







springboot的数据访问
springboot中对应数据库的访问方式,默认底层默认采用整合spring data技术进行处理和操作,所以可以对于关系型或者非关系型数据库都可以轻松访问。下面主要针对jdbc、mybatis、spring data jpa的方式来进行数据访问。
一.springboot中数据访问-jdbc
我们前面了解到spring框架中内嵌的jdbc的数据层访问主要通过jdbcTemplate类来操作对应sql语句的访问的,当然一些前期工作数据源、数据库连接配置等相关操作,在springboot自动封装的框架中,肯定都简化了。只要简单的操作就欧了。那些原理前面了解就ok了。
1.1入门演示
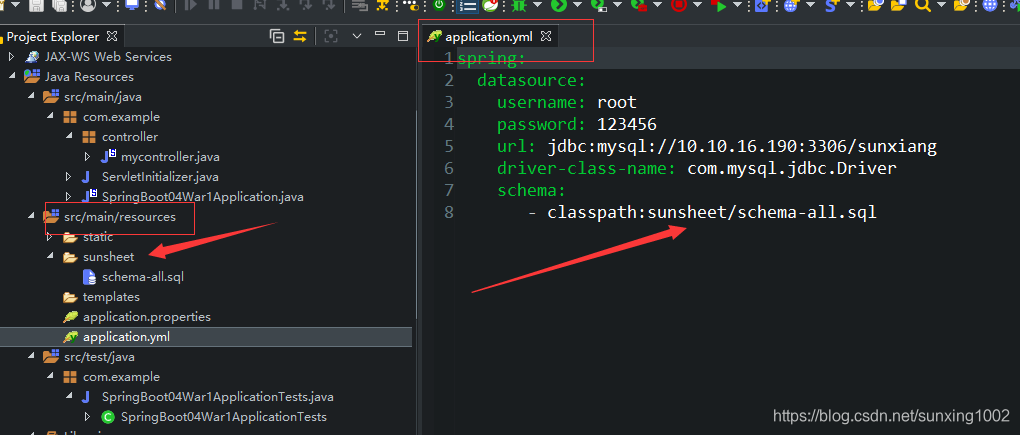
(1)首先肯定要配置数据源连接,springboot中就在配置文件中设置这些属性:这边用yuml语法设置的实现,没有用properties。
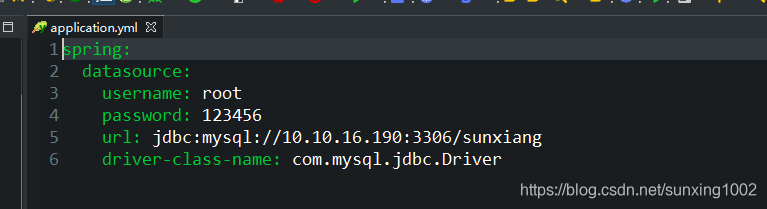
(1.1)这边有个细节,就是上图中驱动类com.mysql.jdbc.Driver是哪个驱动管理类加载的(数据库驱动管理类加载驱动),然后会获取真正驱动接口的实现,那么springboot中对应jdbc默认使用的数据源管理类是哪个呢?这边这个数据源管理类的意思是管理数据驱动和包含有连接数据库基本信息(url、密码等)的一个类,这种类我们以前见过有c3p0或者dpcp等。但这边是用的是tomcat.jdbc的数据源。
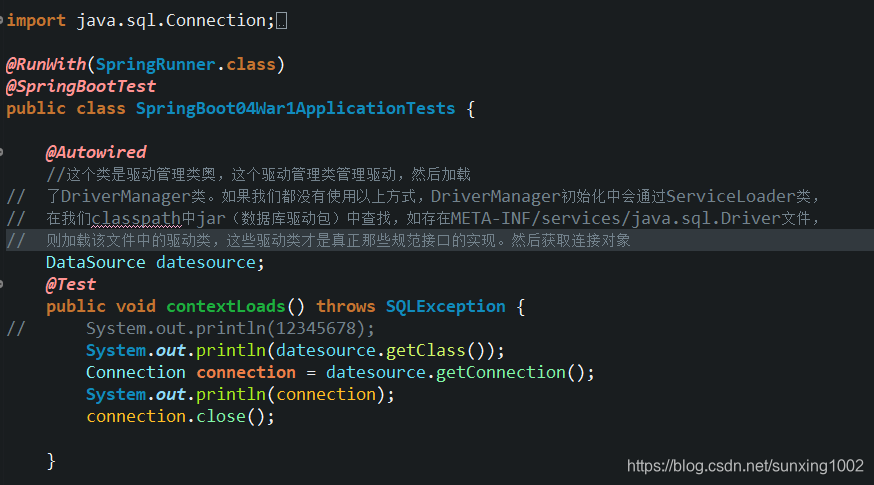
由于配置文件中都对对该驱动管理类进行属性注入了,那么该类肯定已经是被注册到容器了,所以就可以直接@autowire获取该驱动管理类实例(bean)。

(2)下面好像突然不知道干嘛了,springboot都是自动配置的,那首先看配置类,从配置类中了解原理过程。springboot开发要有一种意识:先明确是何技术、直接找该技术的自动配置类xxxautoconfiguration、还有一个配置属性类xxx.properties这两个核心类,要特别注意。然后看这类中:什么bulider(构建器)呀,什么initial(初始化)呀都可以随便看看。还有一些xxxconfigurer(属性扩展类)、xxxcustomizer(属性定制类)。都注意注意。总比没目的看好吧!
