









linux下基本上所有的stl容器的实现都不是sgi stl的那种使用容器内置freelist内存池的方式了,其默认的allocate只是简单的调用malloc和free,而在malloc内部实现了内存池。这里的好处在于,如果用内置freelist的做法,就想到于一定义个vector就维护一个freelist内存池,消耗太大,而如果用malloc内存池的做法,就相当于在进程内部共享了一个内存池,增加了分配和释放的效率。
上面一段对于sgi stl的描述是错误的,sgi stl就是实现了该进程中所有内存块的管理,不管在进程中定义多少个vector或者map之类的,所使用的内存块均是由sgi 的allocate统一用二级内存池管理。
如此,在运行程序的时候会发现这个情况,malloc一些内存,free之后,进程仍然占用这些内存。
在malloc内部,是将一个大内存块,将各个小内存块(还没有分配的)组织到不同的双向链表中,注意,并不是在物理上将大内存块进行分割,而是在逻辑上分割。
一个小块内存我们称之为chunk , 对于这个chunk用下面的数据结构进行控制管理
struct chunk {
size_t prev_size;
size_t size;
struct chunk* prev;
struct chunk* next;
};
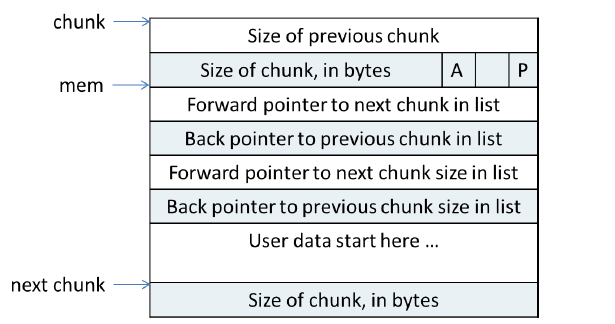
这样设计的目的就是用以内存复用。(为了便于理解,请无视图中第5,6个字节空间)
prev_size表示和这个内存块紧挨着的前一个内存块的大小,注意这里的紧挨着指的是在物理内存中是紧挨着,而不是指在接下来要讲到的链表中相邻。
size的后三个位中的P位表明前一个块是否正在使用。
prev指针,和next指针,如果这个块正在使用中,那么这两个变量占用的空间将被用户使用,也就是说这两个变量是无效的
如果块是free,pre指向在空闲链表中前一个块的地址,next指后一个块的地址。
如果设置一个块的指针是p, 这个块处于使用中,那么用户实际申请到的内存是 (用户实际需要的内存)+ (4 + 4) - 4 并且要基于8对齐
也就是说,用户能用的内存是上图中mem以下的空间,返回给用户使用的内存指针是 p + (4 + 4)
因为当前块已经使用了,所以下一个块的prev_size也就没有意义,所以也给当前块了。
空闲块是由多个双向链表组织的
第一种是bins,bins有128个链表,前64个双向链表是定长的,每隔8个字节大小的块分配在一个双向链表,后面的64个双向链表是不定长的,就是在一个范围长度的都分配在一个双向链表中。所以长度小于512字节(大约)的都分配在定长的双向链表中。后面的64个双向链表是变长的双向链表,每个双向链表中的chunk都是从小到大排列的。
第二种是unsort双向链表(只有一个双向链表),(是一个缓冲)所有free下来的如果要进入bins双向链表中都要经过unsort双向链表。
第三种双向链表是fastbins,大约有10个定长双向链表,(是一个高速缓冲)所有free下来的并且长度是小于80的chunk就会进入这种双向链表中。进入此双向链表的chunk在free的时候并不修改使用位,目的是为了避免被相邻的块合并掉。
malloc的步骤
先在fastbins中找,如果能找到,从双向链表中取下后(不需要再置使用为为1了)立刻返回。
