







目录
一、一列变多列 、分割 一行中的list分割转为多列 explode
一、一列变多列 、分割 一行中的list分割转为多列 explode
官方例子:Python pyspark.sql.functions.explode() Examples
https://www.programcreek.com/python/example/98237/pyspark.sql.functions.explode
根据某个字段内容进行分割,然后生成多行,这时可以使用explode方法
Eg:
df.explode("c3","c3_"){time: String => time.split(" ")}.show(False)
Eg:
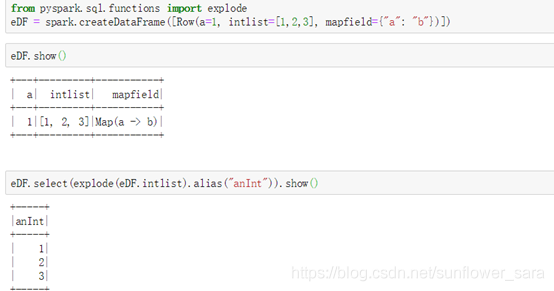
from pyspark.sql import Row
eDF = sqlContext.createDataFrame([Row(a=1, intlist=[1,2,3], mapfield={"a": "b"})])
eDF.select(explode(eDF.intlist).alias("anInt")).collect()
Out: [Row(anInt=1), Row(anInt=2), Row(anInt=3)]
Eg:
from pyspark.sql import Row
from pyspark.sql.functions import explode
eDF = spark.createDataFrame([Row(a=1, intlist=[1,2,3], mapfield={"a": "b"})])
eDF.show()
eDF.select(explode(eDF.intlist).alias("anInt")).show()
Eg:
df2=df1.select(explode(df1.line).alias("line_new_name"))
eg:
### 将结果分割,并分裂为不同列
### 将结果分割,并分裂为不同列
df = df.withColumn('res', getLabel(df['data'])).withColumn("res2", explode(col('res'))) #getLabel为udf函数
df_split = df.withColumn("s", split(df['res2'], ","))
df_split = df_split.withColumn('id', df_split["s"].getItem(0))
df_split = df_split.withColumn('label', df_split["s"].getItem(1))
二、多列变一列
A . 拼接:
concat_ws(',',collect_list(concat(concat(concat(concat(rank,'@@'),lon),'@@'),lat))) as info
B .collect_list、collect_set
返回list,
collect_set去除重复元素;collect_list不去除重复元素
官方例子:
https://www.programcreek.com/python/example/98235/pyspark.sql.functions.collect_list
pyspark.sql.functions.collect_list(col) 不去重
Aggregate function: returns a list of objects with duplicates.
New in version 1.6.
pyspark.sql.functions.collect_set(col)去重
Aggregate function: returns a set of objects with duplicate elements eliminated
多列变一列并保持原顺序
collect_list不能保持原始的顺序,需要添加rank辅助列
拼接之后在使用的时候再split,不然直接split的话顺序就又乱了
eg:
# 按rank排序后拼接
df_out =spark.sql('''
select cityid,
regexp_replace(
concat_ws(',',
sort_array(
collect_list(
concat_ws( ':',
lpad(cast(rank as string),2,'0'),
concat_ws("@@",concat_ws("@@", concat_ws("@@", concat_ws("@@", concat_ws("@@",poiid,poiname) ,lon),lat) ,hour),rank)
)
)
)
)
, '\\[0-9]+\:',
'')
as line_string
from db.tablename where rank<100 group by id ''').distinct()
三、多行变一行
具体参考我另一篇博文
https://blog.csdn.net/sunflower_sara/article/details/104044463
用collect_set 或者 collect_list + groupBy 二者相结合
collect_set去除重复元素;collect_list不去除重复元素
eg1:
spark.sql('''
select businessid, businesstype, collect_set(districtid) as list_districtid_tracepath from table
group By businessid, businesstype
''')
eg2:
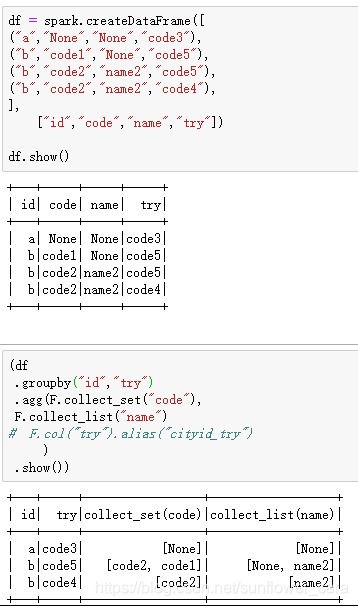
附录:DataFrame添加新的一列
DataFrame添加新的一列
https://blog.csdn.net/sunflower_sara/article/details/104044176














 2078
2078











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