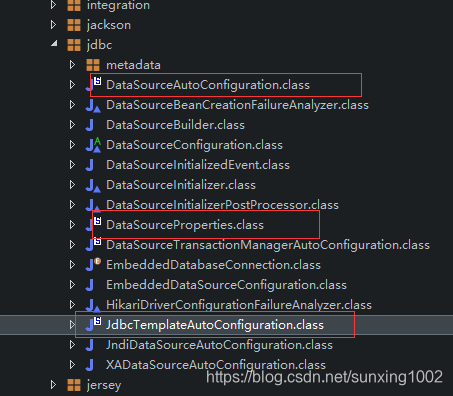
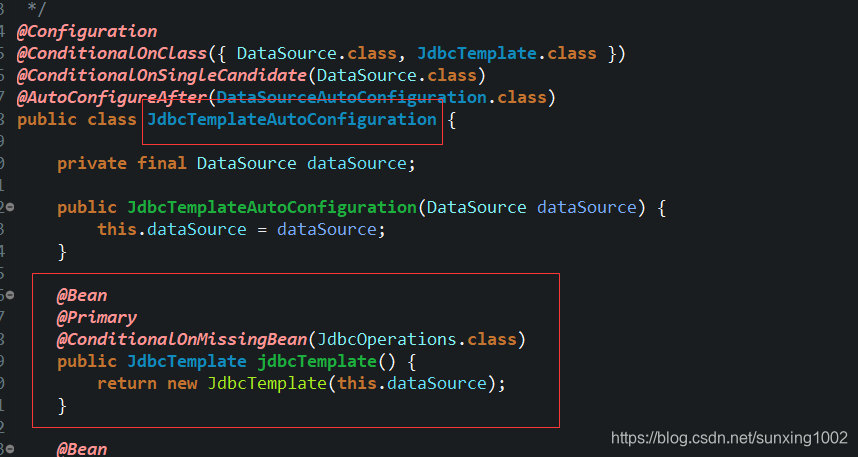
(3)我们之前了解过spring中内嵌的数据库访问的jdbc的方式,核心是jdbcTemplate类,看上图中有jdbcTemplate,进入源码发现如下:直接已经注入容器了,那么我们就可以直接使用了。
(4)直接测试类中属性注入来获取jdbcTemplate;好像目前为止入门就做了两件事:一个是手动配置数据连接,另一个就是数据库访问代码编写了。当然,里面还有好多东西,这个只是入门的演示。
package com.example.controller;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
public class mycontroller {
@Autowired
JdbcTemplate jdbcTemplate;
@ResponseBody
@RequestMapping("/jdbc")
public List<Map<String , Object>> show() {
List<Map<String, Object>> queryForList = jdbcTemplate.queryForList("select * from user");
return queryForList;
}
}
1.2自动构建数据库中表的构建
由上面入门可见springboot中对应数据访问的方式简化了很多,入门很简单,但实际上肯定不止那些呀!下面分析可以在项目中直接辅助构建数据库中表结构的部分。
- 首先看数据源自动配置类,注意里面一些什么初始化的类,这些类中往往会设置一些通用且有用的一些操作。下图可见,可以辅助的操作:数据源连接好数据库后,那么也可以直接通过在指定的表结构文件来自动帮助创建表的结构。表结构命名规则按照:schema-xx.sql; 表中插入数据的文件规则:data-xx.sql;
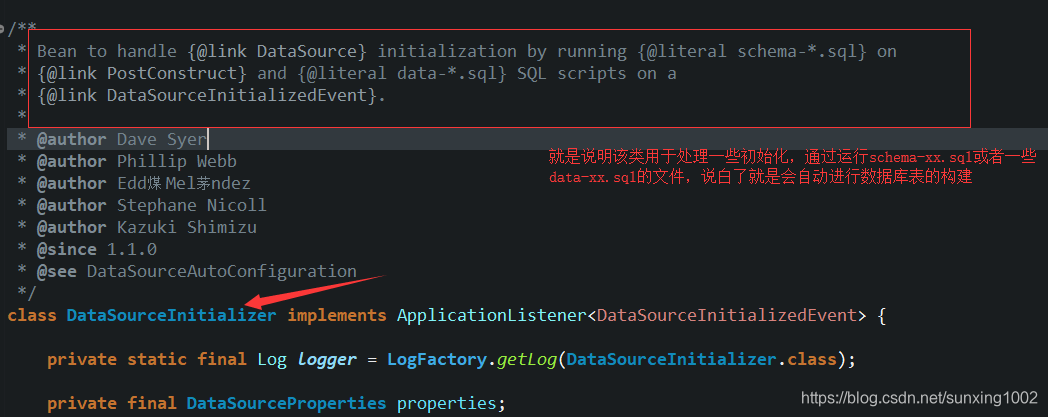
- 除了建表名称有约束外,还有这个建表文件所在位置也有规定,看源码中可知,在classpath:schema-xx.sql或者data-xx.sql都默认会自动寻找的,但下图源码中可见,有两个return,则表明除了有默认路径外,还可以自定义设置属性来确定路径。直接在配置文件中设置schema:xxxxxx就可以自定义,这个表结构的路径位置和文件名称。
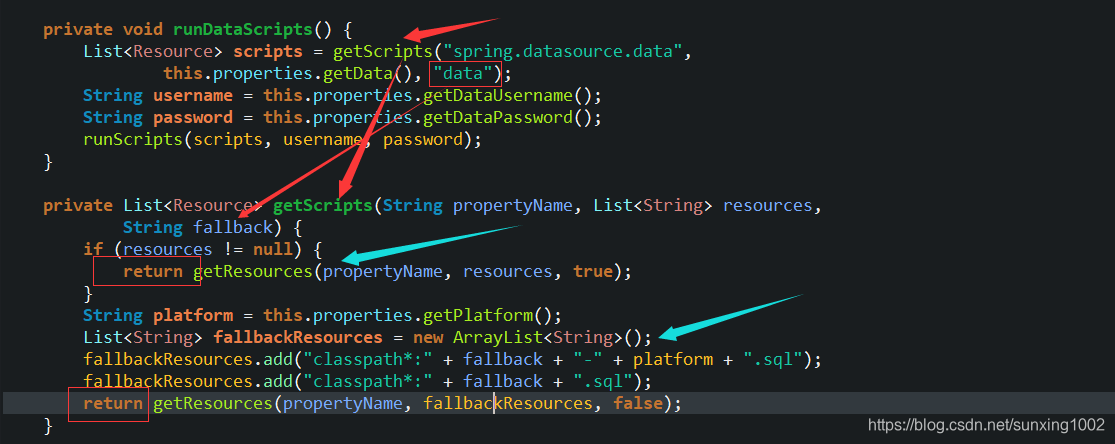
- 分析一下为什么schema属性中定义就可以自定义表结构文件位置和名称呢?还是上图分析吧(省截图太多)!首先运行插入表数据的方法runDataScripts(),里面方法getScripts(“spring.datasource.data”,his.properties.getData(), “data”)确定文件位置,而且这个方法里面有两个return,一个是默认指定的路径,一个哪个就是自定义的,而且上图中有个。强调一下,schema和data都是数据库文件,只是schema是表结构的创建、data是表中数据插入的文件,操作方法一样。
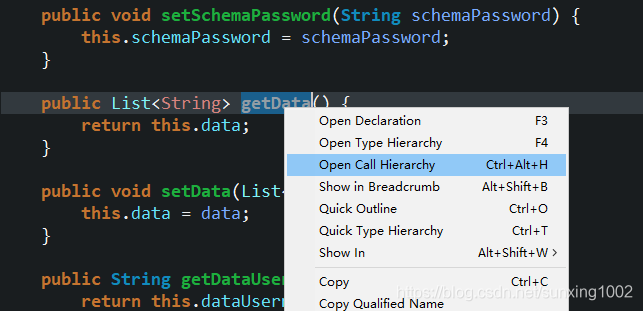
- 从属性文件中输入注入的方法getdata(),直接寻址到其对应的调用位置,就正好知道直达这个操作数据库文件的方法。所以可以通过配置文件中自定义位置路径。
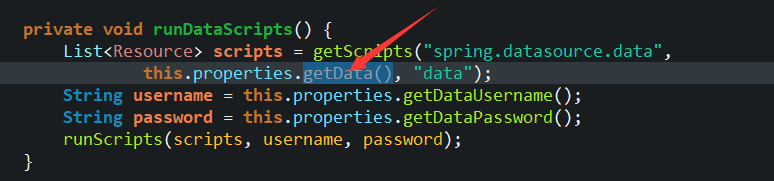
