








Scala基于jvm,Scala可以调用java的任何功能
即可调用Hadoop任何功能,java支持面向对象(并不是纯对象,一切对象皆有方法,基本类型无方法)Scala是纯面向对象(一切皆对象,java升级版),面向对象和函数式编程结合,Scala的代码量是java的1/5
大数据开发语言,Scala简洁优雅,
Kafka消息中间件,适配器,数据到spark,spark数据到 ->hbase,sql需要Kafka,
1.安装vmvare
2.安装scala 2.10.4
3.java 1.8
不可变变量之前加 val :val result =2+10
不可变变量的值是不可变的,分布式交付,传输、校验数据,val(推荐使用)虚拟机,网络之间的交付,使用var,数据可能会变化,模块间通信,(Java 定义成final类型)
可变变量:var
val name :Int=0指定变量类型,赋值时,只能赋值该类型或该类型的子类型(面向接口)
val age1,age2,age3=0 同时申明多个变量
scala可以完成基础类型和引用类型的自动转化
0.to(5)->Range(0,1,2,3,4,5)集合,
Scala没有++,–操作
导入库(scala库,并可使用java所有库)
import scala.math._
min(20,4)
apply object构造scala具体对象的实例工厂方法
val array=Array.apply(1,2,3,4)
val age=19
if(age>=18)”adult” else “child”
最后一行的值就是代码块的值
val result=if(age>=18)
{
|“adult”
|buffered=10
|buffered
}
输出result:AnyVal=10
打印输出
println(”spark”)
print(“\nspark”)
printf(“%s is the future of big data computation framework.\n”,”spark”)
读取readLine
readLine
readLine(“please enter your password:”)
readInt
函数体

0 to element
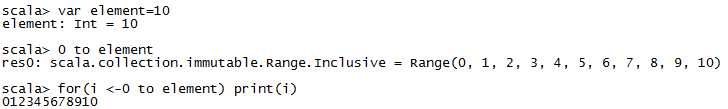
加判断语句

调break包
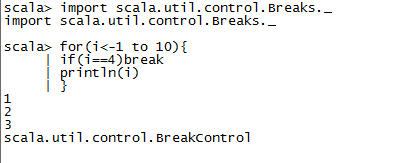
Any有return i 整数,print string

默认值先加载

参数顺序可以改变
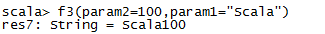
传任意参数
Range和整数不一样的,所以报错
递归循环取出来 : _*
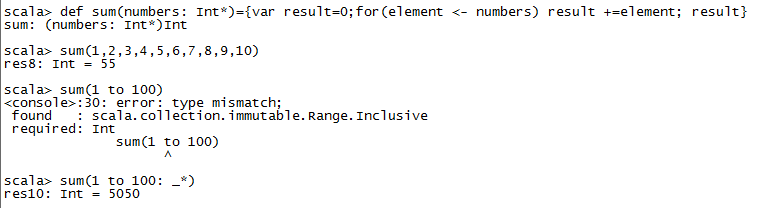
过程(没有返回值)Unit:

文件不存在,lazy不报错
去掉会报错

Array不可变

ArrayBuffer可变

遍历数组
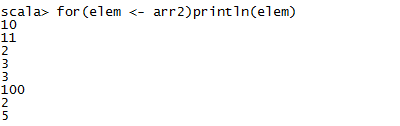
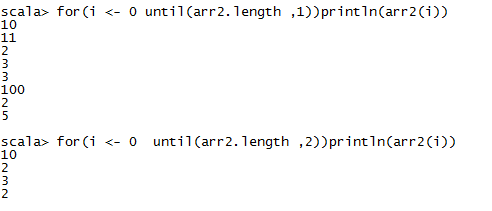
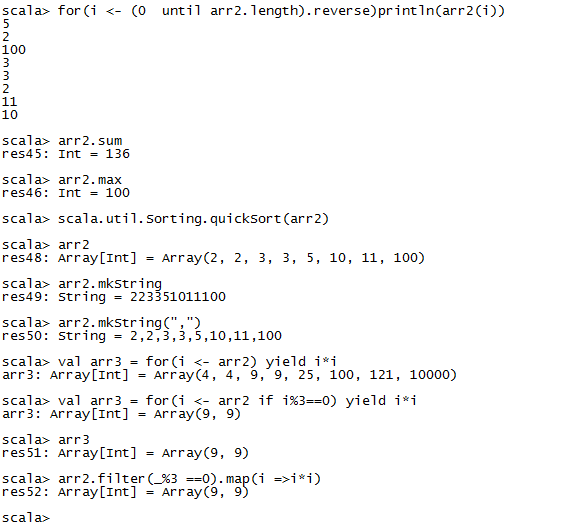
数组操作
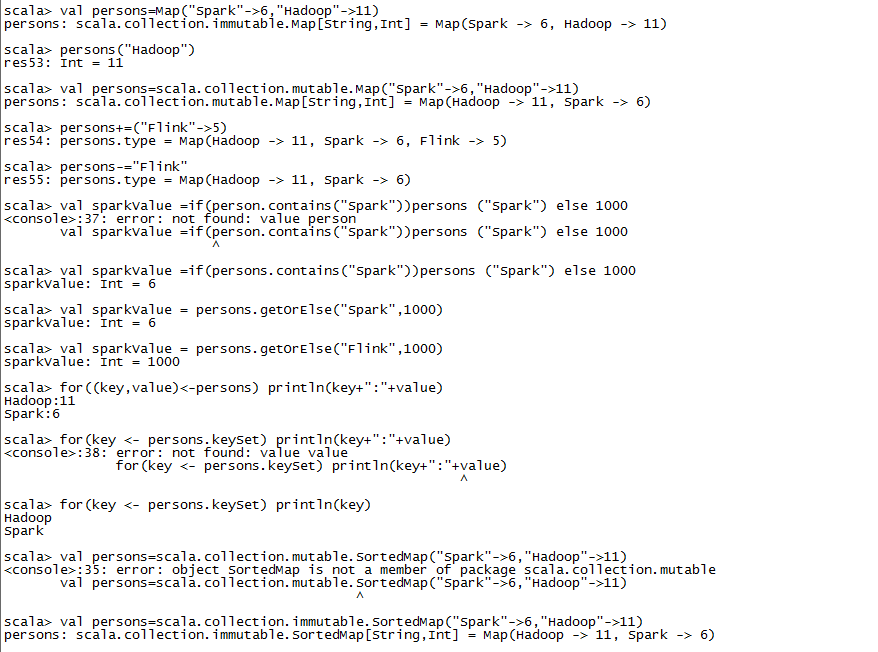
Map操作
遍历集合
SortMap以key排序
tuple,从1开始,接受函数多个参数

作业一:移除一个数组第一个负数后的所有负数
val array=ArrayBuffer[Int]()
array+=(8,3,4,57,-3,-3,-9,9)
var firstNegative=false
val indexes = for(index <- 0 until array.length if !firstNegative || array(index) >= 0)yield
{
if(array(index)<0)firstNegative=true
index
}
for(index<- 0 until indexes.length){array(index)=array(indexes(index))}
array.trimEnd(array.length-indexes.length)














 977
977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









