







Conditional Generation by GAN
文章目录
摘要
上一章讲的GAN的输入是随机的vector,它是没办法控制GAN生成我们想要的目标,本章讲的是改进的GAN——Conditional GAN,它可以控制GAN生成我们想要的目标输出,Conditional GAN主要分为两大类,一类是Supervised一类是Unsupervised,本章主要是阐述Supervised Conditional GAN和Unsupervised Conditional GAN的原理和在图像生成和图像转换上的各种做法。1、Supervised Conditional GAN
1.1 目的
之前的GAN,是随机输入一个vector然后产生输出,无法控制产生我们想要的输出。Conditional GAN就是控制我们想要输出的结果,例如输入文字 “火车”,然后machine就输出火车的图片。
1.2 做法
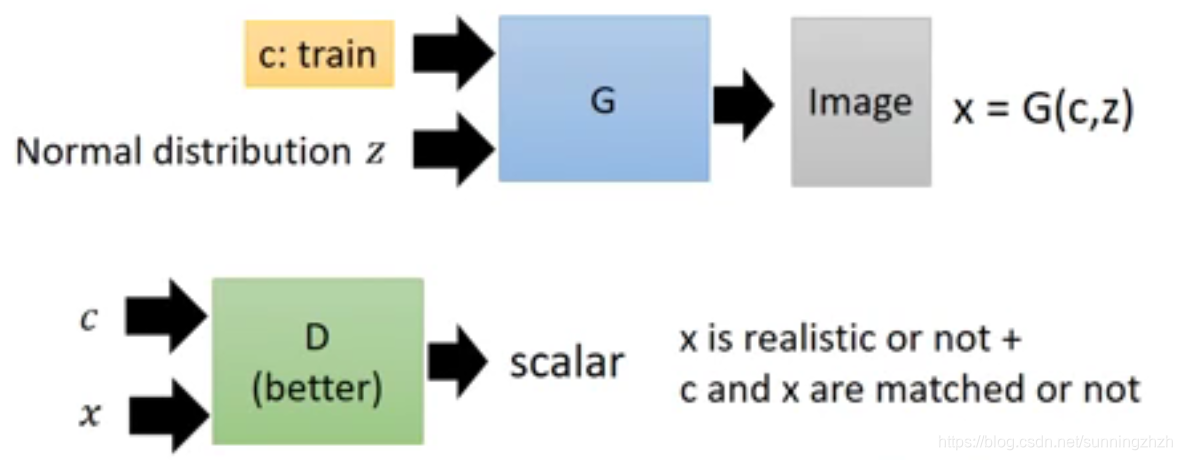
