







信管1121,201211671117,聂双燕
第一部分:作业要求(完整要求见作业要求)
目标2:在目标1的基础上,增加保存正文文本到文本文件的功能(90分)。
第二部分:程序说明及代码
1.功能:
1.1测试如下三个不同的网页的提取效果,并把结果截图发布到作业博文中: http://blog.csdn.net/quailquailquail/article/details/45821703
http://user.qzone.qq.com/303727350/blog/1430870007
http://www.cnblogs.com/jasondan/p/4145305.html
1.2增加一个保存网页正文到本地的“按钮”,保存位置通过 文件对话框 确定,保存文件名以 博文标题 为准。
2.主要实现代码(借鉴高手):
2.1类Html2Article,文章正文数据模型处理类
// Author: StanZhai 翟士丹(jasondan325@163.com). All rights reserved. See License.md in the project root for license information.
using System;
using System.IO;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
namespace StanSoft
{
/// <summary>
/// 文章正文数据模型
/// </summary>
public class Article
{
/// <summary>
/// 文章标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 正文文本
/// </summary>
public string Content { get; set; }
/// <summary>
/// 带标签正文
/// </summary>
public string ContentWithTags { get; set; }
/// <summary>
/// 文章发布时间
/// </summary>
public DateTime PublishDate { get; set; }
}
/// <summary>
/// 解析Html页面的文章正文内容,基于文本密度的HTML正文提取类
/// Date: 2012/12/30
/// Update:
/// 2013/7/10 优化文章头部分析算法,优化
/// 2014/4/25 添加Html代码中注释过滤的正则
///
/// </summary>
public class Html2Article
{
#region 参数设置
// 正则表达式过滤:正则表达式,要替换成的文本
private static readonly string[][] Filters =
{
new[] { @"(?is)<script.*?>.*?</script>", "" },
new[] { @"(?is)<style.*?>.*?</style>", "" },
new[] { @"(?is)<!--.*?-->", "" }, // 过滤Html代码中的注释
// 针对链接密集型的网站的处理,主要是门户类的网站,降低链接干扰
new[] { @"(?is)</a>", "</a>\n"}
};
private static bool _appendMode = false;
/// <summary>
/// 是否使用追加模式,默认为false
/// 使用追加模式后,会将符合过滤条件的所有文本提取出来
/// </summary>
public static bool AppendMode
{
get { return _appendMode; }
set { _appendMode = value; }
}
private static int _depth = 6;
/// <summary>
/// 按行分析的深度,默认为6
/// </summary>
public static int Depth
{
get { return _depth; }
set { _depth = value; }
}
private static int _limitCount = 180;
/// <summary>
/// 字符限定数,当分析的文本数量达到限定数则认为进入正文内容
/// 默认180个字符数
/// </summary>
public static int LimitCount
{
get { return _limitCount; }
set { _limitCount = value; }
}
// 确定文章正文头部时,向上查找,连续的空行到达_headEmptyLines,则停止查找
private static int _headEmptyLines = 2;
// 用于确定文章结束的字符数
