







内容来源:https://www.jiqizhixin.com/articles/2019-01-30-15
简介
在本文中,我们将研究Seaborn,它是Python中另一个非常有用的数据可视化库。Seaborn库构建在Matplotlib之上,并提供许多高级数据可视化功能。
尽管Seaborn库可以用于绘制各种图表,如矩阵图、网格图、回归图等,但在本文中,我们将了解如何使用Seaborn库绘制分布和分类图。在本系列的第二部分中,我们将了解如何绘制回归图、矩阵图和网格图。
下载Seaborn库
我们可以通过几种方式下载seaborn库。如果您正在为Python库使用pip安装程序,您可以执行以下命令来下载这个库:
pip install seaborn
或者,如果您正在使用Python的Anaconda发行版,您可以使用以下命令来下载seaborn库:
conda install seaborn
在BigQuant平台上,你可以跳过这一步,直接在策略编写中import seaborn,即可使用
数据集
我们选取财报数据17年到19年的数据进行绘制,首先在策略模板中输入如下代码:
import numpy as np
import pandas as pd
import seaborn as sns df = DataSource('financial_statement_CN_STOCK_A').read(start_date='2017-01-01',end_date='2019-01-02')
#删除Na值,否则后续绘图会报错,在进行数据挖掘时,数据清洗也同样十分重要
df = df.dropna() df.head()
'df.head()'显示了df的前五行:

分布图
sns.distplot(df['fs_roe'])
这里绘制的是各个股票的净资产收益率(fs_roe),结果如下: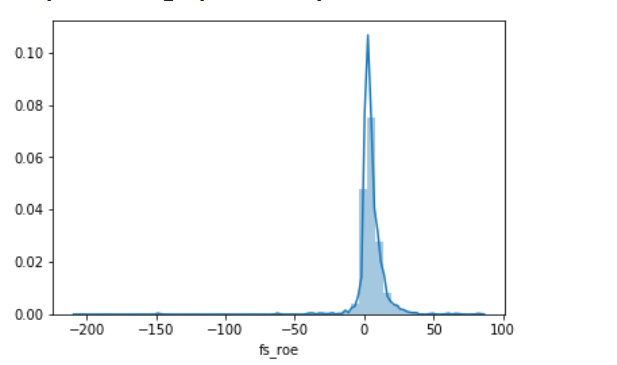
联合分布图
jointplot()用于显示各列的相互分布。您需要向jointplot传递三个参数。第一个参数是要在x轴上显示数据分布的列名。第二个参数是要在y轴上显示数据分布的列名。最后,第三个参数是数据帧的名称。
我们来画一个净资产收益率(fs_roe)和总资产报酬率 (TTM)(fs_roa_ttm)的联合分布图看看能不能找到两者之间的关系,代码如下:
# 这里kind='reg'表示在画完连接图后,做出两者之间的线性关系
sns.jointplot(x='fs_roe', y='fs_roa_ttm', data=df,kind='reg')

从图中我们可以发现两者有一定的线性关系。本文为了简洁,只使用了财务报表的数据。其中’kind’一栏代表图形类型,可使用 scatter,reg,resid,kde,hex…此处不再赘述
Pair Plot
paitplot()是一种分布图,它基本上为数据集中所有可能的数字列和布尔列的组合绘制联合图。您只需要将数据集的名称作为参数传递给pairplot()函数,如下所示:
df_0 = DataSource('west_CN_STOCK_A').read(start_date='2017-01-01',end_date='2019-01-02') df_0 = df_0.dropna() sns.pairplot(df_0)
由于财报数据列数过多,这里我们使用一致预期(west_CN_STOCK_A)
从pair plot的输出中,您可以看到一致预期中所有数字列和布尔列的分布图。

要将分类列的信息添加到pair plot中,可以将分类列的名称传递给hue参数。
sns.pairplot(dataset, hue='你想用来分类的列')
本文选取的报表分类效果均不理想,读者可以使用自己找到的例子自行尝试、感受。
Rug Plot
ugplot()用于为数据集中的每个点沿x轴绘制小条。要绘制rug图,需要传递列的名称。我们来画个小的rug plot。
sns.rugplot(df['fs_roe'])

从输出中可以看到,与distplot()的情况一样,fs_roe的大多数实例的值都在(-50,50)之中。
Bar Plot
barplot()用于显示分类列中的每个值相对于数字列的平均值。第一个参数是分类列,第二个参数是数值列,第三个参数是数据集。例如,如果您想知道各个股票营业收入这段时间的平均值,您可以使用如下的条形图。
sns.barplot(x='instrument', y='fs_operating_revenue', data=df)