- 在配置文件中设置自定义表结构的路径,然后实验发现,确实可以在数据库中实现表的创建。还是比较方便的。减少切换sql客户端的次数。
2.springboot常用数据源(数据源驱动管理器)
上面我们知道springboot中默认使用时内置的数据源,但是通常我们开发不用,常使用DruidDataSource或者HikariDataSource数据源。DruidDataSource这个由成套的数据源的监控和安全机制,HikariDataSource运行效率要高,目前使用阿里的DruidDataSource。
(2.1)首先设置自定义的数据源,在属性配置文件中设置:spring.datasource.type:com.alibaba.druid.pool.DruidDataSource这样就使用自定义的数据源了(这个外来数据源是数据源配置类中通过反射技术将这个数据源给配置和创建的),但是这个数据源中一些属性的注入怎么设置呢,springboot中属性注入通常在组件注册(注册bean)进容器的过程中,在这个bean上添加注解@ConfigurationProperties(prefix=“spring.datasource/xxx”)和属性配置文件中设置属性的方式完成的。
所以自己配置这个组件
@Configuration
public class mydatasource {
// 这边自己定义这个bean组件进入容器,这样顺带可以设置和配置文件中进行配置属性的映射,springboot中自动配置一般都是由条件判断的
// 如果没有自定义组件,才会自动向容器中注入组件的。@conditionalonbean
@Bean
@ConfigurationProperties(prefix="spring.datasource")
public DataSource druid() {
return new DruidDataSource();
}
}
===============================================
spring:
datasource:
username: root
password: 123456
url: jdbc:mysql://10.10.16.190:3306/sunxiang
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
(2.2)阿里这个数据源于成套的监控机制,所以可以配置这些功能:
配置对这个数据源的监控;监控肯定通过图形界面来监控呀!所以这个druid数据源包中肯定也有相关servlet的设置(即管理后台的servlet请求【statviewservlet这个类,也是druid数据库配套打包的类。这个类内部都设置好了一些访问的请求处理和返回的响应信息】)。注意!!!这个servlet类是外部定义且封装的一个servlet,就和我们原生servlet那边学习的一样。但是springboot中jar包没有xml,所以这个servlet映射的话(就是传统在web.xml中设置映射内容)。springboot中类似的做法是将这个servlet在ServletRegistrationBean类中注册进去就OK了,作用和以前在xml中配置url映射一样。简单说就是这个ServletRegistrationBean就相当于一个这个servlet的web.xml配置文件
二.springboot中数据访问-mybatis
实际上,springboot中整合mybatis就是配置都自动化,其他本质还是mybatis的实现,这边如果有点生疏可以看:mybatis的详解。
