







背景
日常工作中若遇到一个功能非常复杂时往往实现起来已经相当困难,然而更大的挑战是日后的维护与扩展。举例,电商的下单功能一般流程:
- 获取商品信息
- 获取会员信息
- 计价
- 扣除库存
- 增加会员积分
……
倘若后期需要增加营销活动的需求,到底应该在哪增强呢?这就催生出任务编排/协同的需求了
名词解释
| 名词 | 解释 |
| orchestration(编排式) | 任务的决策和执行顺序逻辑集中在一个编排器类中 |
| choreography(协同式) | 任务的决策和执行顺序逻辑分布在步骤中 |
| task(任务) | 一次完整的执行流程,由step组成 |
| step(步骤) | 任务执行的步骤,任务的最小单元 |
| 核心/非核心 | 任务中是否必须执行的步骤,必须执行为核心步骤 |
业界方案
一般电商的业务需求都比较复杂,因此京东的方案就比较完善且有效
京东零售:asyncTool: 解决任意的多线程并行、串行、阻塞、依赖、回调的并行框架,可以任意组合各线程的执行顺序,带全链路执行结果回调。多线程编排一站式解决方案。来自于京东主App后台。
京东ISV:gobrs-async: 🚀🔥🚀 多线程并发编程框架。为企业高并发(电商)复杂场景提供快速解决方案。 可以完美应对多种多线程高并发场景。如果苦恼于多线程开发,赶快体验下吧!
关键词:编排式、整体控制
京东物流:基于AbstractProcessor扩展MapStruct自动生成实体映射工具类 - FreeBuf网络安全行业门户
关键词:代码生成
以下内容假设读者已简单了解过以上框架,部分内容不再展开
除此以外,其它框架也能实现简单的任务编排能力,但或多或少都会一些不足:
- 只支持任务编排(包括京东也是)
- 单线程顺序执行
- 面向过程,step之间依赖关系不明确,维护成本高,复杂度难于收敛
- 健壮性不够,step异常粗暴地阻断流程,且无超时控制
- 上下文类型强制统一,属性过于集中
- 无性能统计,较难排查哪个step是瓶颈
- 测试难,需要全过程并mock对应数据
……
而本次则尝试探讨任务协同的优劣势(能力不足设计可能有缺陷,权当抛砖引玉,欢迎大家指正或讨论)
编排式vs协同式
| 编排式 | 协同式 | |
| 实现 | 任务的决策和执行顺序逻辑集中在一个编排器类中 | 任务的决策和执行顺序逻辑分布在步骤中 |
| 优势 |
|
|
| 劣势 |
|
|
| 适用 | 业务复杂度不高、团队成员较少 | 业务与团队模块化划分 |
| 挑战 | 数据隔离、拆分边界 | |
可以看出,协同式框架在业务更复杂、团队更细化的场景下更加适用,那么这个所谓的协同式任务框架到底要怎么实现呢
详细设计
首先举例说明现有流程,方便理解:
task A一共3级step,a为第一级,b、c依赖a,e、f依赖b,其中f是非核心
耗时(单位ms):
- a:10
- b:5
- c:7
- e:1
- f:5
需要支持的功能
1、step关系图
说明:显示所有流程的step关系图,方便更快地熟悉整体或仅了解部分
解决:一叶障目
task A关系图如下:
a
__|__
| |
b c
__|__
| |
e f
假设e需要增强时只需要关注a -> b -> e的链接,无需完整了解整体
2、无依赖并行执行
说明:根据关系图划分层级,每层并行执行,提高流程性能。流程A中的b、c无依赖,则可并行执行
解决:服务资源没有充足利用
1: a(10)
__|__
| |
2: b c(7)
__|__
| |
3:e f(5)
可见,顺序单线程耗时为28ms,而并行耗时只需要22ms
3、流程控制
说明:task支持配置超时时间、核心和非核心,非核心发生异常或超时不阻断流程。关系图以“:”标志非核心步骤;支持指定task执行,方便框定测试范围和造数据(白盒测试)
解决:任务健壮度、测试困难
a
__|__
| |
b c
__|__
| :
e f
4、task上下文类型在step内不强制统一
说明:step执行方法的参数类型不强制与任务提交时的上下文一致,框架根据两者的类型匹配出转换mapper显式设置属性(不使用序列化转换,减少cpu压力并防止黑盒属性拷贝),让step只关心其所需属性,减少躁点
解决:上下文类型强制统一
// step A
void execute(A a, Result result);
class A {
private int a;
private int b;
}
// step B
void execute(B b, Result result);
class B {
// 可能有重复属性
private int a;
private String x;
}
// task A,c包含a和b的属性,step执行前转换入参
void execute(C c, Result result);
class C {
private int a;
private int b;
private String x;
private long y;
}5、关键性能日志打印
说明:输出task和step开始/结束时间,task结束时输出每层耗时最长的step
解决:整体与局部性能难于评估,缺少监控
task A start..
