






 本文探讨了机器学习模型的安全性,介绍了如何通过加入特定噪声使模型输出错误,并讨论了白盒与黑盒攻击的不同策略。此外,还展示了真实世界中的人脸识别攻击案例,并提出了被动与主动防御的方法。
本文探讨了机器学习模型的安全性,介绍了如何通过加入特定噪声使模型输出错误,并讨论了白盒与黑盒攻击的不同策略。此外,还展示了真实世界中的人脸识别攻击案例,并提出了被动与主动防御的方法。
摘要
在现实生活中,一个好的程序往往还需要有较高的安全性能,machine learning的model也不例外,对mechine learning的model attack主要是给输入加一些人为处理过的杂讯,然后导致model输出错误或者做出一些攻击者想让其做的事情。本文阐述了attack能够实现的理论基础,介绍了一些常见的攻击方法如FGSM攻击的思想,阐述了White Box和Black Box 的attack的基本思想,说明了acctak从虚拟世界转化到现实世界可能性与常见的问题。还介绍的基本的防御手段:Passive Defense和Proactibe Defense,前者是被动防御,后者是主动防御。一、Attack
1.1 Motivation
machine learning用在日常生活中,光是好是不够的,还需要对抗带有恶意的攻击。目前攻击是比较容易的,防御比较困难。
1.2 Attack是怎样的
给模型输入中加入一些杂讯,这些杂讯是人为处理过的,最后使得模型输出结果错误。
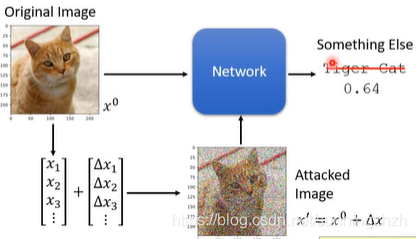
1.3 Loss Function for Attack
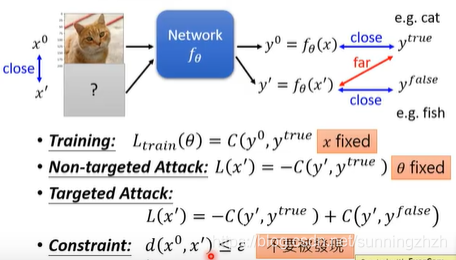
- Non-targeted Attack: 找一个输入,让得到的输入离正确输出越远越好。
- Targeted Attack: 找一个输入,希望输出离正确输出越远越好,离设计的错误输出的目标值越近越好。
- 总的约束(constraint): 我们希望输入和原本的输入越接近越好,这样就不容易被发现。
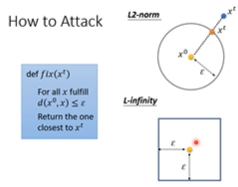
1.4 How to Attack
和train machine leaening model时差不多,这里也是用gradient的方法来求解,不过Attack时,是将输入x作为train的对象,同时在train时加上对x范围约束条件,保证x变化很小,小到人很难分辨出来。
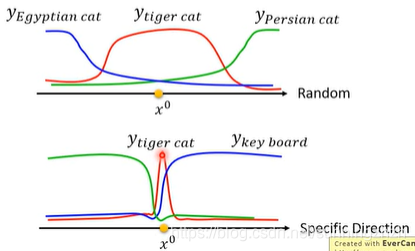
1.5 What happened?
输入是多维空间上的变量,在某些特别方向上,x只需要改变一点点,输出就会完全不一样。
1.6 Attack Approaches
attack的方法特别多,它们的不同之处往往是在于它们用不同的constraints和计算loss function的方法。