Conditional GAN是属于监督学习的,它的做法是向G输入train data和Normal distribution,然后生成image,将生成的图片放入D中,进行打分训练。但是这样是不够的,因为对G来说只需要产生清晰的图片就可以骗过D了,G可以完全无视train data,所以我们需要在D的打分上加一些约束。
如下图,我们在D中不仅要输入图片x,还需要输入conditional data(train data),D在打分时,不仅要考虑图片是否像人画的还需要考虑图片与条件是否匹配。
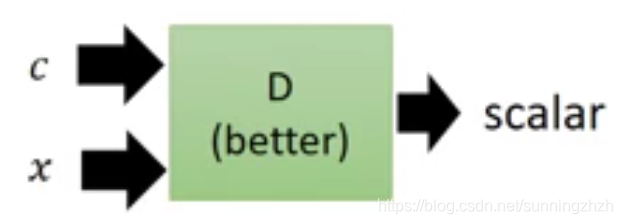
1.3 Discriminator(D)的架构
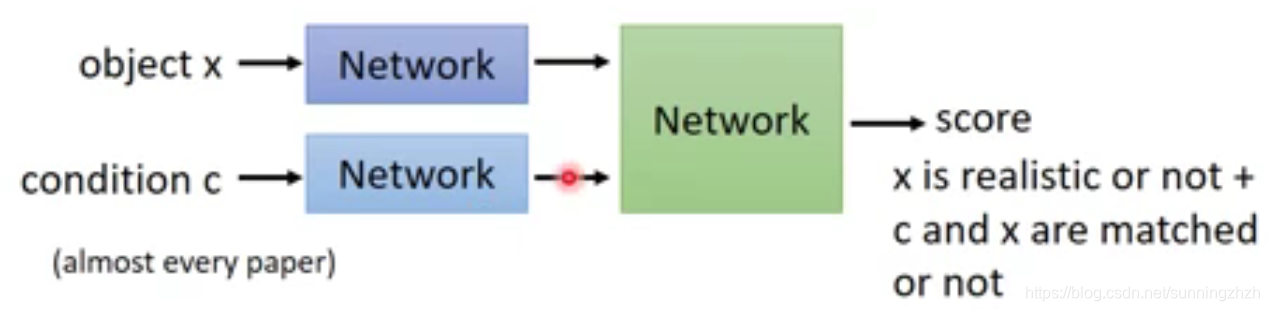
- 一个常见的架构是将object x(图片)和condition c(文字)分别通过Network变成vector,然后组合在一起后丢给一个Network进行打分。
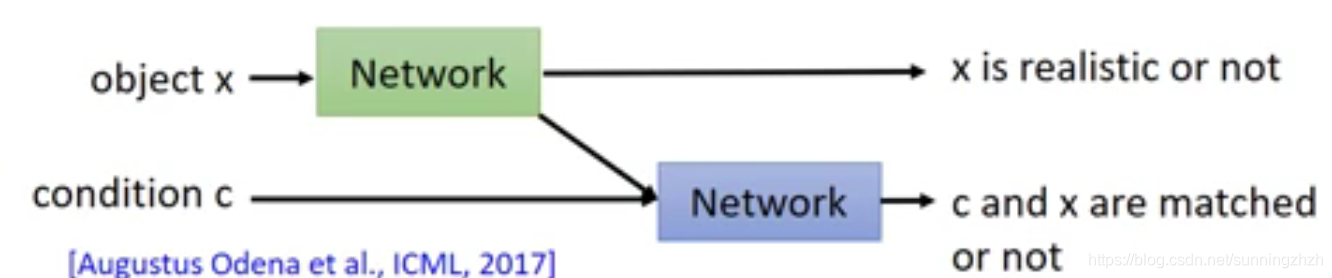