step a start..
step a end, sendTime: 10ms
step b start..
step c start..
step b end, sendTime: 5ms
step c end, sendTime: 7ms
step e start..
step f start..
step e end, sendTime: 1ms
step f end, sendTime: 5ms
task A end, sendTime: 22ms, longest step:a, c, f
功能实现
以下设计通过spring starter形式实现
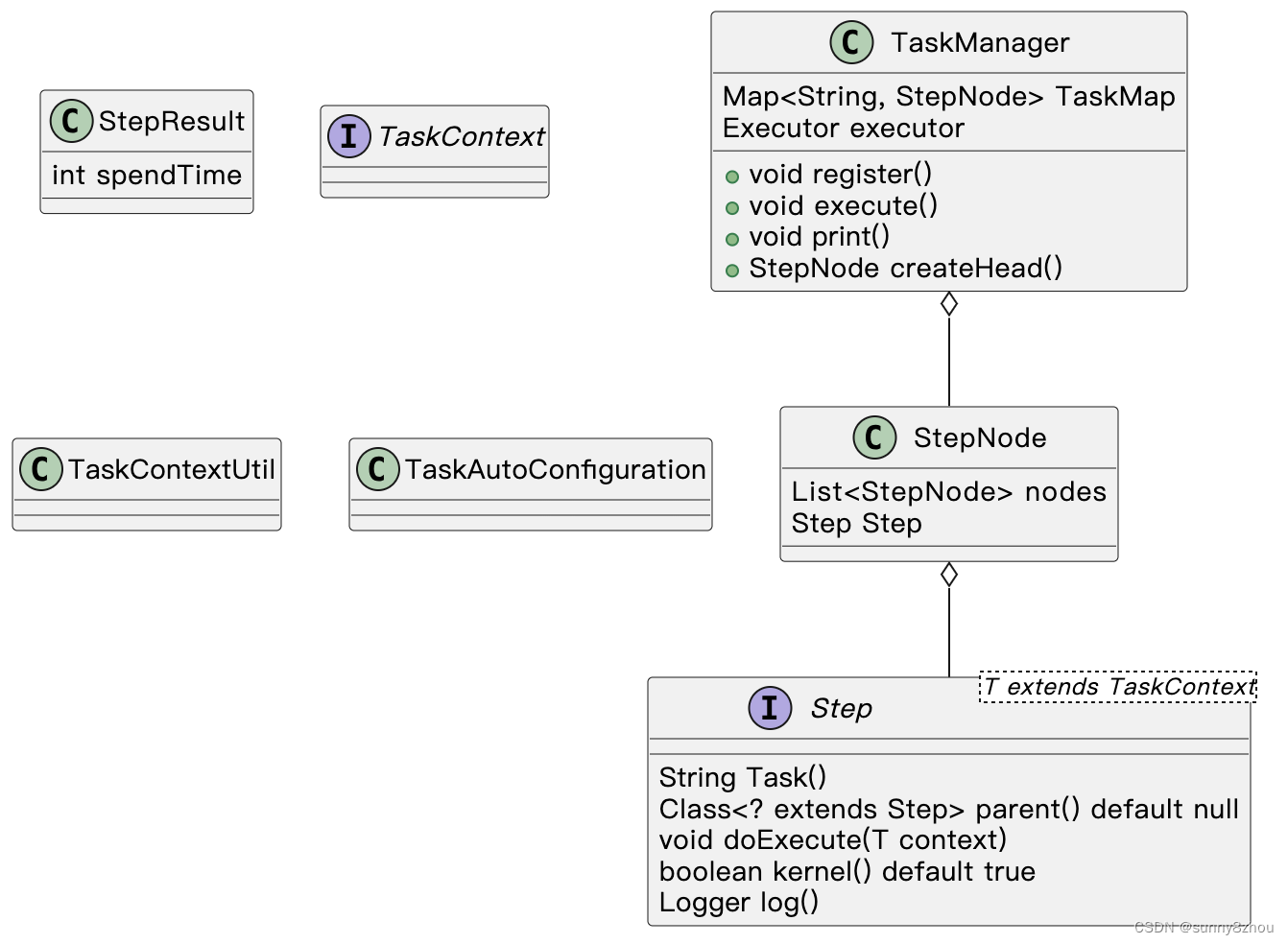
首先,定义框架的类图
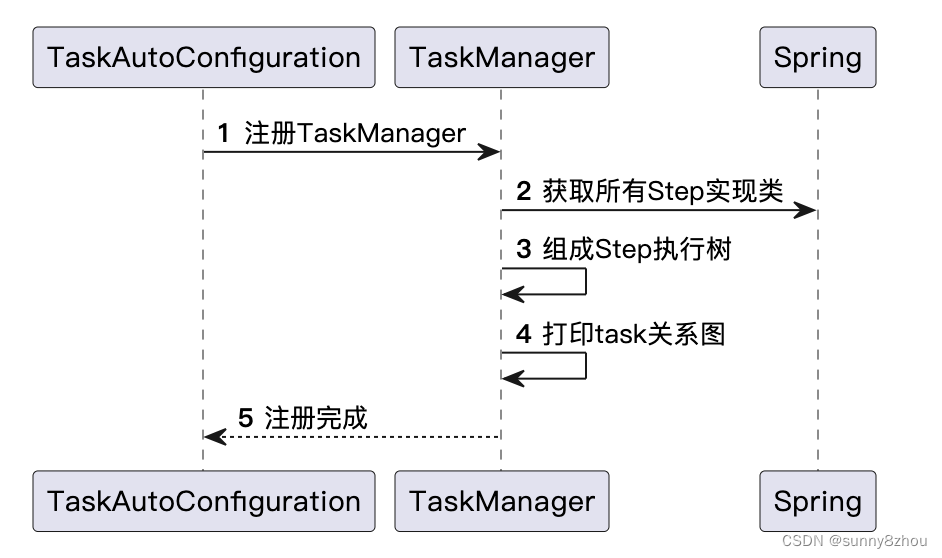
然后定义任务执行流程
项目启动时:
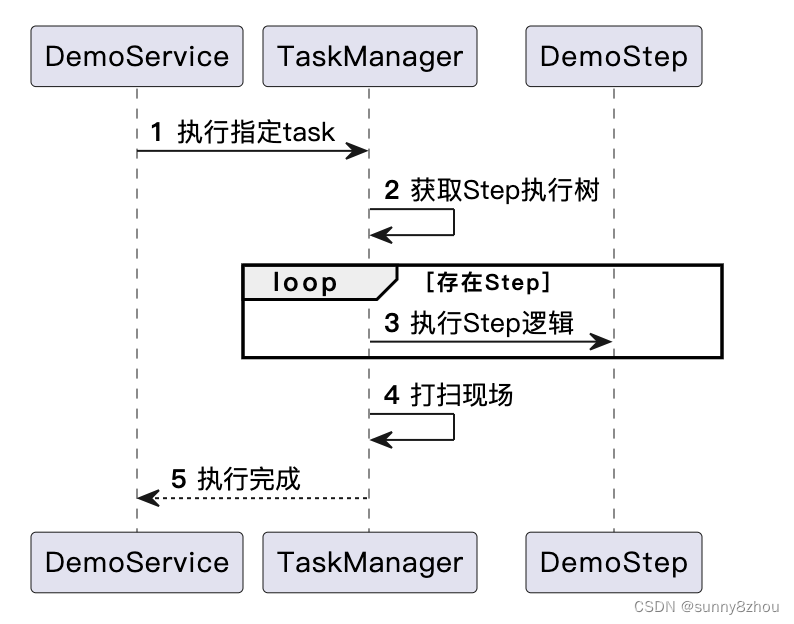
task执行过程:
代码实现
步骤节点StepNode
public class StepNode {
// 多叉树子节点
List<StepNode> nodes;
// 当前节点执行器
Step step;
}步骤Step
interface Step<T extends TaskContext> {
/**
* 指定task
*/
String task();
/**
* 依赖的步骤
*/
default Class<? extends Step> parent() {
return null;
}
/**
* 步骤逻辑
*/
void doExecute(T context);
/**
* 是否核心步骤
*/
default boolean kernel() {
return true;
}
/**
* 实现类日志
*/
Logger log();
/**
* 执行方法
*/
default StepResult execute(T context) {
long startTime = System.currentTimeMillis();
log().info("step start..");
doExecute(context);
long spendTime = System.currentTimeMillis() - startTime;
log().info("step end, sendTime:{}ms", spendTime);
return new StepResult(spendTime);
}
}头节点步骤
@Component
@Slf4j
public class HeadStep implements Step<TaskContext> {
@Override
public String task() {
return "foo";
}
@Override
public void execute(TaskContext context) {