2.1注解方式的springboot整合mybatis准备
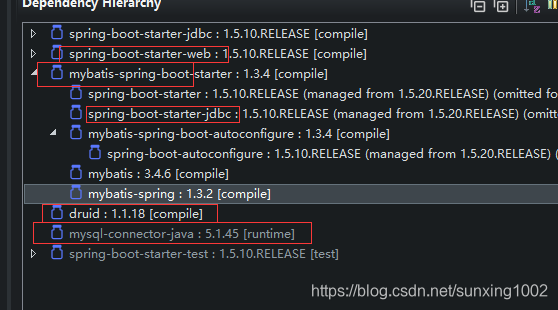
(1)首先,肯定要映入springboot的mybatis的依赖环境,springboot内部没有自己的mybatis的整合包,这个是mybatis自家整合springboot的一个环境依赖,当然这里面都有:
(2)创建数据源相关类型的配置:确定用哪个数据源、还有数据源中那些属性设置。这个也比较关键,就这上面一节特意详解了数据源。
(3)数据库中表数据的准备
(4)数据库库中表所对应的java的bean准备,便于框架能够完美自动映射。
2.2 注解版mybatis的实现
我们知道mybatis实现数据的访问,核心要两个配置文件:一个全局配置文件(数据源等连接信息),另一个是具体的sql的语句信息设置即mapper映射文件(mapper.xml,里面是许多具体sql语句执行的信息)。
(1)springboot中对应全局配置文件都封装实现了,就是自动配置类完成了,我们只要简单确定数据源类型就OK了,那么还有映射文件的配置呢?这个就是下面springboot中比较关键的部分了,映射文件转为在接口中注解的方式来替代了。
(2)核心的注解@mapper。就是告知springboot这个类是映射文件,即告知这个类就是一个操作数据库的mapper。里面就是有具体sql语句、sql语句的输入参数、输出参数。 实际上这不就是原生mybatis那边的mapper接口开发的过程嘛(只不过那边是接口和映射文件分开,而这边通过注解方式两个组合只通过接口体现出来了)!
注解实现
主要就是映射文件的实现: ( 注解中映射文件的sql实现是@select、@insert、@delete等这些注解实现的。@mapper表示映射的操作标识,就是那些sql中参数映射到方法的对应变量上,或者反向的过程等,即sql中字段的输入参数和sql执行后输出的数据库内容的自动映射到java的方法上对应的方法输入和方法的返回对象中。)
package com.example.mapper;
import org.apache.ibatis.annotations.Delete;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Options;
import org.apache.ibatis.annotations.Select;
import org.apache.ibatis.annotations.Update;
import com.example.bean.user;
@Mapper
//这边就是mybaits那边的sql映射文件的作用,以前是在sql映射文件中中编写sql语句还有语句的输入参数和输出参数。
public interface UserMapper {
@Select("select * from user where id=#{id}")
public user getuserbyid( Integer id);
@Options()
@Update("update user set name=#{name} where id=#{id}")
public int updateuserbyid(user u);
@Options(useGeneratedKeys = true,keyProperty = "id")
@Insert("insert into user(id,name,gender,birth_day) values(#{id},#{name},#{gender},#{birthDay})")