- 一个新的架构是将上述办法做的事情拆开,也就是将用两个不同的Network,一个辨别图片是否真实,一个辨别图片与条件是否匹配。如此得到的结果更加清晰明了,当machine给某个图片低分时,我们也可知道该图标为什么是低分的。
2、 Unsupervised Conditional GAN
2.1 常规做法
Conditional GAN是可以Unsupervised,以将现实图片转换为漫画图片为例,有以下三个常用方法可以实现:
- 将输入图片X丢给G,G负责将图片X转换成漫画图片Y,再将Y和真实的漫画图片丢给D,D负责判断Y和真实的漫画图片的相似度分数,该方法没有label,所有是无监督的。但这其实存在问题,就是G可以不考虑输入X,而直接生成一个与输入图片无关的漫画图片来骗过D。解决这问题的一个方法是在D打分时,还要考虑输入图片和Y,是否匹配。
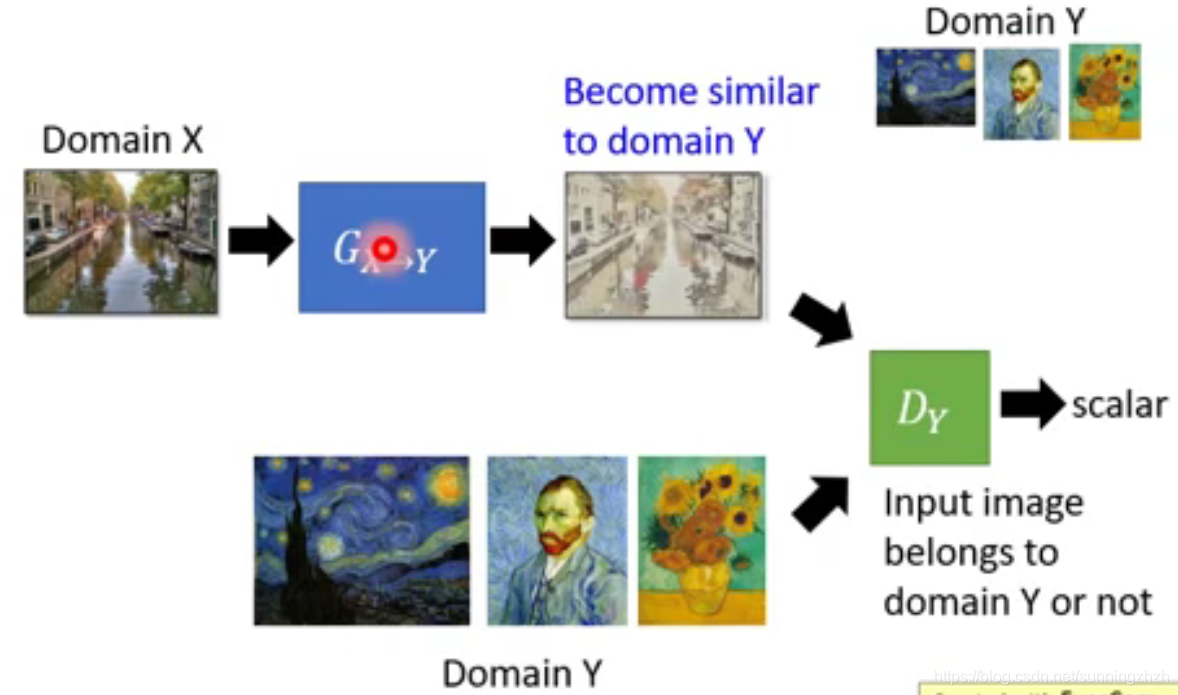
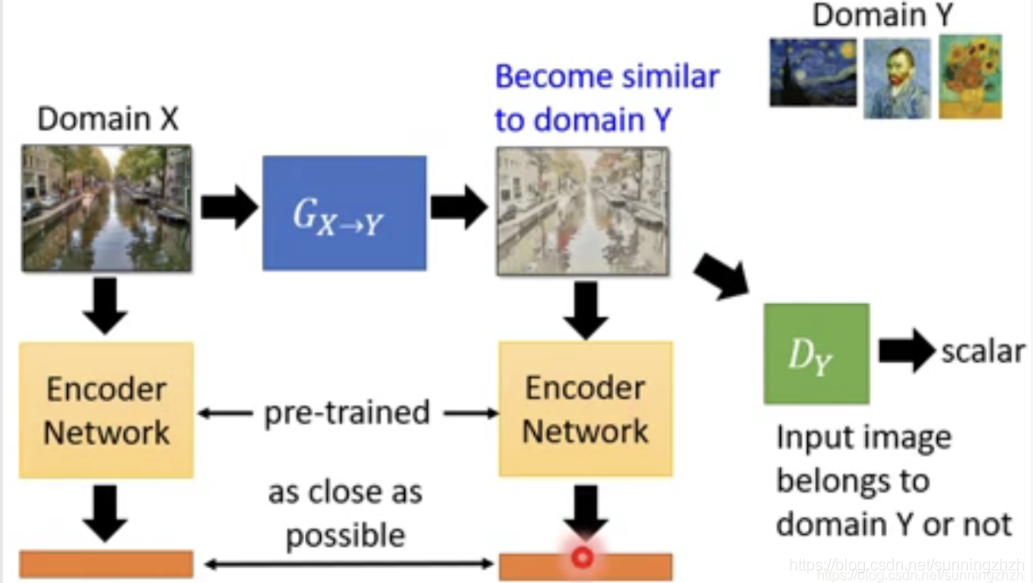