}
@Override
public Logger log() {
return log;
}
}协同管理器TaskManager
@Slf4j
public class TaskManager {
// 所有流程集合
private Map<String, StepNode> taskMap = new HashMap<>();
// 多线程执行器
private Executor executor;
// 超时时间
private long timeout = 1000L;
// 头节点通用执行器
private Step headStep;
/**
* 生成头节点
*/
public StepNode createHead() {
return new StepNode(headStep);
}
/**
* 将所有步骤转化为执行树
*/
public void register(List<Step> stepList) {
}
/**
* 查询节点
*/
private StepNode findStepNode(String task, Class<? extends Step> stepClz) {
}
/**
* 打印task关系图
*/
public void print() {
}
/**
* 执行逻辑
*/
public void execute(String task, TaskContext context) {
this.execute(task, null, context);
}
/**
* 指定步骤执行逻辑
*/
public void execute(String task, Class<? extends Step> stepClz, TaskContext context) {
log.info("task {} start..", task);
long startTime = System.currentTimeMillis();
StepNode node = findStepNode(task, stepClz);
// 记录耗时最长的节点
List<String> spendTimeList = new ArrayList<>();
// BFS
Queue<StepNode> q = new LinkedList<>();
q.offer(node);
while (!q.isEmpty()) {
int sz = q.size();
// 本层耗时最长
int maxSpendTime = 0;
String maxStepName = null;
Map<StepNode, CompletableFuture<StepResult>> completableFutureMap = Maps.newHashMapWithExpectedSize(sz);