如图,横坐标对应股票,纵坐标对应营业收入,彩色部分长度代表均值,黑色部分代表不同时间点波动的幅度(事实上每个股票对应的“柱”是有宽度的,文章原文是泰坦尼克号失事人员的信息表,此处统计的是失事男女的平均年龄。原则上x轴上元素不宜过多)
除了求平均值之外,Bar Plot还可以用于计算每个类别的其他聚合值。为此,需要将聚合函数传递给估计器。例如,你可以计算每个股票营业收入的标准差如下:
sns.barplot(x='instrument', y='fs_operating_revenue', data=df, estimator=np.std)
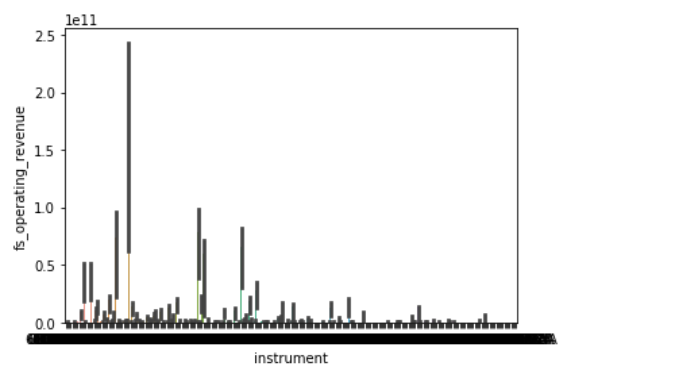 注意:此代码用到了numpy库
注意:此代码用到了numpy库
统计图
统计图与条形图类似,但是它显示特定列中类别的计数。例如,如果我们想要计算每日被写入财报数据的股票信息数量,我们可以使用count plot这样做:
sns.countplot(x='date', data=df)

箱线图
box plot用于以四分位数的形式显示分类数据的分布。框的中心显示了中值。从下须到盒底的值显示第一个四分位数。从盒子的底部到盒子的中部是第二个四分位数。从盒子的中间到顶部是第三个四分位数,最后从盒子的顶部到顶部胡须是最后一个四分位数。
现在我们画一个方框图,显示年龄和性别的分布。您需要将分类列作为第一个参数(在我们的示例中是年份),而数字列(在我们的示例中是净资产收益率)作为第二个参数。最后,将数据集作为第三个参数传递,请看下面的脚本:


为使图像表达出的信息更加直接有用,方便阅读,我先对数据进行了去极值处理。(未去极值的结果在后面附上的代码中可以看到)
boxplot会自动对数据进行标记极值处理。若有数据超出某范围,则会被标记为异常值,在途中以点的形式显示。为被标记的数据则会以箱型的形式显示。“箱子”的五根线分别为数据的0%,25%,50%,75%,100%。
通过添加另一层分布,您可以使您的方框绘图更加美观。例如,如果你想查看不同季度的数据,以及他们净资产收益率的信息,你可以将不同季度的数据传递给hue参数,如下图所示:
sns.boxplot(x='fs_quarter_year', y='fs_roe', data=df_1,hue='fs_quarter_index')

Violin Plot
小提琴图与box图类似,但是小提琴图允许我们显示与数据点实际对应的所有组件。函数的作用是:绘制小提琴的曲线图。与box plot类似,第一个参数是分类列,第二个参数是数值列,第三个参数是数据集。
让我们画一个小提琴图来展示年份和净资产收益率的分布。
sns.violinplot(x='fs_quarter_year', y='fs_roe', data=df_1)

像box plot一样,您还可以使用hue参数向小提琴plot添加另一个类别变量,如下所示:
sns.violinplot(x='fs_quarter_year', y='fs_roe', data=df_1,hue='fs_quarter_index')
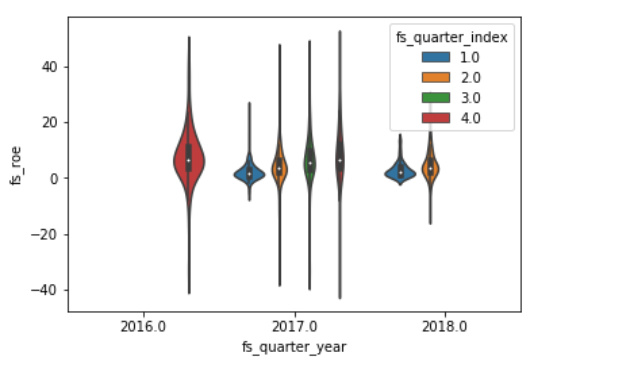
现在你可以在Violin Ploe上看到很多信息。然而,不利的一面是,理解小提琴的情节需要一些时间和精力。
你可以把一个小提琴图分成两半,一半代表幸存的乘客,另一半代表没有幸存的乘客。为此,需要将True作为violinplot()函数的分割参数的值传递。然而,需要注意的是:此时hue必须有且仅有两种情况,否则代码报错。这里给出文章原文的代码:
sns.violinplot(x='sex', y='age', data=dataset, hue='survived', split=True)
(dataset为原文作者使用的DataFrame,sex、age、survived为乘客的信息表)
Violin Plot和Box Plot都非常有用。但是,根据经验,如果您向非技术人员展示数据,那么最好使用Box Plot,因为它们很容易理解。另一方面,如果你把你的研究成果展示给研究团体,那么使用Violin Plot来节省空间和在更短的时间内传达更多的信息,这会使一切变得更方便。
The Strip Plot
条形图绘制一个散点图,其中一个变量是分类变量。我们已经看到了散点图在联合图和成对图中我们有两个数值变量。在这种情况下,条形图的不同之处在于其中一个变量是分类变量,对于分类变量中的每个类别,您将看到与数字列相关的散点图。
函数的作用是:绘制小提琴的曲线图。与box plot类似,第一个参数是分类列,第二个参数是数值列,第三个参数是数据集。请看下面的代码:
sns.stripplot(x='fs_quarter_year', y='fs_roe', data=df_1)