public int insertuser(user u);
@Delete("delete from user where id=#{id}")
public int deleteuser(Integer id);
}
然后实现: 这边有个细节注意:就是上面定义的接口为啥可以直接注入生成对象呢?接口是如何生成实现对象的呢?这边实现肯定有个前提:就是这个实现的方式是固定通用或者死板的,所以才可以由框架自动生成的,要是灵活多变的,还真以为框架多人工智能呀!。详细可以见mybatis中原生dao开发方式——接口实现的过程
package com.example.control;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.example.bean.user;
import com.example.mapper.UserMapper;
@RestController
public class usercontroller {
@Autowired
UserMapper map;
@RequestMapping("/getuser/{id}")
//根据id查询用户信息
public user getuser(@PathVariable("id")Integer id) {
user getuserbyid = map.getuserbyid(id);
return getuserbyid;
}
@RequestMapping("/deleteuser/{id}")
//根据id删除数据中指定记录
public int deleteuser(@PathVariable("id")Integer id) {
int deleteuser = map.deleteuser(id);
return deleteuser;
}
@RequestMapping("/updateuser")
public user updateuser(user u) {
map.updateuserbyid(u);
user getuser = getuser(u.getId());
return getuser;
}
@RequestMapping("/adduser")
//增加用户的信息到数据库中
public user insertuser(user u) {
map.insertuser(u);
return u;
}
}
分析:上面实现过程有几个细节点
- 配置文件和映射文件的实现:配置文件已经交由spring容器实现,映射文件交由注解@mapper和@select、@insert等完成sql编写,输入参数和输出参数的映射,所以注解版中免去手动两个文件的编写,本质是存在的。
- 接口UserMapper为什么可以直接@autowire注入。 实际上要是还记得原生mybatis那边,接口的实现过程的话,就容易理解了,在映射文件和接口中方法都确定后,接口的实现是固定的由sqlsession对象的getmapper(xxxmapper.class)方法获取xxxmapper接口的代理对象。 当然接口中方法在这个代理对象中肯定也实现了(就是基于映射文件中sql语句和输出输出参数类型实现的)。再详细点实际上是由sqlsession对象的getmapper(xxxmapper.class)方法获取xxxmapper接口的代理对象的本质就是:
一切都是由mybatis的会话工厂和会话对象实现的(如下),而且这一过程所有接口实现都是一样固定的,所以才可以封装由框架自动实现的。要不然怎么可能帮我们将接口直接返回接口的实现对象呢,要不然还真以为像人一样灵活、创造和随机应变啦!