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
StepNode cur = q.poll();
completableFutureMap.put(cur, CompletableFuture.supplyAsync(() -> cur.getStep().execute(context), this.executor));
q.addAll(cur.getNodes);
}
for (Map.Entry<StepNode, CompletableFuture<StepResult>> entry : completableFutureMap.entrySet()) {
try {
// 阻塞获取执行结果
StepResult result = entry.getValue().get(timeout, TimeUnit.SECONDS);
// 保存耗时最长节点
if (result.getSpendTime() > maxSpendTime) {
maxSpendTime = result.getSpendTime();
maxStepName = entry.getKey().getStep().getClass().getName();
}
} catch (Exception e) {
log.error("execute fail!", e);
if (entry.getKey().isKernel()) {
throw e;
}
}
}
spendTimeList.add(maxStepName);
}
log.info("task {} end.., spendTime:{}ms, longest step:", System.currentTimeMillis() - startTime, String.join(",", spendTimeList);
}
}spring注册类TaskAutoConfiguration
@Configuration
public class TaskAutoConfiguration {
@Bean
public TaskManager taskManager() {
}
}Demo
定义上下文
public class FooTaskContext implements TaskContext {
private String name;
}定义Step
/**
* 第一个核心步骤
*/
@Component
@Slf4j
public class FooGetNameStep implements Step<FooTaskContext> {
@Override
public String task() {
return "foo";
}
@Override
public void execute(FooTaskContext context) {
context.setName("foo");
}
@Override
