
要清除快照,可以手动删除文件,或使用nodetool clearsnapshot命令,该命令采用可选的键空间选项。
启用增量备份
执行快照后,可以使用nodetool enablebackup命令启用Cassandra的增量备份。此命令适用于节点中的所有键空间和表。
您还可以检查是否使用nodetool statusbackup启用增量备份,并使用nodetool disablebackup禁用增量备份。
启用增量备份后,Cassandra会在将SSTables刷新到磁盘的过程中创建备份。备份包含Cassandra在备份目录下写入的每个数据文件的硬链接 - 例如:
$CASSANDRA_HOME/data/data/hotel/hotels-b9282710a78a11e5a0a5fb1a2fbefd47/backups/
要在重新启动节点时启用备份,请在cassandra.yaml文件中将incremental_backups属性设置为true。
执行快照并将快照保存到永久存储后,可以安全地清除增量备份。
从快照恢复
从备份还原节点的过程从收集最新快照以及自快照以来的任何增量备份开始。来自快照和备份的数据文件的处理方式没有区别。
在节点上开始还原操作之前,您很可能希望截断表以清除自快照以来所做的任何数据更改。
请注意,Cassandra不会将数据库架构作为快照和备份的一部分。在执行任何还原操作之前,您需要确保架构已就绪。幸运的是,这很容易使用cqlsh的DESCRIBE TABLES操作,可以很容易地编写脚本。
如果您的群集拓扑与拍摄快照的时间相同,则每个节点的令牌范围都没有更改,并且对于相关表的复制因子没有更改,您可以将SSTable数据文件复制到每个节点的数据目录。如果节点已在运行,则运行nodetool refresh命令将导致Cassandra加载数据。
如果拓扑,令牌范围或复制发生了更改,则需要使用名为sstableloader的工具来加载数据。在某些方面,sstableloader的行为类似于Cassandra节点:它使用八卦协议来了解集群中的节点,但它不会将自身注册为节点。它使用Cassandra的流式库将SSTable推送到节点。 sstableloader不会将SSTable文件直接复制到每个节点,而是将每个SSTable中的数据插入到集群中,从而允许集群的分区程序和复制策略完成其工作。
sstableloader对于在集群之间移动数据也很有用。
SSTable Utilities
bin和tools / bin目录中有几个实用程序,它们直接在Cassandra节点的文件系统上的SSTable数据文件上运行。这些文件的扩展名为.db。例如:
$CASSANDRA_HOME/data/hotels-b9282710a78a11e5a0a5fb1a2fbefd47/ma-1-big-Data.db
除了我们已经看到的sstablemetadata,sstableloader和sstableupgrade工具之外,还有一些其他SSTable实用程序:
- sstableutil实用程序将列出提供的表名的SSTable文件。
- sstablekeys实用程序列出了存储在给定SSTable中的分区键。
- sstableverify实用程序将验证SSTable文件以获取提供的密钥空间和表名,以识别出现错误或数据损坏的任何文件。这是nodetool verify命令的脱机版本。
- sstablescrub实用程序是nodetool scrub命令的脱机版本。由于它脱机运行,因此可以更有效地从SSTable文件中删除损坏的数据。如果该工具删除任何损坏的行,则需要运行修复。
- sstablerepairedset用于将特定SSTable标记为已修复或未修复,以便将节点转换为增量修复。由于增量修复是2.2版本的默认修复,因此在2.2或更高版本上创建的群集将不需要使用此工具。
一些实用程序有助于管理压缩,我们将在第12章进一步研究:
- sstableexpiredblockers实用程序将显示阻止SSTable被阻止的阻塞SSTable。此类输出阻止其他SSTable被删除的所有SSTable,以便您可以确定给定SSTable仍在磁盘上的原因。
- sstablelevelreset实用程序将在给定的一组SSTable上将级别重置为0,这将强制SSTable作为下一个压缩操作的一部分进行压缩。