private static int _endLimitCharCount = 20;
#endregion
/// <summary>
/// 从给定的Html原始文本中获取正文信息
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
public static Article GetArticle(string html)
{
// 如果换行符的数量小于10,则认为html为压缩后的html
// 由于处理算法是按照行进行处理,需要为html标签添加换行符,便于处理
if (html.Count(c => c == '\n') < 10)
{
html = html.Replace(">", ">\n");
}
// 获取html,body标签内容
string body = "";
string bodyFilter = @"(?is)<body.*?</body>";
Match m = Regex.Match(html, bodyFilter);
if (m.Success)
{
body = m.ToString();
}
// 过滤样式,脚本等不相干标签
foreach (var filter in Filters)
{
body = Regex.Replace(body, filter[0], filter[1]);
}
// 标签规整化处理,将标签属性格式化处理到同一行
// 处理形如以下的标签:
// <a
// href='http://www.baidu.com'
// class='test'
// 处理后为
// <a href='http://www.baidu.com' class='test'>
body = Regex.Replace(body, @"(<[^<>]+)\s*\n\s*", FormatTag);
string content;
string contentWithTags;
GetContent(body, out content, out contentWithTags);
Article article = new Article
{
Title = GetTitle(html),
PublishDate = GetPublishDate(body),
Content = content,
ContentWithTags = contentWithTags
};
return article;
}
/// <summary>
/// 格式化标签,剔除匹配标签中的回车符
/// </summary>
/// <param name="match"></param>
/// <returns></returns>
private static string FormatTag(Match match)
{
StringBuilder sb = new StringBuilder();
foreach (var ch in match.Value)
{
if (ch == '\r' || ch == '\n')
{
continue;
}
sb.Append(ch);
}
return sb.ToString();
}
/// <summary>
/// 获取时间
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
private static string GetTitle(string html)
{
string titleFilter = @"<title>[\s\S]*?</title>";
string h1Filter = @"<h1.*?>.*?</h1>";
string clearFilter = @"<.*?>";
string title = "";
Match match = Regex.Match(html, titleFilter, RegexOptions.IgnoreCase);
if (match.Success)
{
title = Regex.Replace(match.Groups[0].Value, clearFilter, "");
}
// 正文的标题一般在h1中,比title中的标题更干净
match = Regex.Match(html, h1Filter, RegexOptions.IgnoreCase);
if (match.Success)
{
string h1 = Regex.Replace(match.Groups[0].Value, clearFilter, "");
if (!String.IsNullOrEmpty(h1) && title.StartsWith(h1))
{
title = h1;
}
}
return title;
}
/// <summary>
/// 获取文章发布日期
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