- 该方法是在1的基础上,将输入图片X和G生成的漫画图片分别丢给pre-trained的Encoder Network,然后得到两个code,再训练时,我们希望这两个code越接近越好,由此得到的X,和Y就是相似的。
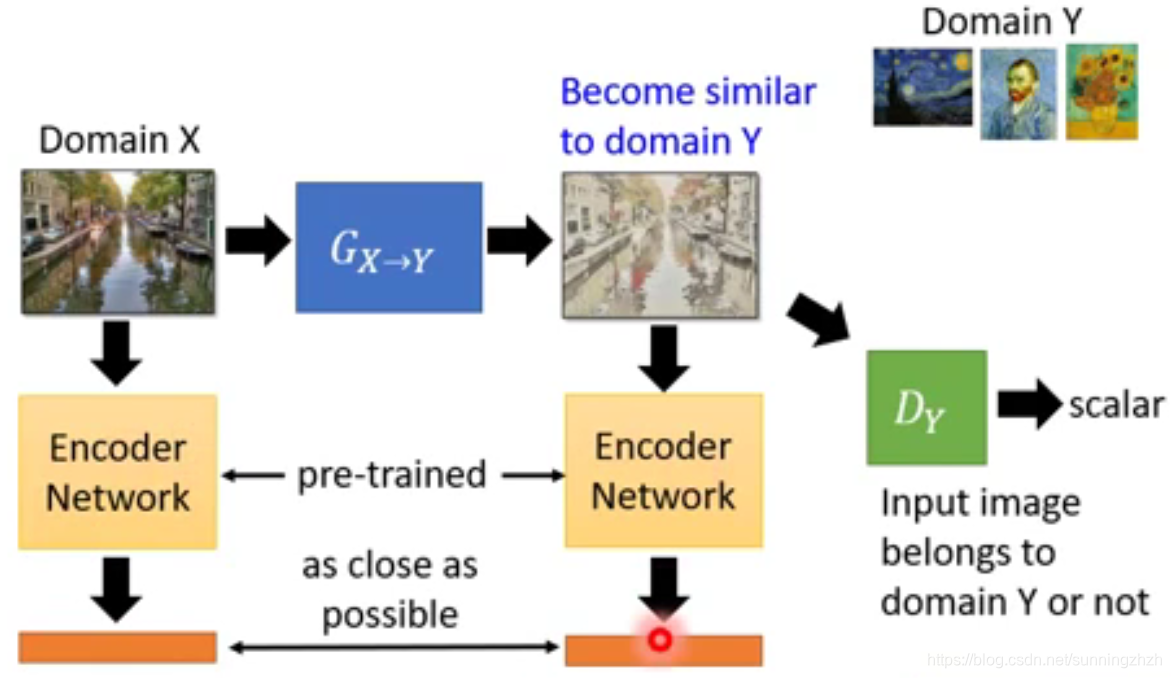
- 该方法是在1的基础上,再引入一个G,该G的做法是将生成的漫画图片Y再还原得到原本的输入图片,以此控制生成的漫画图片Y和输入图片X是接近的。
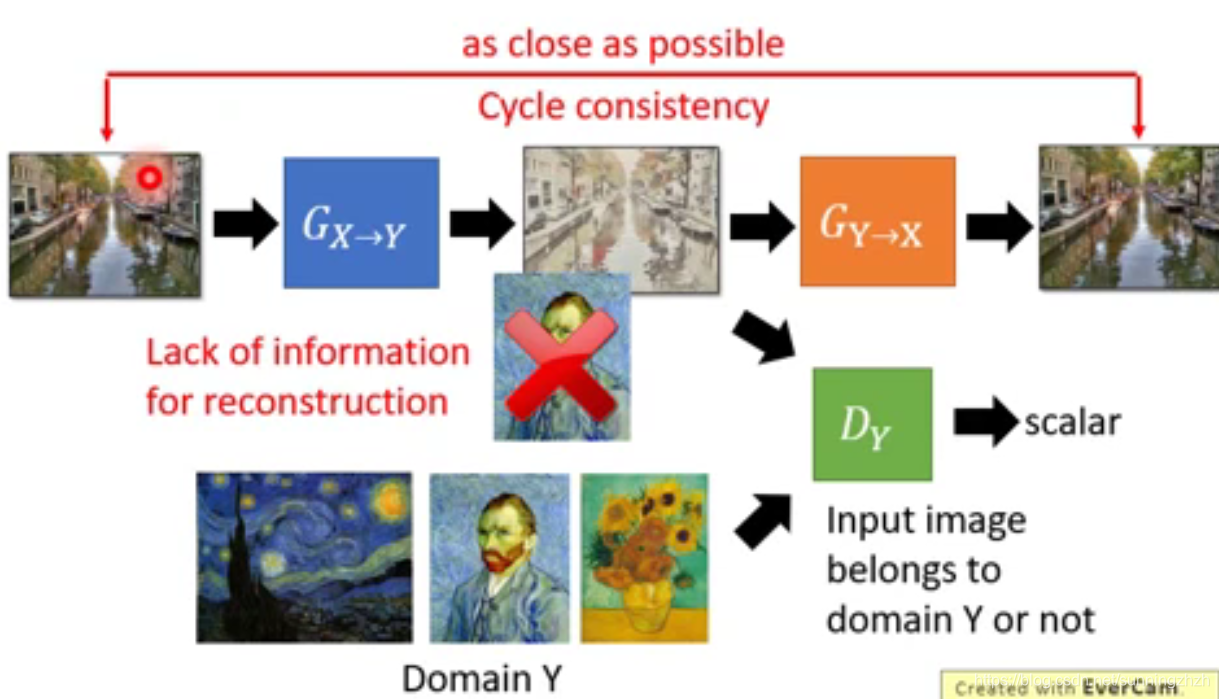
2.2 其他的做法
2.2.1 StarGAN
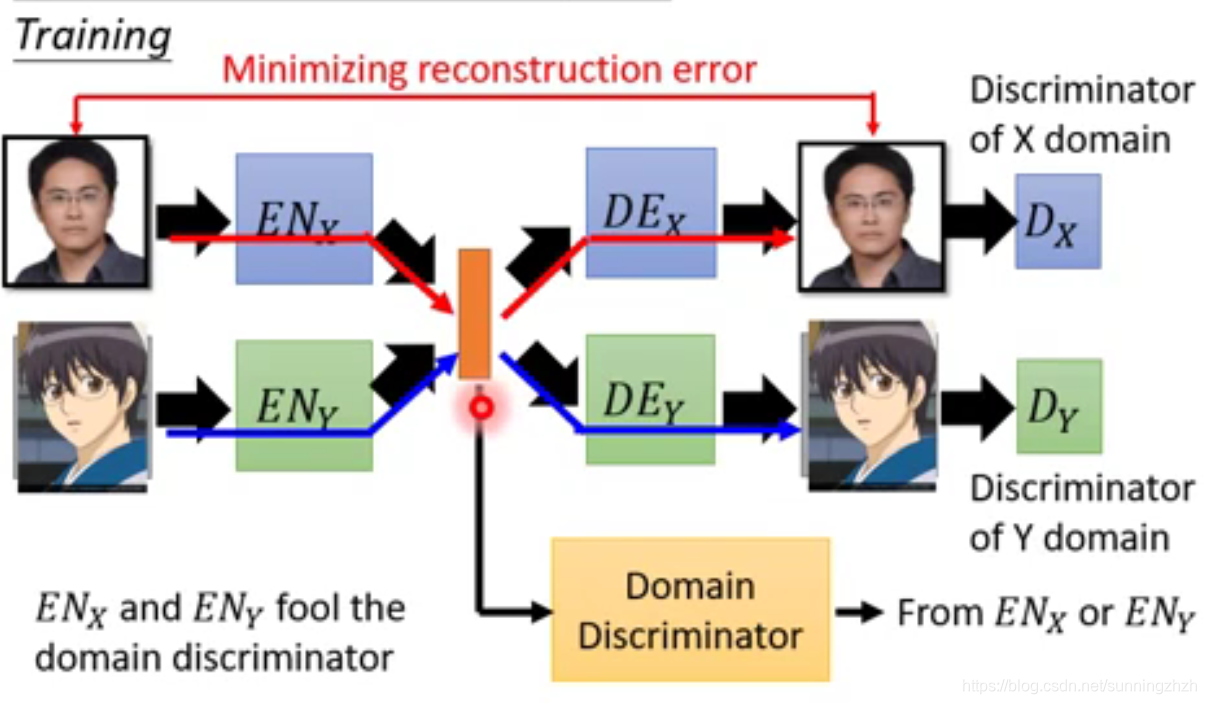
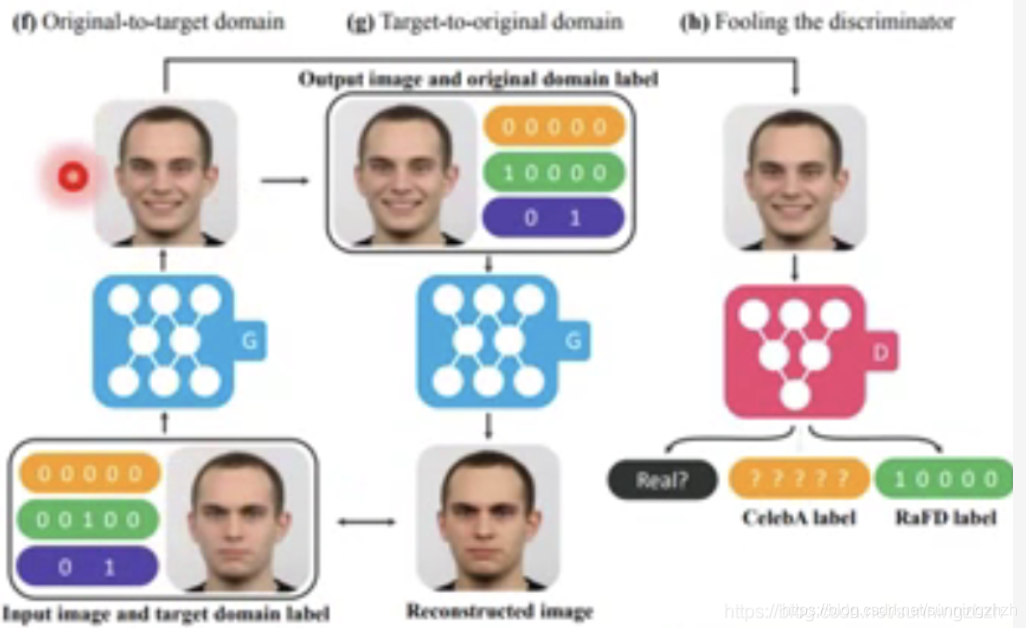
前面讲的转换是从一个domain转到另一个domain,而StarGAN则是在不同domain的特征互相转换。它的做法是将target