判端需求的块是否在小箱子(bins的前64个bin)范围,如果在小箱子的范围,并且刚好有需求的块,则直接返回内存地址;如果范围在大箱子(bins的后64个bin)里,则触发consolidate。(因为在大箱子找一般都要切割,所以要优先合并,避免过多碎片)
然后在unsort中取出一个chunk,如果能找到刚好和想要的chunk相同大小的chunk,立刻返回,如果不是想要chunk大小的chunk,就把他插入到bins对应的双向链表中去。转3,直到清空,或者一次循环了10000次。
然后才在bins中找,找到一个最小的能符合需求的chunk从双向链表中取下,如果剩下的大小还能建一个chunk,就把chunk分成两个部分,把剩下的chunk插入到unsort双向链表中去,把chunk的内存地址返回。
在topchunk(是堆顶的一个chunk,不会放到任何一个双向链表里的)找,如果能切出符合要求的,把剩下的一部分当作topchunk,然后返回内存地址。
如果fastbins不为空,触发consolidate即把所有的fanbins清空(是把fanbins的使用位置0,把相邻的块合并起来,然后挂到unsort双向链表中去),然后继续第3步。
还找不到话就调用sysalloc,其实就是增长堆了。然后返回内存地址。
free的步骤
如果和topchunk相邻,直接和topchunk合并,不会放到其他的空闲双向链表中去。
如果释放的大小小于80字节,就把它挂到fastbins中去,使用位仍然为1,当然更不会去合并相邻块。
如果释放块大小介于80-128k,把chunk的使用为置成0,然后试图合并相邻块,挂到unsort双向链表中去,如果合并后的大小大于64k,也会触发consolidate,(可能是周围比较多小块了吧),然后才试图去收缩堆。(收缩堆的条件是当前free的块大小加上前后能合并chunk的大小大于64k,并且要堆顶的大小要达到阀值,才有可能收缩堆)
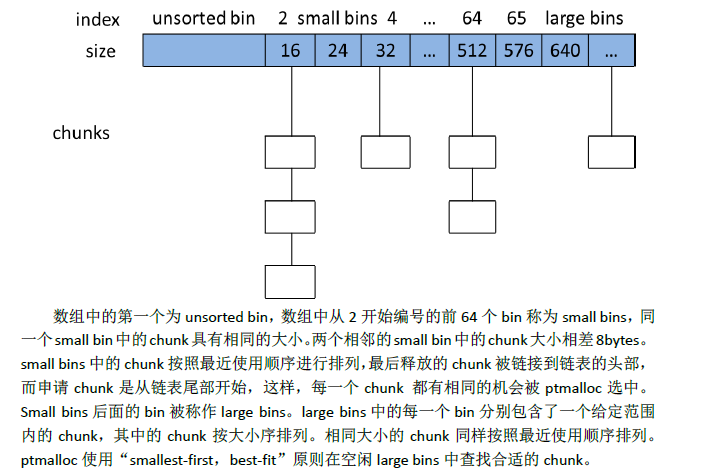
当一个chunk被free,并且要被链接到bin时,首先要先把该chunk是否处于使用中的标志P设为0,注意,这个标志实际上也处于下一个chunk中,同时如果它前后的chunk也是空闲的,就要进行合并。注意不用检查其下下一个是否空闲的,因为如果是空闲的,就在上次中已经做个合并了。
至于怎么在初始化时将一个块用chunk表示,可以参考下面的代码:
chunk * c = brk(sizeof(chunk) + xxxx);
c->prev_size = xxx;
c->size = xxxx;
malloc需要处理的申请大小是任意的,为了保持有限的链表个数。就必须在链表上存放了大小不同的块。它会进行排序,排序是为了加速遍历查找合适大小的块。这就是为什么malloc性能不如我们应用内存池的原因,也是为啥应用内存池还有必要存在的原因。换句话说,采用malloc的管理结构设计,但保持链表上块大小相同,将会是一个非常高效的没有遍历的O(1)的内存池。
参考 :http://rdc.taobao.com/blog/cs/?p=1015
http://hi.baidu.com/flowskyac/item/cfab9ff7dcc9c80985d27872















 1443
1443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