public Logger log() {
return log;
}
}
/**
* 第二个非核心步骤
*/
@Component
@Slf4j
class FooNoticeStep implements Step<FooTaskContext> {
@Override
public String task() {
return "foo";
}
@Override
public void execute(FooTaskContext context) {
System.out.print(context.getName());
}
@Override
public Class<? extends Step> parent() {
return FooGetNameStep.class;
}
@Override
public boolean kernel() {
return false;
}
@Override
public Logger log() {
return log;
}
}service调用
@Service
class DemoService {
@Autowire
private TaskManager taskManager;
public void test() {
FooTaskContext context = new FooTaskContext();
taskManager.execute("foo", context);
}
}挑战与未来
不管是编排式还是协同式,都存在不少挑战,但有挑战证明有未来,下面一一讨论
数据隔离风险
举例,task A的执行流程是:step a -> b -> c,其中a修改公共配置库记录,b读取该配置库记录后执行逻辑;此时请求X和Y并发触发task A
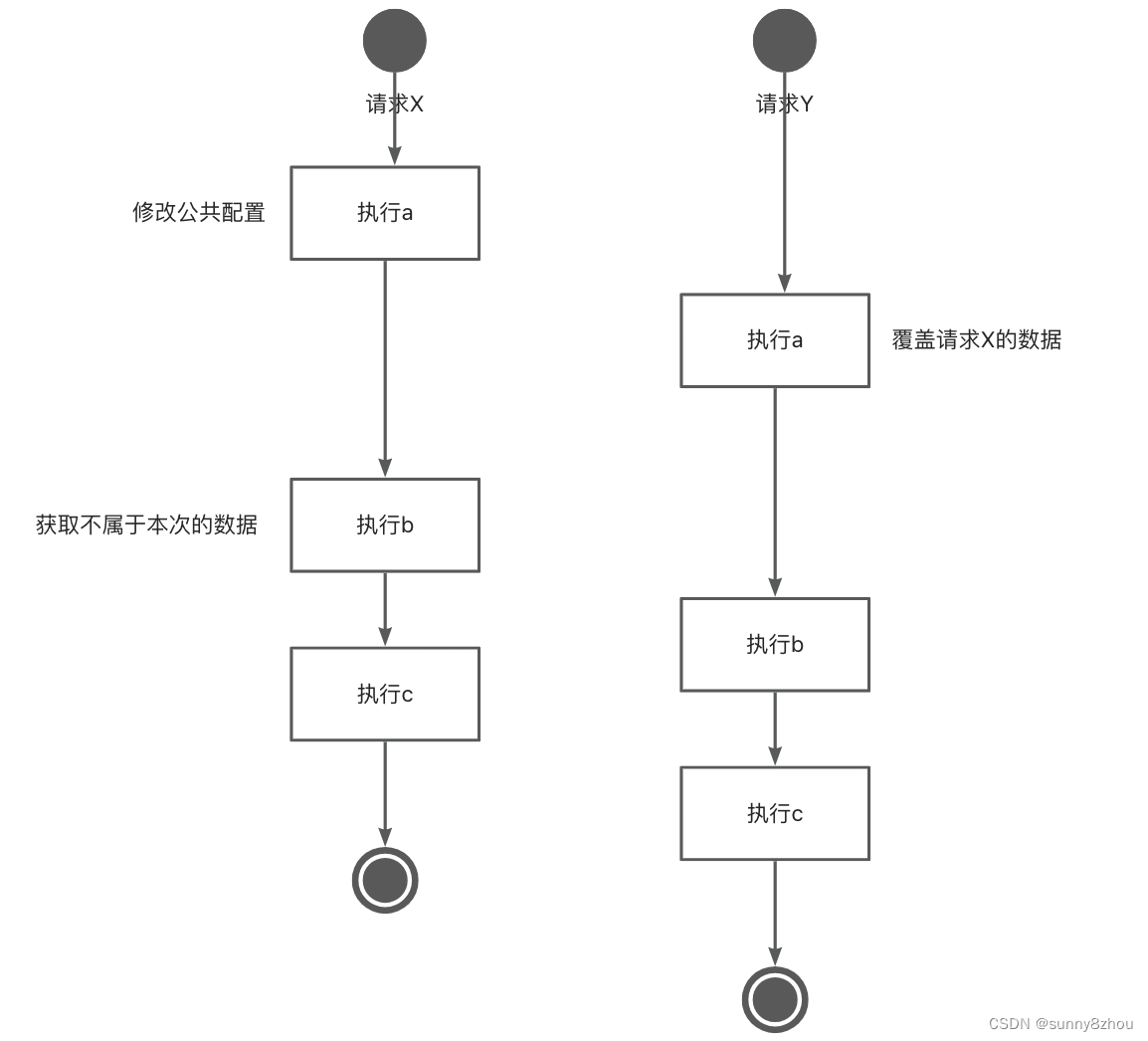
解决方案:
| 优势 | 劣势 | |
| 锁 | 简单 | 性能受损 |
| 事务 | 简单 | 非同一数据库需引入分布式事务 流程较长将占用数据库资源 |
| 获取数据快照,集中执行持久化 | 性能高,资源少 | 对执行顺序敏感 依赖第三方中间件 |
步骤拆分边界
- 如何控制step数量
- 如何界定step职责(或范围)
- 如何防止step腐化
……
参考:DDD
最佳实践
- step单一职责原则
- 无状态计算
- 扁平化
- 单测覆盖,执行RT监控
- 上下文
- Faas
- DDD
……
未来
- 【task上下文类型在step内不强制统一】功能:
- mapstruct:根据两者的类型匹配出转换mapper显式设置属性
- 自动生成匹配mapper:AbstractProcessor、AutoService、javapoet
- 更多并行控制能力
- 资源隔离

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