Public interface UserDao {
public User getUserById(int id) throws Exception;
public void insertUser(User user) throws Exception;
}
===================================
Public class UserDaoImpl implements UserDao{
public UserDaoImpl(SqlSessionFactory sqlSessionFactory){
this.setSqlSessionFactory(sqlSessionFactory);
}
private SqlSessionFactory sqlSessionFactory;
@Override
public User getUserById(int id) throws Exception {
SqlSession session = sqlSessionFactory.openSession();
//spring整合后该条语句变成:SqlSession session = getSqlSession();
User user = null;
try {
//通过sqlsession调用selectOne方法获取一条结果集
//参数1:指定定义的statement的id,参数2:指定向statement中传递的参数
user = session.selectOne("test.findUserById",id);
System.out.println(user);
} finally{
session.close();
}
return user;
}
配置文件实现
springboot中注解的mybatis方式中免去手工整合一些配置文件和完全免去单独映射文件的编写,而这边配置文件的方式中映射文件还是要单独编写的,(更正一下,前面注解版的配置文件也要简单设置一些,但是只设置一些基本参数数据)就类似于原生mybatis的接口实现的整个过程!但是过程前期的一些环境配置都由springboot自动实现了,所以也还是省了许多琐事。
- 首先还是数据源的设置(这个由springboot的属性配置文件中管理的,所以在属性配置文件中配置:spring data type:com.alibaba.druid.pool.DruidDataSource,密码和用户也都这样配置)。
spring:
datasource:
username: root
password: root
url: jdbc:mysql://localhost:3306/sun
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
- 然后接口的编辑,这边接口中没有@select、@insert注解了,就一个@mapper注解,负责关联映射文件中映射功能。
- 编写配置文件、映射文件,这边实际配置文件中数据源这些都交由spring管理了,所以mybatis的配置文件中就设置一些mybatis全局的一些扩展属性的。映射文件很关键,和以前映射文件一样,里面要配置详细的sql语句,输入参数类型,输出参数类型
@Mapper
public interface employeemapper {
public employee getemployeebyid(Integer id) ;
public void addemployee(employee e);
}
-------------------------------------------------------------
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- public employee getemployeebyid(Integer id) ;
public void addemployee(employee e); -->
<mapper namespace="com.example.mapper.employeemapper">
<select id="getemployeebyid" resultType="com.example.bean.employee" parameterType="int">
select * from employee where id = #{id}
</select>
<insert id="addemployee" parameterType="com.example.bean.employee">
insert into employee(lastName,gender,email,d_id) values(#{lastName},#{gender},#{email},#{did})