domain和原始图片输入到G中,然后G生成图片,为了验证G生成图片的是否完整的保持了原始图片的信息,我们将该图片重新丢给G并输入图片原来的domain将其完好的转变回来,我们希望转变回来的图片和原始图片越接近越好,以此得到好的Fake image,然后将Fake image丢给D,让D根据图片的真实性及Domain是否正确给Fake image打分。
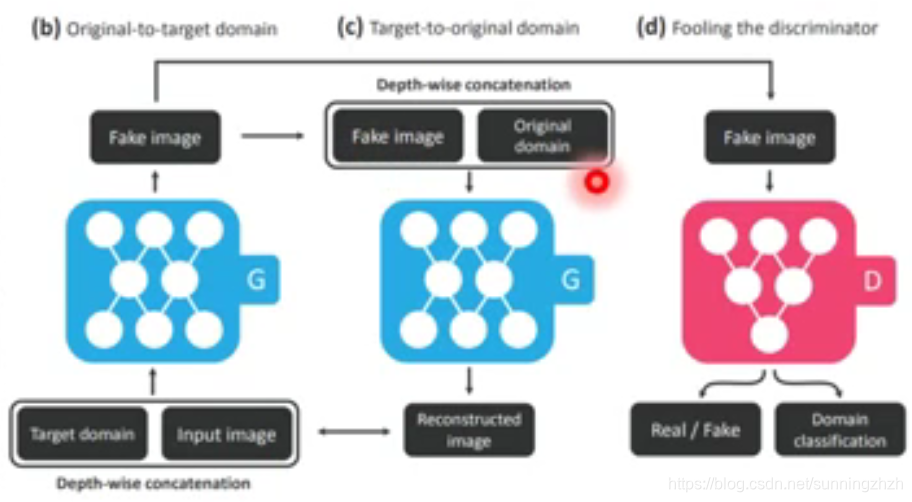
下面就是StarGAN的应用,它将一个人从生气的domain转换为微笑的domain。
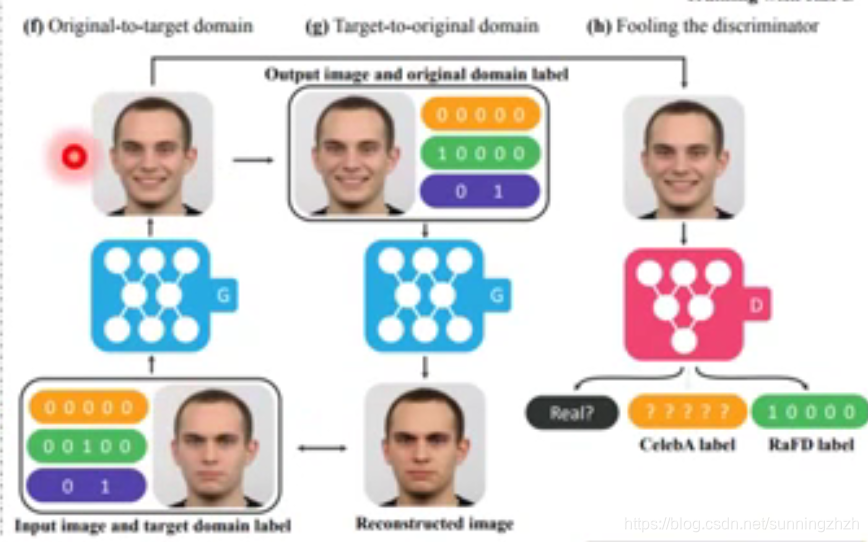
2.2.2 Projection to Common Space
它是希望真实图片输入,经过model输出动漫图片,动漫图片输入,输出真实图片。它的做法是分别train两个Auto-encoder,一个train真实图片,一个train动漫图片,为了确保生成的图片清晰,我们还分别引入D,确保产生图片的domain和清晰度。但是这样存在一个问题,由于两个Auto-encoder都是分开train的,所以我们没法保证真实图片和动漫图片的vector每个维度代表的意义是一样的。