private static DateTime GetPublishDate(string html)
{
// 过滤html标签,防止标签对日期提取产生影响
string text = Regex.Replace(html, "(?is)<.*?>", "");
Match match = Regex.Match(
text,
@"((\d{4}|\d{2})(\-|\/)\d{1,2}\3\d{1,2})(\s?\d{2}:\d{2})?|(\d{4}年\d{1,2}月\d{1,2}日)(\s?\d{2}:\d{2})?",
RegexOptions.IgnoreCase);
DateTime result = new DateTime(1900, 1, 1);
if (match.Success)
{
try
{
string dateStr = "";
for (int i = 0; i < match.Groups.Count; i++)
{
dateStr = match.Groups[i].Value;
if (!String.IsNullOrEmpty(dateStr))
{
break;
}
}
// 对中文日期的处理
if (dateStr.Contains("年"))
{
StringBuilder sb = new StringBuilder();
foreach (var ch in dateStr)
{
if (ch == '年' || ch == '月')
{
sb.Append("/");
continue;
}
if (ch == '日')
{
sb.Append(' ');
continue;
}
sb.Append(ch);
}
dateStr = sb.ToString();
}
result = Convert.ToDateTime(dateStr);
}
catch (Exception ex)
{
Console.WriteLine(ex);
}
if (result.Year < 1900)
{
result = new DateTime(1900, 1, 1);
}
}
return result;
}
/// <summary>
/// 从body标签文本中分析正文内容
/// </summary>
/// <param name="bodyText">只过滤了script和style标签的body文本内容</param>
/// <param name="content">返回文本正文,不包含标签</param>
/// <param name="contentWithTags">返回文本正文包含标签</param>
private static void GetContent(string bodyText, out string content, out string contentWithTags)
{
string[] orgLines = null; // 保存原始内容,按行存储
string[] lines = null; // 保存干净的文本内容,不包含标签
orgLines = bodyText.Split('\n');
lines = new string[orgLines.Length];
// 去除每行的空白字符,剔除标签
for (int i = 0; i < orgLines.Length; i++)
{
string lineInfo = orgLines[i];
// 处理回车,使用[crlf]做为回车标记符,最后统一处理
lineInfo = Regex.Replace(lineInfo, "(?is)</p>|<br.*?/>", "[crlf]");
lines[i] = Regex.Replace(lineInfo, "(?is)<.*?>", "").Trim();
}
StringBuilder sb = new StringBuilder();
StringBuilder orgSb = new StringBuilder();
int preTextLen = 0; // 记录上一次统计的字符数量
int startPos = -1; // 记录文章正文的起始位置
for (int i = 0; i < lines.Length - _depth; i++)
{
int len = 0;
for (int j = 0; j < _depth; j++)
{
len += lines[i + j].Length;
}
if (startPos == -1) // 还没有找到文章起始位置,需要判断起始位置
{
if (preTextLen > _limitCount && len > 0) // 如果上次查找的文本数量超过了限定字数,且当前行数字符数不为0,则认为是开始位置
{
// 查找文章起始位置, 如果向上查找,发现2行连续的空行则认为是头部
int emptyCount = 0;
for (int j = i - 1; j > 0; j--)