你可以看到各个股票每年的净资产收益率分布。数据点看起来像条。理解这种形式的数据分布有点困难,为了更好地理解数据,我们给抖动参数传递True,它会给数据添加一些随机噪声。请看下面的代码:
sns.stripplot(x='fs_quarter_year', y='fs_roe', data=df_1,jitter=True)
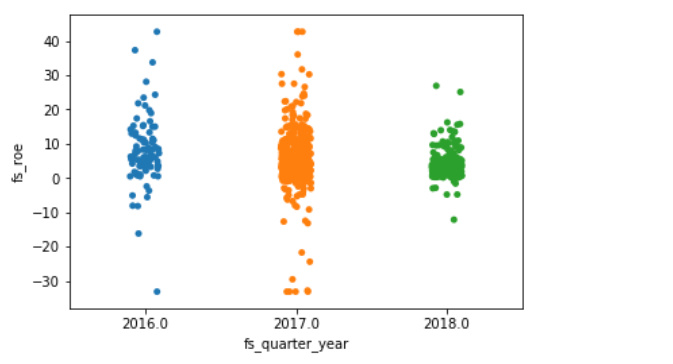 就像小提琴图和盒子图一样,您可以使用色相参数为条形图添加额外的分类列,如下图所示:
就像小提琴图和盒子图一样,您可以使用色相参数为条形图添加额外的分类列,如下图所示:
sns.stripplot(x='fs_quarter_year', y='fs_roe', data=df_1,jitter=True,hue='fs_quarter_index')

同理,“split=True”同样适用,同时也要求hue的列值只有两种情况
The Swarm Plot
Swarm Plot是Strip Plot和 Violin Plots的结合。在Swarm Plot中,这些点以不重叠的方式调整。让我们画一个Swarm Plot来表示年份和净资产收益率的关系。函数的作用是:绘制小提琴的曲线图。与box plot类似,第一个参数是分类列,第二个参数是数值列,第三个参数是数据集。请看下面的代码:
sns.swarmplot(x='fs_quarter_year', y='fs_roe', data=df_1)

可以清楚地看到,上面的图中包含了散在的数据点,比如条形图,数据点没有重叠。相反,他们和Violin Plot很相似。
让我们使用hue参数向群图中添加另一个分类列。
sns.swarmplot(x='fs_quarter_year', y='fs_roe', data=df_1,hue='fs_quarter_index')

同理,“split=True”同样适用,同时也要求hue的列值只有两种情况
Combining Swarm and Violin Plots
如果您有一个庞大的数据集,不推荐使用群体图,因为它们不能很好地伸缩,因为它们必须绘制每个数据点。如果你真的喜欢群体图,一个更好的方法是结合两个图。例如,要将Swarm Plot 与 Violin Plot结合起来,代码如下:
sns.violinplot(x='fs_quarter_year', y='fs_roe', data=df_1) sns.swarmplot(x='fs_quarter_year', y='fs_roe', data=df_1, color='black')

总结
Seaborn是一种基于Matplotlib库的高级数据可视化库。在本文中,我们研究了如何使用Seaborn库绘制分布和分类图。这是关于Seaborn的系列文章的第1部分。在本系列的第二篇文章中,我们将了解如何在Seaborn中处理网格功能,以及如何在Seaborn中绘制矩阵和回归图。
实现源码:《Pandas数据可视化工具——Seaborn用法整理》

本文由BigQuant人工智能量化投资平台原创推出,版权归BigQuant所有,转载请注明出处。














 1168
1168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