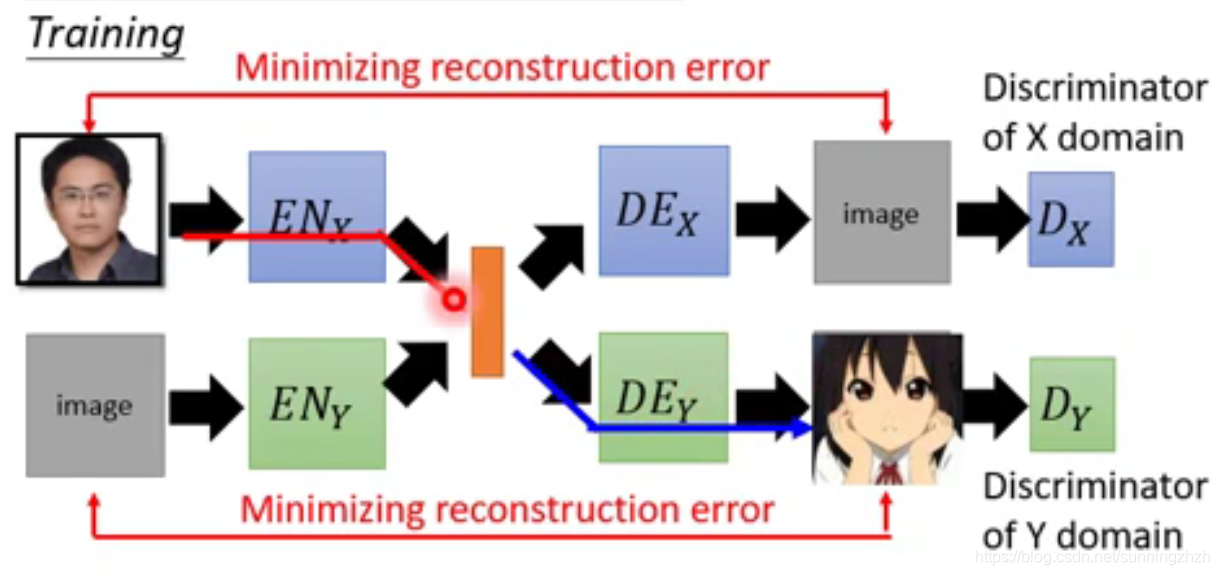
这个问题比较常见的解决办法是让它们train的network最后几层的参数共用,而强迫使得其每个维度的含义相同。
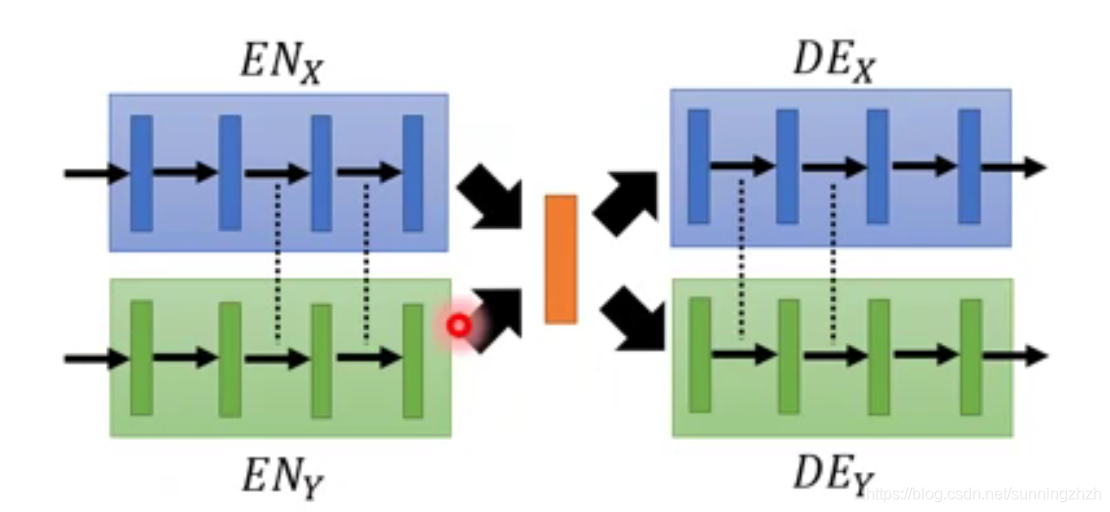
还有另一个解决办法,在本质上和上述方法一样,它是在model的中间引入一个Domain Discriminator,该D做的事情是通过它们两者产生的vector来识别该vector是属于domain X的还是domain Y的,我们希望machine可以骗过Domain D,而机器为了成功骗过Domain D,就会使真实图片和动漫图片每个维度代表的含义相同。
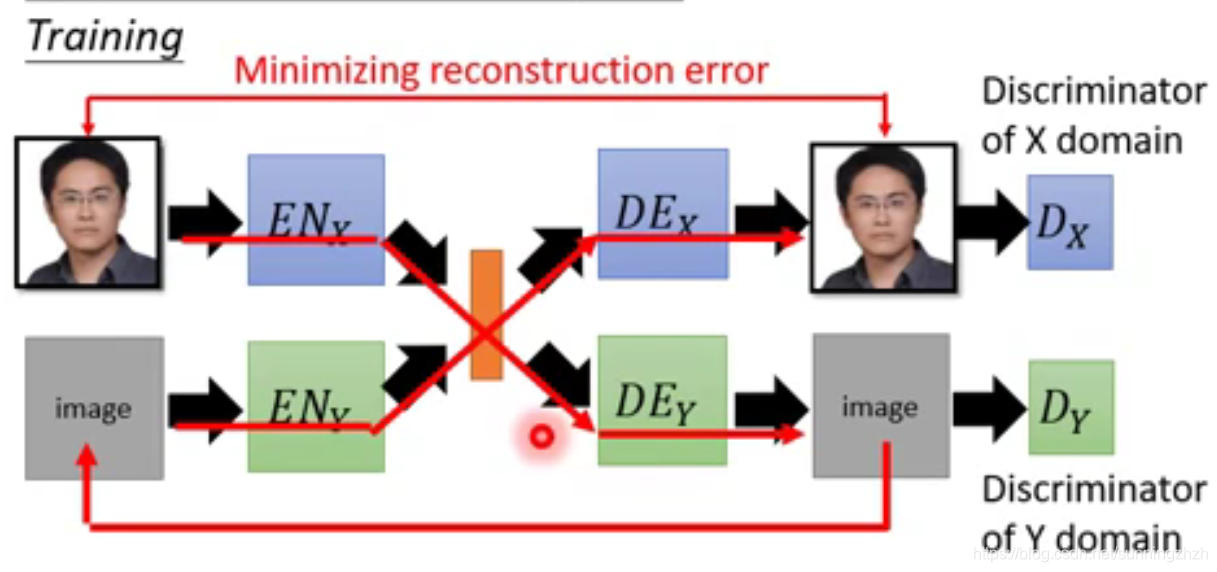
还可以用Cycle consistency,它是将真实的图片通过encoder得到的code生成动漫图片,在将其作为输入丢给动漫图片的encoder,生成code,用其生成真实图片,然后希望生成的真实图片和原图越接近越好。