</insert>
</mapper>
- 然后就是mybatis的接口开发一样,直接获取接口的实现对象,调用接口中方法。这边实现对象获取也简单了,因为都由springboot交由容器提前自动实现了,所以直接从容器中获取接口的实现就可以了;所以在测试类中直接@autowire注解从容器中获取接口的实现对象就OK了,然后调用这个实现方法,就可以了。
- 配置文件实现过程中核心就上面两步:接口编写,还有配置文件的设置,实际还有个细节是配置文件的位置必须明确(原生mybatis中实际上也对配置文件和映射文件有规定的,在原生mybatis环境中如果在默认位置就不用配置,但这边是springboot框架环境所以这边设置文件(配置文件和映射文件)位置也很合理,即要告诉springboot框架,你配置文件和映射文件在哪)
//也是在springboot的配置文件中设置mybatis的配置文件的位置属性。这边是用的yml格式的。当然可以用properties格式。
mybatis:
config-location: classpath:mapper/mybatis-config.xml
mapper-locations:
- classpath:mapper/employeemapper.xml
三.springboot中数据访问-Spring Data(JPA方式)
前言
实际上这边要关注的思想:接口是如何自动由框架生成该接口的实现的。为什么要明确这个呢?本质是spring data中提供了统一的功能接口,让我们自定义自己接口来继承这些接口,这样我们自定义的接口就具有这些统一接口的功能了。值得注意的是,我们自定义的接口实现都不用我们管,spring data框架自动帮我们实现。当然接口的那些功能也肯定实现了,我们直接调用方法就OK了。
上面的过程:是不是就是我们最初学java的时候一直梦寐以求的事情,直接写出什么功能的接口,然后自动生成这些功能的实现 如果想要简单理解这样过程可以参照mybatis的接口实现dao的开发方式过程,这只是类比的理解(简单说就是这些实现肯定都是依据规定的约束,然后经过通用固定死板的实现的,所以框架才能自动帮我们封装自动实现,这种过程一定会常听见一个词:规范),详细spring data的理解,我也不是很了解(哈哈)
简介
spring data是spring公司为了简化spring框架进行数据访问的一项技术,这个技术既支持关系型数据库访问也支持非关系型数据库的访问。它下面有许多子项目/模块,分别支持不同类型数据访问的,如MongoDB、redis、JPA(java 持久层)。spring data的目的旨在使用统一的api来对数据访问层的操作(无论关系型或者非关系型数据库都通过统一标准来实现(实际上本质是springdata提供了一些统一接口,然我们自定义接口来继承这些接口就可以了)。)这个标准中包含了基本的增删改查、排序、分页等操作。
综合简单分析(重点!!!)
(一)jdbc的数据访问实现核心:(1)自动配置(整体大环境自动搭建)(2)简单属性设置(数据源,数据库连接)(3)jdbctemplate自动注入对象(该对象中直接和sql操作)
(二)mybatis的数据访问实现:(1)自动配置(整体大环境自动搭建)(2)简单的属性设置(数据源,数据库连接)(3)表结构对应的实体类准备(方便自动完成数据库中表记录和java中对象数据的相互映射)(4)mybatis的接口(作用:关联sql映射文件,且执行sql文件中sql语句和输入参数输出参数的自动映射)和sql映射文件的分开操作(注解版是两个结合的,配置文件版是分开的,这样结构清晰不混乱、且解耦合。)
(三)JPA的实现:(1)自动配置(整体大环境自动搭建)(2)简单属性设置(即在属性配置文件中设置数据源,数据库连接)这个好像所有数据访问都要设置的步骤。(3)开始实体类准备,同时在实体类中注解来自动生成数据库中对应的数据表结构(4)定义自己的接口,并集成所需功能的接口(如一些接口有分页,排序功能;一些接口有基本增删改查的功能;还有其他类,或者傻瓜式继承japrepository接口)。这些继承功能接口之后,也不用我们实现,spring data自动帮助实现这些接口并注册进容器了,我们后面直接容器中@autowire注入就可以调用这些实现类了,然后直接使用其中功能方法,是不是简单多了。
JPA的实现(操作数据库)
(1)JPA是spring data中的一个java持久层API,是一个数据访问层的规范,它规范里面有:通过注解来简化数据库的操作(如直接定义数据表对应的实体类的时候,同时通过注解来自动生成数据库中对应的数据表结构)。这个规范的实现有:hibernate、toplink、openJPA等。spring data中默认使用hibernate来完成接口的实现的。 所以是基于ORM(对象关系映射object relational mapping)思想的。
