







需求:古诗文网站的验证码识别(https://so.gushiwen.cn//user/login.aspx)
一、注册和登录云码账号
登录后显示页面:
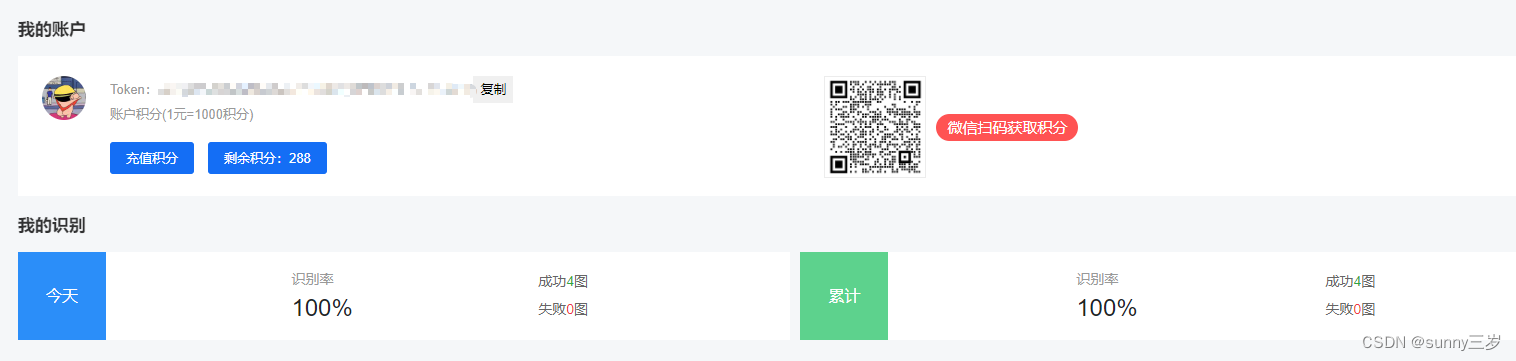
注意:新注册的用户积分是0,在解析时会出现以下错误,因此我们需要获得积分才能使用,这里充值的最低金额是10元,所以小编是扫描微信获取300积分,每次解析会扣3个积分,测试的话是够用的。

二、集成云码
在云码的开发文档,选择python语言,根据网页的验证码格式分析,集成此方法完成验证码的识别。
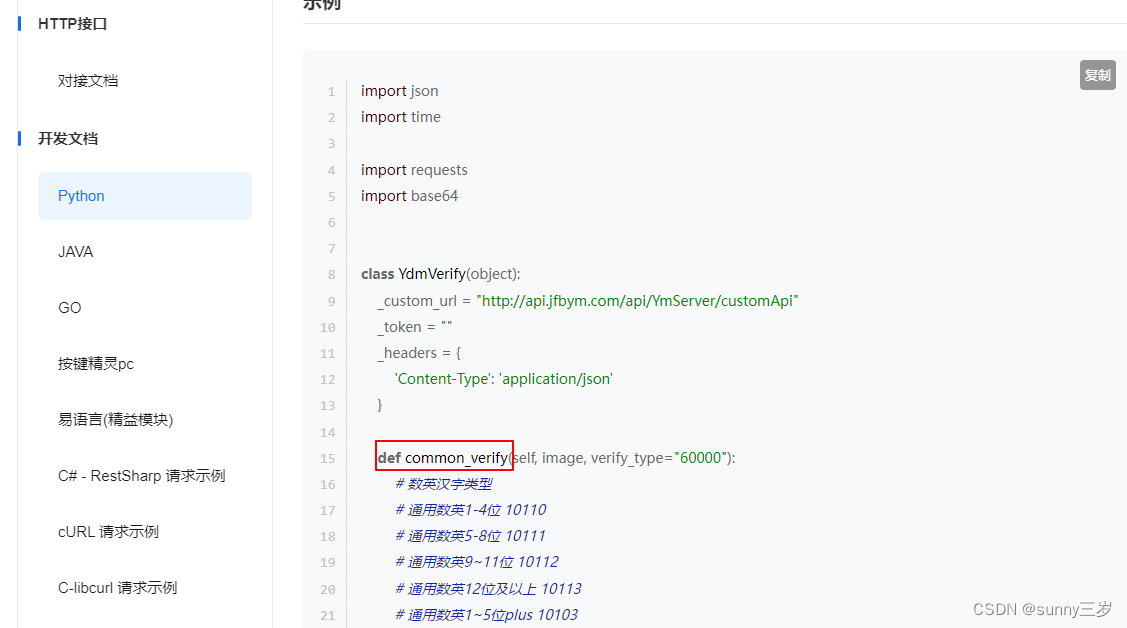
class YdmVerify(object):
def __init__(self, token):
self._token = token
self._api_url = "http://api.jfbym.com/api/YmServer/customApi"
def verify(self, verify_type, image_data):
image_base64 = base64.b64encode(image_data).decode('utf-8')
payload = {
'image': image_base64,
'token': self._token,
'type': verify_type
}
headers = {
'Content-Type': 'application/json'
}
response = requests.post(self._api_url, headers=headers, data=json.dumps(payload))
response_data = json.loads(response.text)
#10000代表识别成功,返回数据
if response_data['code'] == 10000:
return response_data['data']
else :
raise Exception('Failed to verify captcha: %s' % response_data['msg'])三、分析古诗文页面
1.获取网页的源代码
想要拿到验证码的数据,我们需要先获取到整个页面的源代码,再进行分析。这里的User-Agent可以在网页打开开发者工具获取。
#页面地址
url = 'https://so.gushiwen.cn/user/login.aspx'
#UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
#解析页面的源代码
page_text = requests.get(url=url, headers=headers).text2.解析出验证码图片的地址
在这里,我们依然利用开发者工具,观察二维码图片的位置,根据页面显示的位置去获取图片的地址。
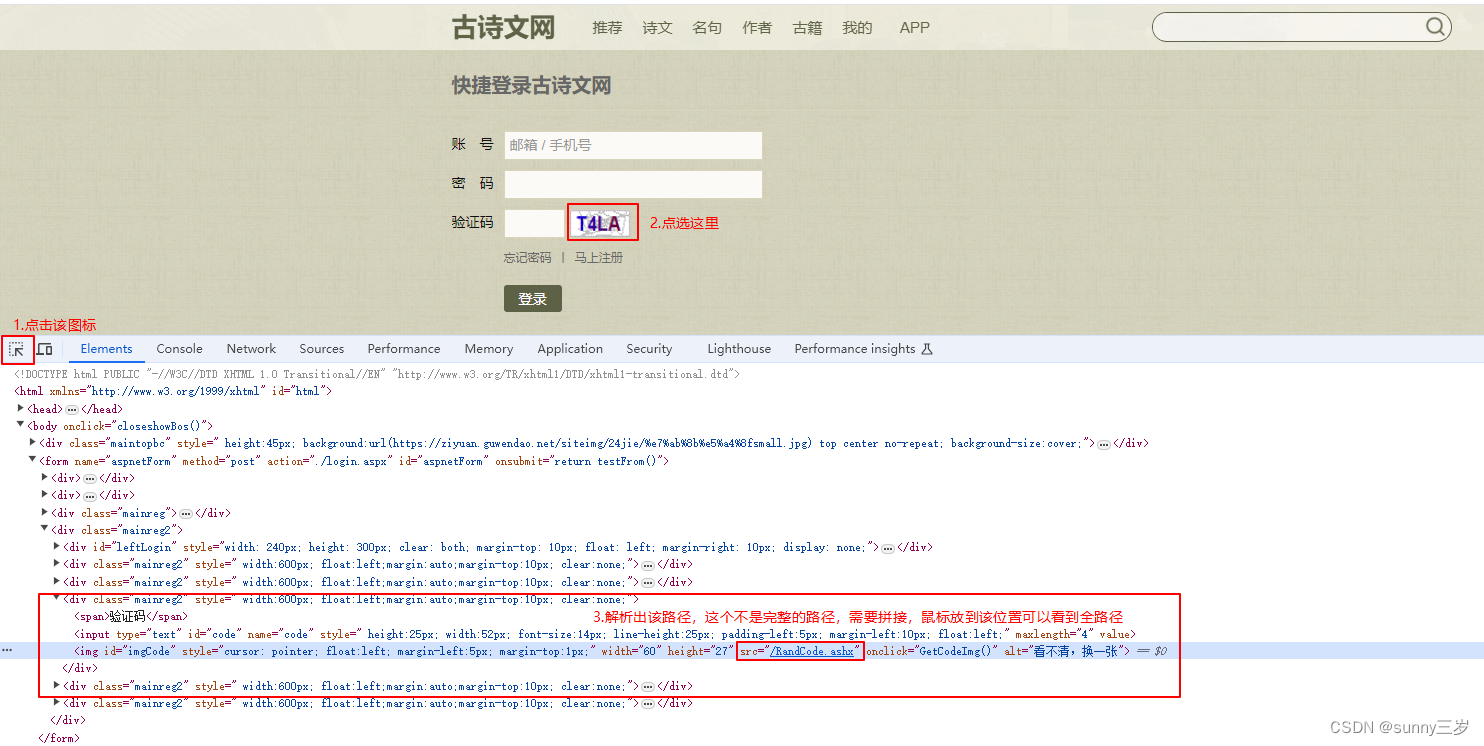
tree = etree.HTML(page_text)
qr_code_src = 'https://so.gushiwen.cn/' + tree.xpath('//img[@id="imgCode"]/@src')[0]
qr_code_data = requests.get(url=qr_code_src, headers=headers).content
#将图片保存到本地
with open('./qr_code.jpg', 'wb') as fp:
fp.write(qr_code_data)3.调用识别功能
#识别验证码参数
token = 'DcayTHwestAFPV68ebz7fT9Kf_adZKEZJ_Q-_2veV78'
image_path = qr_code_src
verify_type = '10111' # 通用数英5-8位
#调用二维码识别的方法
yunma = YdmVerify(token)
result = yunma.verify(verify_type, qr_code_data)
qr_code = result['data']四、完整的代码
#需求:古诗文网站的验证码识别(https://so.gushiwen.cn//user/login.aspx)
import json
import requests
import base64
from lxml import etree
class YdmVerify(object):
def __init__(self, token):
self._token = token
self._api_url = "http://api.jfbym.com/api/YmServer/customApi"
def verify(self, verify_type, image_data):
image_base64 = base64.b64encode(image_data).decode('utf-8')
payload = {
'image': image_base64,
'token': self._token,
'type': verify_type
}
headers = {
'Content-Type': 'application/json'
}
response = requests.post(self._api_url, headers=headers, data=json.dumps(payload))
response_data = json.loads(response.text)
#10000代表识别成功,返回数据
if response_data['code'] == 10000:
return response_data['data']
else :
raise Exception('Failed to verify captcha: %s' % response_data['msg'])
if __name__ == '__main__':
#页面地址
url = 'https://so.gushiwen.cn/user/login.aspx'
#UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
#解析页面的源代码
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
qr_code_src = 'https://so.gushiwen.cn/' + tree.xpath('//img[@id="imgCode"]/@src')[0]
qr_code_data = requests.get(url=qr_code_src, headers=headers).content
#将图片保存到本地
with open('./qr_code.jpg', 'wb') as fp:
fp.write(qr_code_data)
#识别验证码参数
token = 'DcayTHwestAFPV68ebz7fT9Kf_adZKEZJ_Q-_2veV78'
image_path = qr_code_src
verify_type = '10111' # 通用数英5-8位
#调用二维码识别的方法
yunma = YdmVerify(token)
result = yunma.verify(verify_type, qr_code_data)
qr_code = result['data']
print(qr_code)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