1.6.1 Fast Gradient Sign Method(FGSM)
更新x的方法是,x* = x0 - ε △x。
其中ε是约束的最大值。
△x是x的gradient的符号,gradient为正,△x=1,gradient为负,△x=-1。
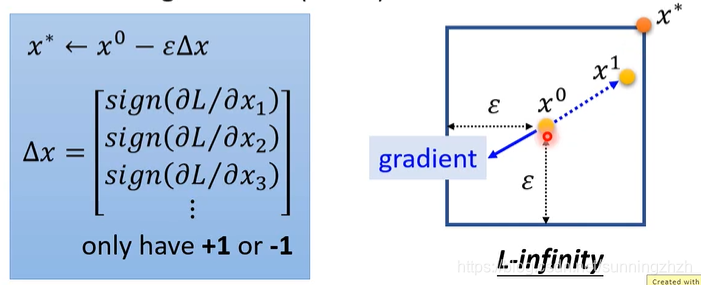
在FGSM中,我们只在乎gradient的方向,不在乎大小。它的原理就像设置了一个很大的leran rate,一次就会直接超出约束 ,然后令x*= ε 或者x*=- ε 。
1.7 White Box vs Black Box
1.7.1 White Box
White Box Attack是知道network参数,然后我们通过network参数来得到攻击的x*。
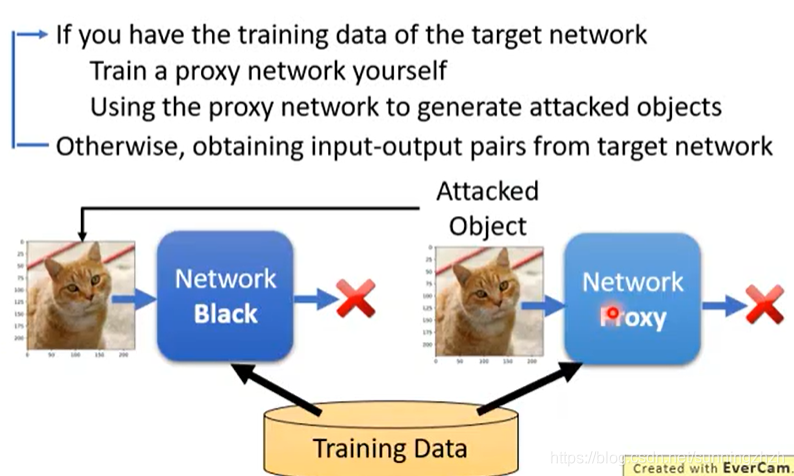
1.7.2 Black Box
Black Box Attack是不知道network参数,我们通过network的train data,去模拟一个同样功能的network*,然后攻击network得到x,用得到的x*再来攻击network,往往也是可以成功的。
1.7.3 Universal Adversarial Attack
不需要为每一张image都找不同的杂讯,我们可以为所有的image找同一个△x,即x* = x+△x,x*可以使所有的结果错误。

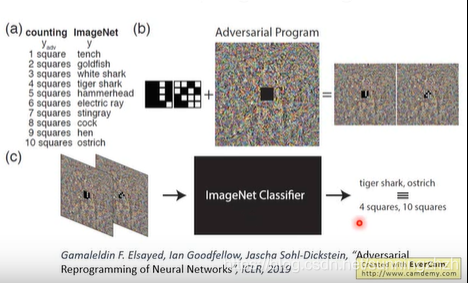
1.7.4 Adversarial Reprogramming
改变一个network原来想做的事情,让它去做攻击者想让它去做的事情。
二、真实世界的攻击
问题:真实的世界mechine是从镜头看世界,那些微小的杂讯透过镜头后mechine可能会看不见,这样的攻击也许没有效果。洗衣机的实验表明,微小的杂讯确实会对结果产生影响。
2.1 对人脸识别的攻击
加杂讯在人脸上不合理,所以将杂讯变成一个眼镜。

再将该眼镜做成真实世界的东西。

带上该眼镜的人,人脸识别系统就会出现辨识错误,将其辨识为其他人。

将眼睛做成真实世界的东西时,也是需要考虑很多东西的,因为真实世界是3D的,所以我们需要让其在不同的角度下,都可以攻击成功。
三、Defense
3.1 Passive Defense
不对修改model,只是在model上加一些保护措施,如在数据输入前,加上一个Filter,如对该图片进行Smoothing处理。

为什么会成功,可以试着这样理解,就是加上杂讯后的图片,它只有在极少数维度且很窄的区域上会被辨识成Keyboard的概率高,所以我们加上Smoothing处理后,很有可能会将杂讯的影响力大大降低,而对正确的结果不会有太大影响。根据这样子的思想,设计了一个方法叫做Feature Squeeze。
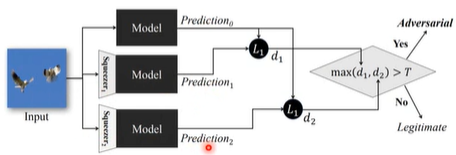
3.1.1 Feature Squeeze
原理:首先将输入不经过处理直接传入模型得到输出y,再将输入经过squeeze1处理后传入模型得到输出y1,再将输入经过squeeze2处理后传入模型得到输出y2,用分别与y1,y2进行比较,若差距很大,我们就知道输入可能是被attack了。
3.2 Proactive Defense
3.2.1 思想
在train时,将network的漏洞找出来,再补起来。
3.2.2 过程
- 用training data 去train一个model。
- 分别对每一张图片,加上一些杂讯,得到x*,作为输入,对model进行攻击,攻击成功的x*给其标上正确的label,作为training data,重新进行第一步的步骤进行训练,反复多次,得到一个具有自我防御能力的model。
缺陷:假如找漏洞用的是a方法,别人攻击时,用的是b方法,攻击还是很有可能会成功的。
展望
从目前看来,对mechine learning model的攻击是很容易的,相反防御则比较难,具体表现在,第一:防御的不够全面,加上防御措施后的model仍然有很多漏洞。第二:防御手段容易被攻击手段破解,甚至有些都不需要破解,可以直接绕开。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









