






package basicsTest;
public class Sort{
public static void main(String[] args) {
int[] num=new int[]{2,5,6,8,7,9,3,1,4};
Sort sort=new Sort();
//int[] valnumber1=sort.bubble(num);
//int[] valnumber2=sort.insert(num);
int[] valnumber3=sort.shell(num);
for(int i=0;i<valnumber3.length;i++){
System.out.println(valnumber3[i]);
}
}
//冒泡排序
public int[] bubble(int[] num){
boolean flag=true;
for(int i=num.length;i>0&&flag;i--){
flag=false;
for(int j=0;j<i-1;j++){
//如果前面脚标的大于后面脚标的
if(num[j]>num[j+1]){
int x=num[j];//定义一个空位置,以前面(x)为地址位置
num[j]=num[j+1];//小的放前面
num[j+1]=x;//大的放后面
flag=true;
}
}
}
return num;
}
//插入排序,和冒泡差不多
public int[] insert(int[] num){
int i,j;
for(i=1;i<num.length;i++){
int target=num[i];//第二张要插入的牌
//手里有几张牌就挪动几个位置
for(j=i;j>0&&num[j-1]>target;j--){//把手里的牌都比一遍num[j-1]代表A ,从小到大
num[j]=num[j-1];//j-1 是第一张牌,移动东位置,大的向后移动一个
}
num[j]=target;//新牌放位置循环了一次就剪了
}
return num;
}
//希尔排序
public int[] shell(int[] num){
int i,j;
int arrlength=num.length;
for(int k=arrlength/2;k>0;k/=2){//希尔排序,2间隔
for(i=k;i<num.length;i++){
int target=num[i];//第二张要插入的牌
//手里有几张牌就挪动几个位置
for(j=i;j>=k && num[j-k]>target;j-=k){//把手里的牌都比一遍num[j]代表A
num[j]=num[j-k];//j-1 是第一张牌,移动东位置,大的向后移动一个
}
num[j]=target;//新牌放位置循环了一次就剪了
}
}
return num;
}
}
java递归写出冒泡排序
public class Demo{
public void sortArray(int[] array,int m,int n) {
if(m>0){
if(array[n]<array[n-1]) {
swap(array,n);
}
if(n>=m){
sortArray(array,m-1,1);
}else {
sortArray(array,m,n+1);
}
}
}
void swap(int[] array,int k) {
int temp = array[k];
array[k] = array[k-1];
array[k-1]= temp;
}
public void showArray(int[]array) {
for(int i = 0;i<array.length;i++) {
System.out.println(array[i]);
}
}
public static void main(String[] args) {
Demo demo = new Demo();
int[] a = new int[]{3,5,1,2,8,33,22,11,0};
demo.sortArray(a,a.length-1,1);
demo.showArray(a);
}
}
java递归写出冒泡排序
因为你的 ArrayList 存放元素大小是固定的,并且在事先已经指定并开僻了 1000 个容量的数组空间,实际上只是对数组进行了操作。
而 LinkedList 是采用链表实现的,在事先无法指定容量,每添加一个数据都得去开僻新的空间。
如果在添加时这样进行比较的话,对于 LinkedList 是很不公平的。
对于迭代来说,ArrayList 速度远比 LinkedList 慢,因为链表迭代是很快的,如果要让 ArrayList 比 LinkedList 快的话,可以使用下标索引。
一般来说,ArrayList 和 LinkedList 具体使用哪一个以下这些我总结的使用规则:
1:事先能预知元素数量时,应优先选择 ArrayList,并且在构造中进行初始化
2:事先不能预知元素数量时,根据不同的迭代需要选择 ArrayList 或者 LinkedList
3:如果有很多的 remove 操作时,应优先选择 LinkedList
4:需要顺序迭代,也就是从第一个元素开始一个一个地访问到最后一个时,应优先选择 LinkedList
5:需要随机访问,也就是使用 get(int) 方法取任意下标访问时,应优先选择 ArrayList

TreeSet唯一性以及有序性底层剖析
TreeSet底层原理
TreeSet底层数据结构是红黑树(一种自平衡的二叉树,自平衡是指如果有空的左/右子树,元素会先入空的左/右子树,而不会一直往一个方方向添加元素出现不平衡现象)。
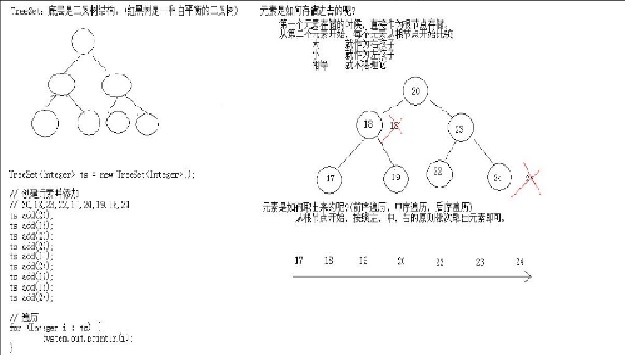
该自平衡二叉树保证了元素的有序性(存储逻辑顺序),因为按照前、中、后三种顺序都可以有序的读取到集合中的元素。
下面是关键底层源码:
发现add方法中调用了TreeSet中的一个成员变量m.put()方法。
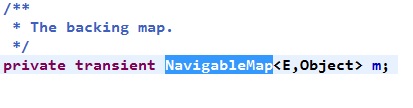

而NavigableMap是一个接口,但是它有一个实现类是TreeMap:

那么,就应该看看TreeSet中该m变量的初始化到底是哪个实现类了:
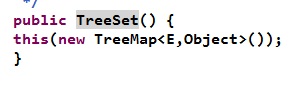
看到默认构造器中为TreeMap,则可以知道m.put()方法实际调用的是TreeMap中的put()方法,跟踪进入源码:


总结:通过观察TreeSet的底层源码发现,TreeSet的add(E e)方法,底层是根据实现Comparable的方式来实现的唯一性,通过compare(Object o)的返回值是否为0来判断是否为同一元素。
compare() == 0,元素不入集合。
compare() > 0 ,元素入右子树。
compare() < 0,元素入左子树。
而对其数据结构:自平衡二叉树做前(常用)、中、后序遍历即可保证TreeSet的有序性。

















 5755
5755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