方法
-
Supervised Conditional GAN用的方法是将train data和noise同时丢给G,G会生成图片,将G生成的图片及期望该图片对应的文字的encode组合起来丢给D,D在打分时,只有当G生成的图片像真的且文字和G对应的图片是匹配的时候才给高分。
-
Unsupervised Conditional GAN的方法有很多,它主要分为两类,一类是将输入从一个Domain转移到目标Domain,以真实照片二次元化为例,它的方法主要分为两步,一步是将Domain X和Domain Y通过Pre-trained将两者转换为vector,训练的时候让其越接近越好以保持生成的图片保留了Domain X的信息,一步是将Domain Y丢给D,D以Domain Y是否二次元给Domain Y评分以确保产生的图片是二次元的。
另一类是改变输入的某些特征。它的一个重要的方法叫StarGAN,以将人从愤 怒表情转换为微信为例,它的做法和上述方法类似,分为两步,一步将G生成的微信的图片再经过G还原成愤怒的图片,在训练时希望还原的图片与真实图片越接近越好,以此确保生成的图片保留了输入图片完整的信息,一步是将生成的图片丢给D,D根据图片的真实度及是否是目标Domain(这里是微笑表情)打分。
结论
Supervised Conditional GAN适合图文结合且training data比较充足的情况下使用,约束条件较大。Unsupervised Conditional GAN则适用性较广,且这些方法的本质都可分为两步,一步确保生成的图片较完整的保留了输入图片的信息,一步是确保生成的图片是向着目标方向去生成的。
展望
本章都是以图片生成为例,但是Conditional GAN运用不止于此,近年来GAN的应用越来越多了,理论上生成问题及任何将输入特征提取转移到目标输出上的问题都可用Conditional GAN解决,例如Conditional GAN还可以解决变声器、图像修复等的问题。















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









