







2017.8.30更新:
全部工程代码上传百度盘。脚本现已停止开发。
工程代码:
链接:http://pan.baidu.com/s/1c1FWz76 密码:mu8k
————————————————————————————
开始正文前,我先阐述下我的选择的解决方案:Scrapy+beautifulsoup+Re+pymysql,爬取weibo手机版(反爬技术较少,比较容易)
Scrapy:爬虫框架,不多说
beautifulsoup:优秀的解析库,我用来解析lxml
Re:正则表达式
pymysql:MySql
思路简介
跳过繁琐的Scrapy 各个功能模块的介绍,我说下我的大致思路:
- 每个用户都会有自己的UID,通过对网页进行分析,我们可以获取到用户的UID,从而决定下一步的爬取方向。
- 微博每个用户的主页、粉丝与关注网页地址很有规律,得知了UID便可以很方便的完成对粉丝与关注列表等的爬取。
- 先通过正常登陆,得到COOKIES,让Scrapy使用该Cookies伪装用户。
对于分析获取的网页信息,我使用beautifulsoup与Re混合的方式(没系统学过网页,使用单一的beautifulsoup有点困难)。
Cookies的获取与分析
首先我们先正常登陆,来获取Cookies。
手机端的登陆我不知道为什么我无法点击登陆,所以我选择先正常登陆,然后再跳到手机版。
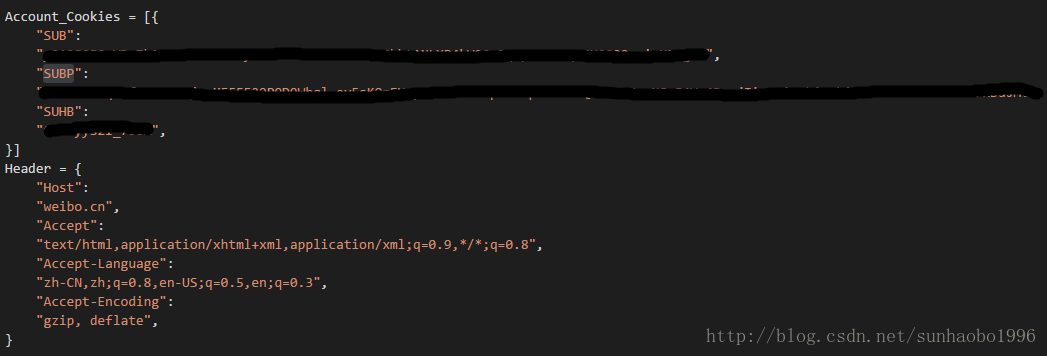
在手机版的抓包获取的Cookies如下:

根据名称,SUB即为代表身份的密钥。在实验中的结果也证明了服务器只对SUB,SUBP,SUHB这三个值敏感,其他的值服务器并不在意,但为了保险留下也是OK的。
之后我们需要替换Scrapy的User-Agent并禁止其遵守Robots.txt。
首先构造Header与Cookies(这个自己抓包就能获得):
同时,在settings.py中添加以下的User-Agent:
USER_AGENT = [
'Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14',
'Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2',
'Mozilla/5.0 (Win 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5642
5642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