- sstableofflinerelevel实用程序将使用LeveledCompactionStrategy为表重新分配SSTable级别。当快速摄取大量数据时(例如批量导入),这非常有用。
- sstablesplit实用程序用于将SSTables文件拆分为多个指定大小的SSTable。如果主要压缩生成了大型表,否则这将很长时间不会被压缩,这非常有用。
在正常情况下,您可能不需要经常使用这些工具,但它们在调试和获得对Cassandra数据存储的工作原理方面非常有用。当Cassandra未在本地主机上运行时,必须运行修改SSTables的实用程序,如sstablelevelreset,sstablerepairedset,sstablesplit,sstableofflinerelevel。
维护工具
虽然完全可以通过nodetool维护Cassandra集群,但许多组织,特别是安装较大的组织,发现使用提供自动维护功能和改进可视化的高级工具很有帮助。
让我们快速浏览一下这两个工具提供的功能:DataStax OpsCenter和Netflix Priam。
DataStax OpsCenter
DataStax OpsCenter是Cassandra基于Web的管理和监控解决方案,可自动执行维护任务,包括本章中讨论的维护任务。 OpsCenter有两个版本:免费的Community Edition,它管理基于Apache Cassandra发行版的集群,以及企业版,它管理DataStax Enterprise集群。
OpsCenter的核心是仪表板,它提供了群集运行状况的即时可视摘要,如图11-1所示。
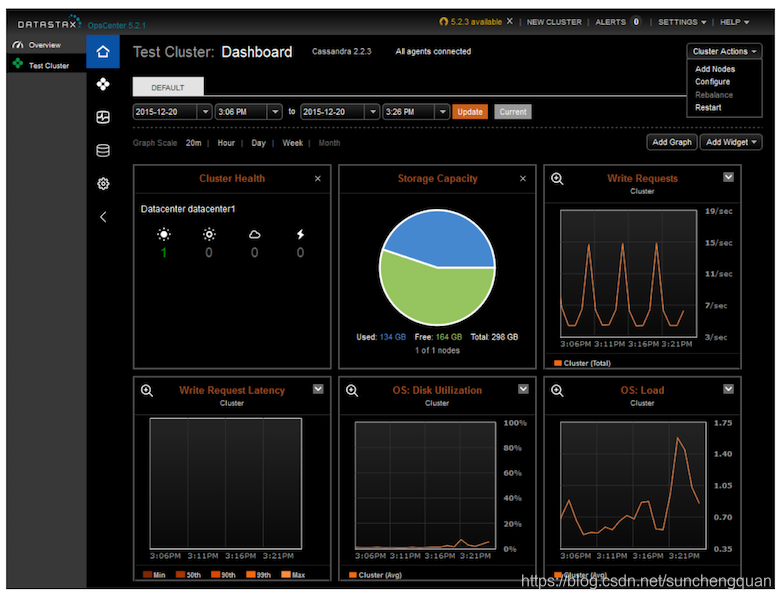
除了群集运行状况,仪表板还包括跟踪容量和写入延迟的指标。您可以自定义仪表板以添加图表,以监控Cassandra通过JMX报告的许多其他指标。企业版还允许您配置这些指标的阈值,以生成警报和电子邮件通知。
可在群集上执行的操作显示在图的右上角,包括添加节点,为所有节点配置cassandra.yaml设置以及重新启动群集。还有一个“重新平衡”命令,可用于在不使用vnode的群集中自动重新分配令牌范围。
DataStax Enterprise Edition还提供了一个修复服务,可以自动修复整个群集。修复服务持续运行,使用增量修复来修复群集的子范围。修复服务会监视这些子范围修复的进度并限制其修复,以最大限度地减少对群集的影响。修复所有子范围后,将启动新的修复周期。
OpsCenter节点视图以环形配置提供群集中节点的有用图形表示,如图11-2所示。
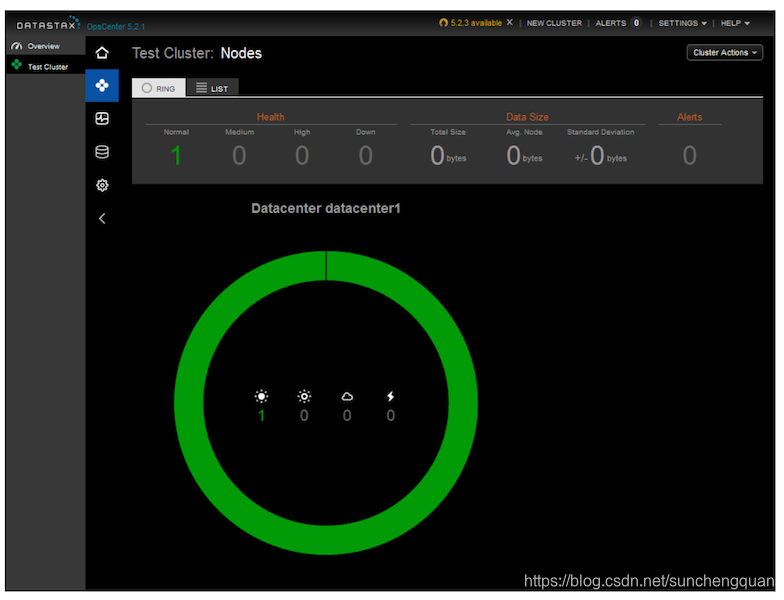
从节点视图中,我们可以通过其在环上的位置选择单个节点,并查看节点内存,存储容量,负载,tpstats信息和其他指标的统计信息。我们还可以启动和停止节点并执行维护操作,例如清理,压缩,清洗,修复,停用和排放。
在幕后,OpsCenter使用Cassandra为其管理的集群存储元数据和指标。虽然可以将OpsCenter配置为将其表放在现有集群中,但建议的配置是为OpsCenter创建单独的集群以存储其数据。遵循此准则,您将避免影响生产群集。
Netflix Priam
Priam是Netflix为帮助管理其Cassandra集群而构建的工具。 Priam是希腊神话中的特洛伊之王,也是卡桑德拉的父亲。 Priam自动部署,启动和停止节点,以及备份和恢复操作。
虽然不需要AWS部署,但Priam也与Amazon Web Services(AWS)云环境很好地集成。例如,Priam支持在自动扩展组(ASG)中部署Cassandra,将快照自动备份到简单存储服务(S3),以及为跨越多个区域的Cassandra集群配置网络和安全组。
虽然Priam不包含用户界面,但它确实提供了RESTful API,您可以使用它来构建自己的前端或直接通过curl访问。 API提供了启动和停止节点,访问nodetool命令(使用JSON格式的输出)以及执行备份和还原操作的功能。
摘要
在本章中,我们介绍了一些与Cassandra交互以执行日常维护任务的方法;添加,删除和替换节点;使用快照备份和恢复数据等。我们还研究了一些有助于自动完成这些任务的工具,以加快维护并减少错误。

















 3908
3908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