(2)jap数据访问过程:核心三步走:(1)实体类并明确映射关系、(2)自定义一个接口并更加所需功能继承对应功能的统一接口、(3)直接通过接口的实现类来操作实体映射对应的数据表。
- 首先,所有的数据访问都必须先数据库的连接操作——数据源配置、数据库链接访问、数据库账号。密码
- 由于JPA默认使用hibernate的原理来实现规范(AIP)的,所以JPA是基于ORM(对象关系映射)思想的,所以JPA首先要编写一个实体类(传统hibernate中orm映射关系是在配置文件中配置的。但jpa中就简单多了,直接几个注解就明确了映射关系,然后也自动生成映射表)
- 实体类中和表结构的映射关系只需通过几个注解:(1)@entity(表明这个实体类是和表映射的实体类,不是一般实体类)、(2)@table(name=“xxx”)【表示和哪个表名的映射】、(3)@id(明确实体类中哪个属性是表结构中的主键)、(4)@GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键、(5)@column(明确哪些属性是表结构中列字段)等就明确了映射关系了。
//使用JPA注解配置映射关系
@Entity //告诉JPA这是一个实体类(和数据表映射的类)
@Table(name = "tbl_user") //@Table来指定和哪个数据表对应;如果省略默认表名就是user;
public class User {
@Id //这是一个主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键
private Integer id;
@Column(name = "last_name",length = 50) //这是和数据表对应的一个列
private String lastName;
@Column //省略默认列名就是属性名
private String email;
- 最后编写一个Dao接口用于对这些数据表的操作【编写一个Dao接口来操作实体类对应的数据表(Repository统一接口)】(增删改查等操作)。spring data中提供了统一的Repository接口,该接口中有对数据库中各种功能操作方法。实际上web开发过程按照分层思想:dao层是完成直接和数据库操作的一层,就是dao层中接口里面的某一个方法是实现对数据库中某一个功能的操作的。现在JAP开发直接实现了dao层接口里面的方法,所以我们可以通过接口的实现类直接使用这些功能的方法完成数据库的具体操作。(spring data是如何根据接口完成实现的:由于有统一接口的规范,所以实现过程就是固定统一的,所以JAP帮助自动实现的)
//继承JpaRepository框架提供的统一接口来完成对数据库的操作。这个就是类似于web开发中的dao层接口,是一样的。
//功能是对数据库的操作,好像以前dao层的接口实现里面,抽象方法的实现里面都是直接通过Sql语句或者Hql语句完成的吧!
//由于里面方法名是固定的,所以方法的功能也是固定的,所以里面的实现sql语句也应该是固定的,所以才可以由spring data
//自动完成抽象方法的实现吧!
public interface UserRepository extends JpaRepository<User,Integer> {
}
- 上面基本实现了JPA和数据库的访问,但还有一些JPA的设置:如
spring:
jpa:
hibernate: # 更新或者创建数据表结构 生成策略
ddl‐auto: update
# 控制台显示SQL;JPA和数据访问的sql执行的语句
show‐sql: true
上面就是JPA的实现过程;
小结
- JPA数据访问的过程简单就是:(1)创建连接、(2)由于基本ORM,所以编写实体类,并在实体类中直接完成表的映射、(3)直接编写自定义的dao层接口,并继承所需功能的springdata提供对的统一功能接口。下面就是对JPA数据访问的其他属性设置(如自动生成表策略、是否控制台显示sql或者hql语句等)就over了。接口的实现也不用我们管,自动实现了,后面我们直接使用dao层里面方法就OK了。
- 实际上上面实现过程就类似hibernate实现过程,只不过一些配置文件呀、属性和表字段映射呀(确实简化很多,不用在映射文件中一个字段一个字段映射了)、dao层的实现呀、都不用我们自己复杂的编写了,都简化了然后给我们直接使用了。
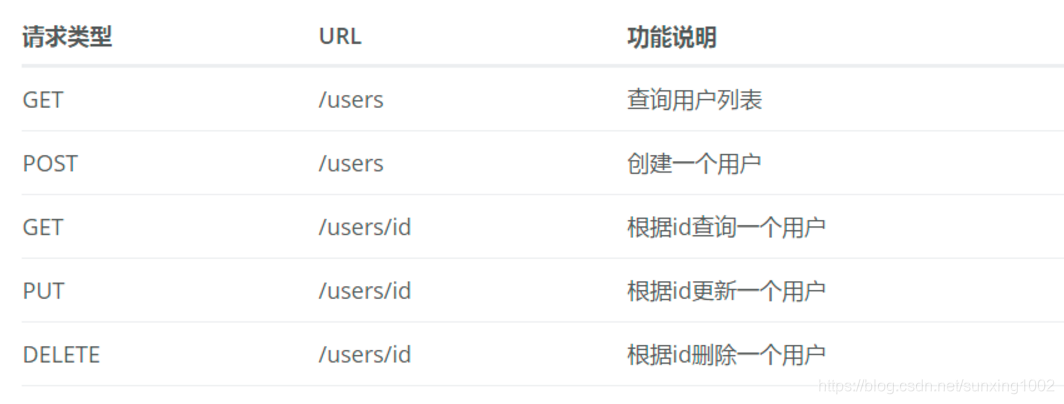
前后交互的开发风格常按照restful风格:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









