






原文链接: https://www.jdon.com/44815
在12月11日新的有关DDD CQRS和Event Sourcing演讲:改变心态- 以更加面向对象视角看待业务领域建模中,作者以足球比赛football Match为案例说明传统编程方法和CQRS的区别。
CQRS作为DDD的最佳实践已经得到广泛承认和普及,下面摘取该文章的PPT部分图片简单讲解一下,如何使用CQRS和Event Sourcing实现DDD系统。
首先,领域专家对需求进行定义:
1.举办一个比赛,有两个队参加
2.比赛在某个时间开始,只能开始一次。
3.比赛结束后,统计积分
作为用户,希望看到:
1.参加比赛的队伍名称
2.比赛开始时间
3.比赛结束时间
4.比赛结束后的分数。
好了,搜集到这些需求以后,我们下一步该怎么办呢?
1.如何确定建模的第一步?
2.它是如何和关系数据库有关?
3.建模时如何考虑到用户的操作?获得他们想要看到的数据?
4.当建模时你更关心什么?
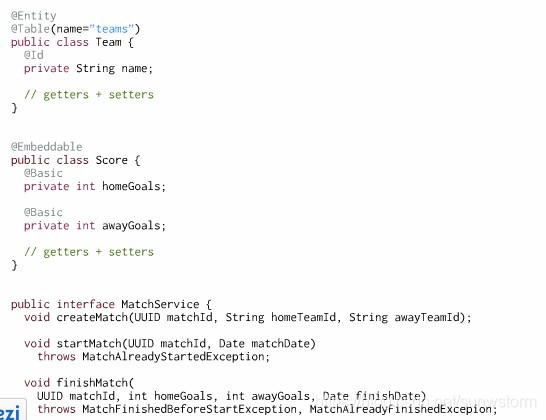
传统方式从上面需求中,根据名词或动词法则,得到下面类:
Match比赛
Team队伍
Score分数
MatchService
类的代码如下图所示,并且有Hibernate等ORM的元注解:
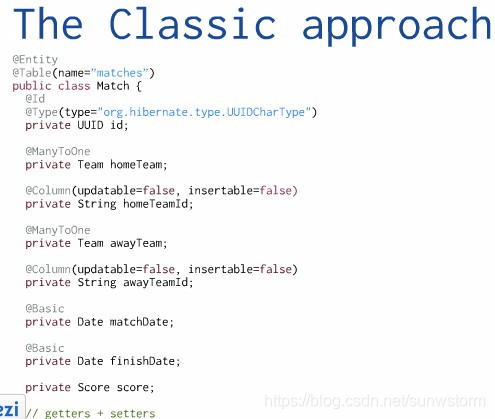
好像很简单,但是这是面向对象吗?这是符合封装原则吗?这是贫血失血模型,对象只有属性,没有自己的行为方法,有的只有setter/getter方法而已。
那么我们从哪里开始改变?如何改变?
并不是从数据开始。而是从头开始,统一语言。
我们重新开始看看领域专家是如何描述需求的:
1.举办一个比赛,有两个队参加
2.比赛在某个时间开始,只能开始一次。
3.比赛结束后,统计积分
从这个需求中,我们会发现有一个聚合词语Aggregate: Match比赛。
这个比赛模型可以涵括需求的大部分。
那么“Match比赛”模型无疑是一个实体,是聚合根。它的重要特点是内部有状态,而且不能向外直接暴露这种状态;通过聚合根实体和外界进行交互。
通过实体“Match比赛”模型,可以创建值对象:两个队伍的名称,对象Team值对象,值对象是不可变的。
我们可以根据一个比赛名称开始一个比赛。我们也可以结束一个比赛,这时有值对象分数Score,也具有不可变性。
这样聚合根“Match比赛”有下列特点:
1.有自己的生命周期
2.有自己的事务边界。
3.克服了危险的setter方法
4.聚合体内:分数Score 队伍team和日期等模型是值对象不可变。
因为不可变,我们只留getter方法给它们,用户通过getter方法获得他们想要的数据视图。
这样, Match比赛 聚合根实体的代码如下,相当于将原来MatchService的代码移到实体类的方法中,再也没有了服务:

在Match类中,我们只有getter方法,只有把不可变的值对象提供外部访问getter的方法,如果我们将可变的状态提供给外部访问,外部的事务边界将会改变内部的状态,相当危险。
这样的代码代表富模型,充血模型,有如下好处:
1.有动词的模型
2.数据和操作数据的行为捆绑。
3.可以反应统一语言。
下面一步,我们再想想,如果也去除了getter方法如何?那么如何产生出给用户看的视图数据呢?
这时,我们也许注意到,我们是在从用户角度来看这个模型,而之前我们是从领域专家角度看模型,不同角度对模型的要求不同。
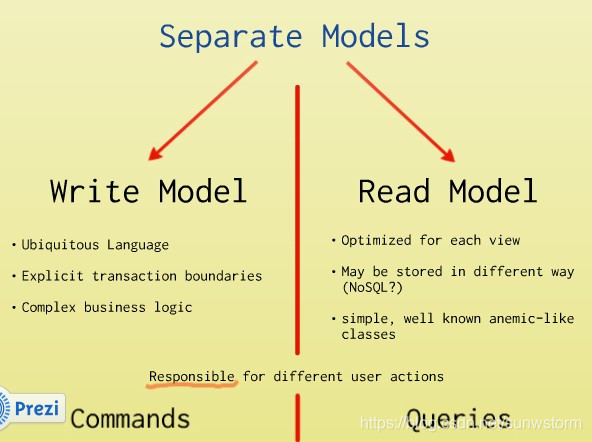
那么,我们索性从读写两个方面去看待模型,这就是CQRS:
写模型: 统一语言,显式的事务边界,复杂的业务逻辑。
读模型:专门为读优化(缓存等),有不同的SQL如NoSQL分析,简单的类组成。
下一步,如何让数据满足这些模型:how feed it with data,如果说我们已经撑起来骨架,那么数据是领域模型的血液,如何将血液输送到模型中呢? 数据一般会保存在数据库或各种NoSQL中。
使用事件Event。事件的特点:
1.可以描述状态变化,事件驱动状态改变。
2.准确描述已经发生什么,而不是将要发生什么或也许发生什么。
3.相对小。
4.无业务逻辑
5.可以由业务方法产生。
6.可以发送到队列Queue,异步。
那么,我们在实体模型Match中的方法中增加事件代码如下:


CQRS中读操作的View Model视图模型可以从事件中导出,这样,我们得保存事件,传统数据库+事件数据会产生重复数据,必须保证事件的一贯性。
由于序列化的事件可以保存在关系数据库 NoSQL 或文件中。我们必须采取分布式事务吗?相当复杂,不如只采取一种数据库形式,哪一种呢?虽然关系数据库很可怕,但是在mapping join query上比较稳定。可以采取关系数据库存储事件,用来保证事件的前后连续性。
当这些过去的事件被回放时,聚合体能够重新激活他们自己。
这样聚合根实体代码要做些改变,增加方法回放事件,将状态封装在回放方法中,这时就必须移除原来ORM元注解了。
Match类的代码改变如下:

带来的思维改变,我们考虑聚合根不再聚焦在字段属性上,而是职责 方法和行为上。
对于聚合根中的字段,我们只需要那些能够改变业务方法行为的字段(banq注:状态,只有状态字段能改变业务行为),其他数据都被归纳入事件对象中。
在Match类中,是否结束这种状态对业务行为影响大,因此,代码改变最后如下:

最后,我们和传统编程思路对比一下:
传统思路第一步是考虑数据,将数据从行为中分离,然后将数据建模成数据库表结构Schema,这实际是企业的Turbo Pascal。
所以,问题关键是:首先考虑什么?
首先考虑的应该是语言language,也就是统一语言,将统一语言用在代码中,考虑我们的模型能够做什么?然后开始暴露其行为,行为才联系到数据,有行为才有数据(banq注:而不是从数据倒退行为)。
我们总是问自己:
为什么?它做什么?它的职责应该干什么?
这样,我们自然有了分离关注,有了CQRS。
对于CQRS的写操作:我们考虑的是,这样功能函数能够改变系统的哪些状态呢?
对于CQRS的读操作:我们考虑的是:我们在什么地方展示给用户什么数据视图?
那么,自然地事件将被引入:
领域中发生了什么事件;
什么状态被改变;
事件也可以用作持久机制。
可以还原整个历史。
最后强调:考虑业务过程而不是数据。
业务过程看上去是什么?怎么取名,有哪些行为参与改变了。
这样我们才站在冰山之顶:(全文完)















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