{
if (String.IsNullOrEmpty(lines[j]))
{
emptyCount++;
}
else
{
emptyCount = 0;
}
if (emptyCount == _headEmptyLines)
{
startPos = j + _headEmptyLines;
break;
}
}
// 如果没有定位到文章头,则以当前查找位置作为文章头
if (startPos == -1)
{
startPos = i;
}
// 填充发现的文章起始部分
for (int j = startPos; j <= i; j++)
{
sb.Append(lines[j]);
orgSb.Append(orgLines[j]);
}
}
}
else
{
//if (len == 0 && preTextLen == 0) // 当前长度为0,且上一个长度也为0,则认为已经结束
if (len <= _endLimitCharCount && preTextLen < _endLimitCharCount) // 当前长度为0,且上一个长度也为0,则认为已经结束
{
if (!_appendMode)
{
break;
}
startPos = -1;
}
sb.Append(lines[i]);
orgSb.Append(orgLines[i]);
}
preTextLen = len;
}
string result = sb.ToString();
// 处理回车符,更好的将文本格式化输出
content = result.Replace("[crlf]", Environment.NewLine);
content = System.Web.HttpUtility.HtmlDecode(content);
// 输出带标签文本
contentWithTags = orgSb.ToString();
}
}
}
2.2类UrlUtility,Url处理辅助类
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
namespace StanSoft
{
/// <summary>
/// Url处理辅助类
/// </summary>
public class UrlUtility
{
/// <summary>
/// 基于baseUrl,补全html代码中的链接
/// </summary>
/// <param name="baseUrl"></param>
/// <param name="html"></param>
public static string FixUrl(string baseUrl, string html)
{
html = Regex.Replace(html, "(?is)(href|src)=(\"|\')([^(\"|\')]+)(\"|\')", (match) =>
{
string org = match.Value;
string link = match.Groups[3].Value;
if (link.StartsWith("http"))
{
return org;
}
try
{
Uri uri = new Uri(baseUrl);
Uri thisUri = new Uri(uri, link);
string fullUrl = String.Format("{0}=\"{1}\"", match.Groups[1].Value, thisUri.AbsoluteUri);
return fullUrl;
}
catch (Exception)
{
return org;
}
});
return html;
}
}
}
2.3类FrmMain,主窗体实现类
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.IO;
using System.Diagnostics;
using StanSoft;
namespace Demo
{
public partial class FrmMain : Form
{
public FrmMain()
{
InitializeComponent();
}
string content = "";
string title = "";
private void btnOk_Click(object sender, EventArgs e)
{
if (String.IsNullOrEmpty(this.urlTextBox.Text))
{
MessageBox.Show("请输入网址!");
return;
}
// 保存用户输入的Url,和追加模式设置
Properties.Settings.Default.Save();
this.webBrowser.Navigate(this.urlTextBox.Text);
this.webBrowser.DocumentCompleted += webBrowser_DocumentCompleted;
SetDownloadState();
}
private void webBrowser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (e.Url != this.webBrowser.Document.Url)
{
return;
}
string encode = this.webBrowser.Document.Encoding;
StreamReader sr = new StreamReader(this.webBrowser.DocumentStream, Encoding.GetEncoding(encode));
string html = sr.ReadToEnd();
//Html2Article.LimitCount = 100;
//Html2Article.Depth = 8;
// 设置是否使用正文追加模式
Html2Article.AppendMode = this.appendCheckBox.CheckState == CheckState.Checked;
Stopwatch sw = new Stopwatch();
sw.Start();
// 将Html解析为Article结构化数据
Article article = Html2Article.GetArticle(html);
sw.Stop();
msgLabel.Text = "提取耗时:" + Environment.NewLine + sw.ElapsedMilliseconds + "毫秒";
this.publishDateTextBox.Text = article.PublishDate.ToString();
this.titleTextBox.Text = article.Title;
title = article.Title;
this.contentTextBox.Text = article.Content;
content = article.Content;
string articleHtml = UrlUtility.FixUrl(this.urlTextBox.Text, article.ContentWithTags);
this.contentWebBrowser.DocumentText = articleHtml;
ResetState();
}
private void SetDownloadState()
{
this.btnOk.Text = "下载中...";
this.btnOk.Enabled = false;
this.publishDateTextBox.Text = "";
this.titleTextBox.Text = "";
this.contentTextBox.Text = "";
this.msgLabel.Text = "";
}
private void ResetState()
{
this.btnOk.Text = "提取正文";
this.btnOk.Enabled = true;
}
private void FrmMain_Load(object sender, EventArgs e)
{
}
private void button1_Click(object sender, EventArgs e)
{
using (StreamWriter sw = new StreamWriter("D:\\"+title+".txt"))
{
sw.WriteLine(content);
}
}
}
}
3参考资料链接:
3.1Html2Article代码来源
第三部分:运行结果
1.加入保存文件按钮后主界面:
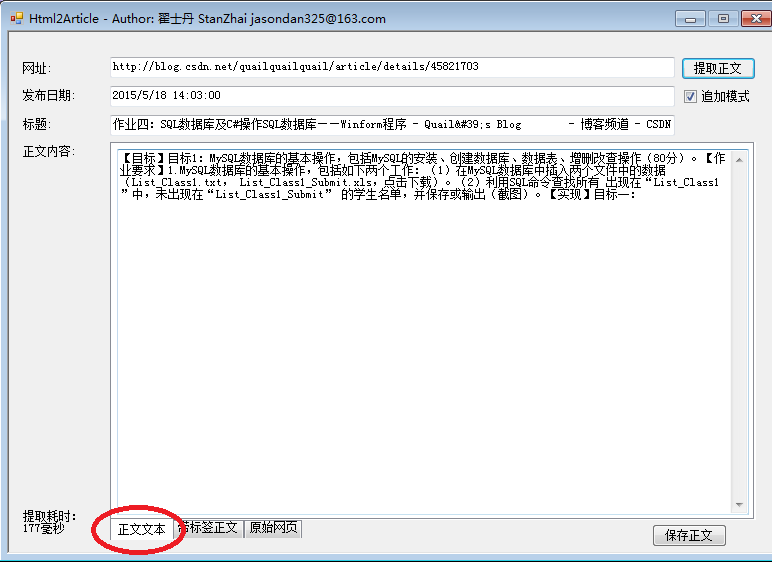
2. http://blog.csdn.net/quailquailquail/article/details/45821703结果截图:
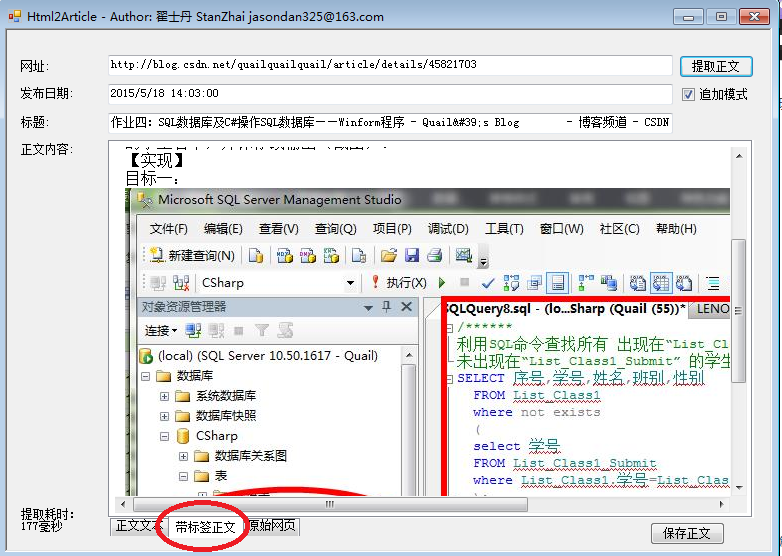
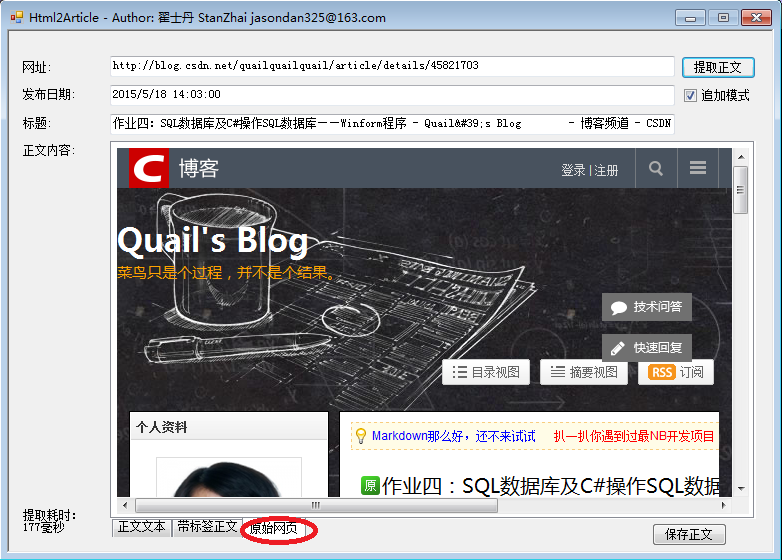
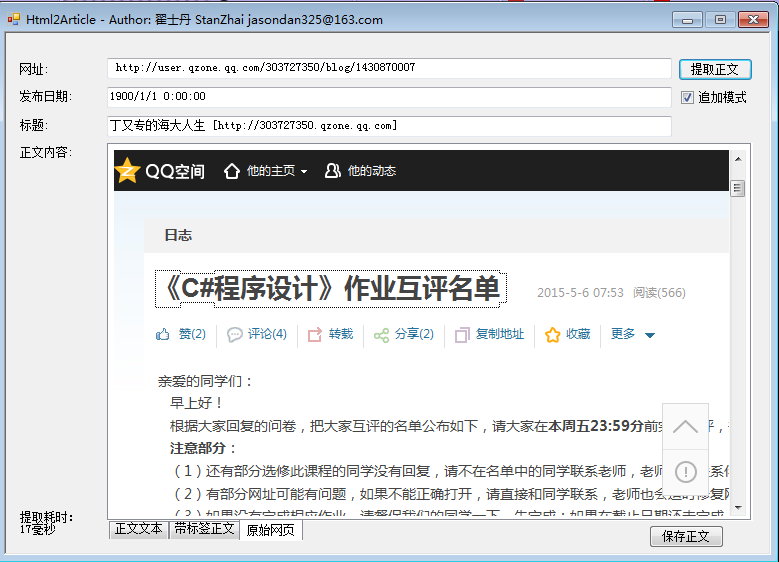
3. http://user.qzone.qq.com/303727350/blog/1430870007结果截图:
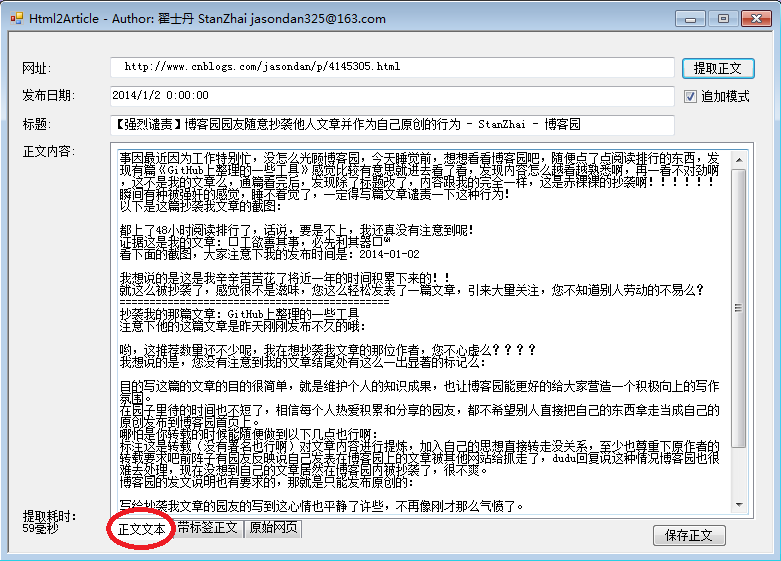
4. http://www.cnblogs.com/jasondan/p/4145305.html结果截图:
5. 文件效果截图:

第四部分:收获体会
这次作业没有完成老师的要求,没能利用保存文本框完成保存文件要求,实在找不到获取保存文件文本框的绝对路径的方法.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









