






本地RAG知识库实战
1、什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和 AI 内容生成的混合架构,可以解决大模型的知识时效性限制和幻觉问题。
简单来说,RAG 就像给 AI 配了一个 “小抄本”,让 AI 回答问题前先查一查特定的知识库来获取知识,确保回答是基于真实资料而不是凭空想象。
2、RAG 和传统 AI 模型的区别:
| 特性 | 传统大语言模型 | RAG增强模型 |
|---|---|---|
| 知识时效性 | 受训练数据截止日期限制 | 可接入最新知识库 |
| 领域专业性 | 泛化知识,专业深度有限 | 可接入专业领域知识 |
| 响应准确性 | 可能产生 “幻觉” | 基于检索的事实依据 |
| 可控性 | 依赖原始训练 | 可通过知识库定制输出 |
| 资源消耗 | 较高(需要大模型参数) | 模型可更小,结合外部知识 |
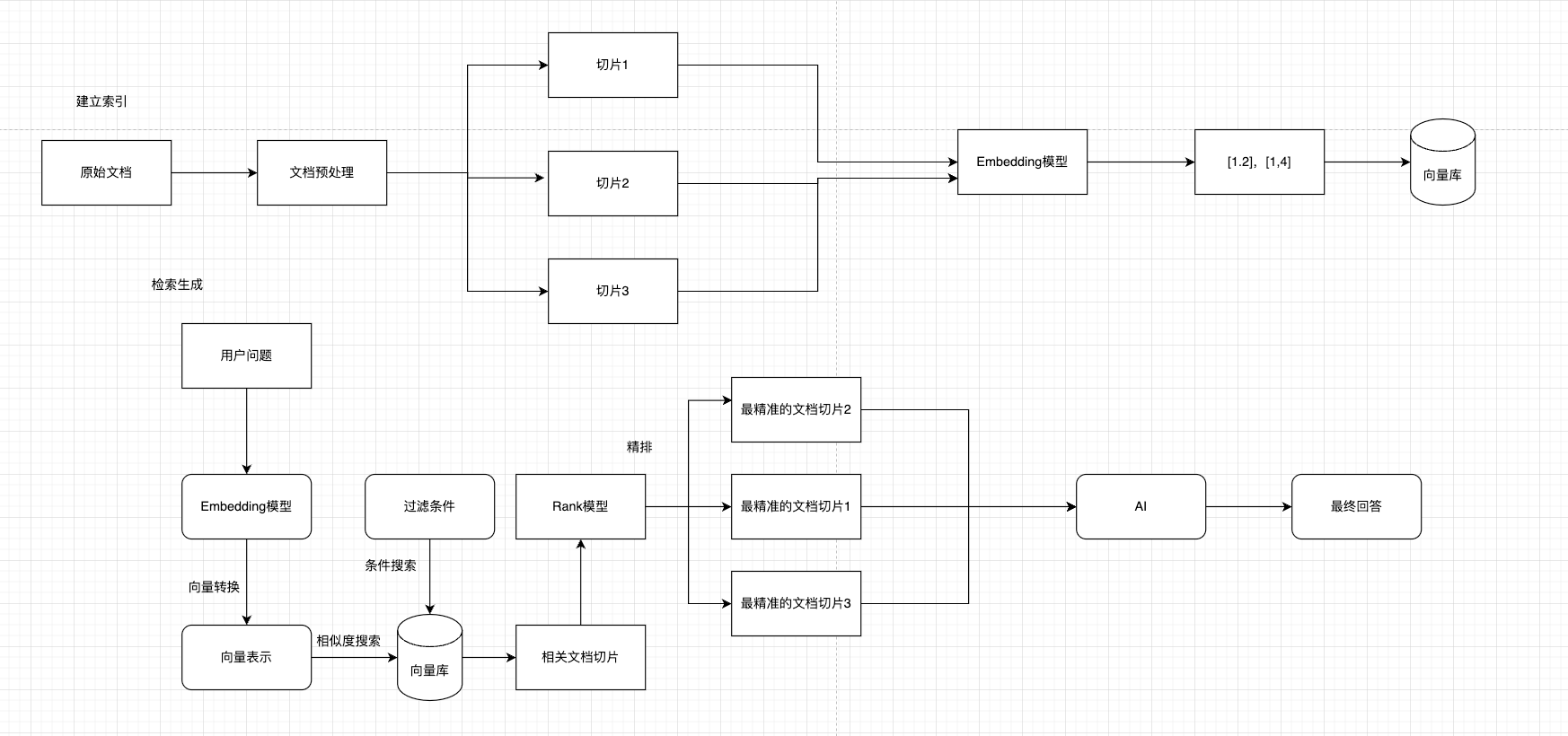
3、RAG 工作流程
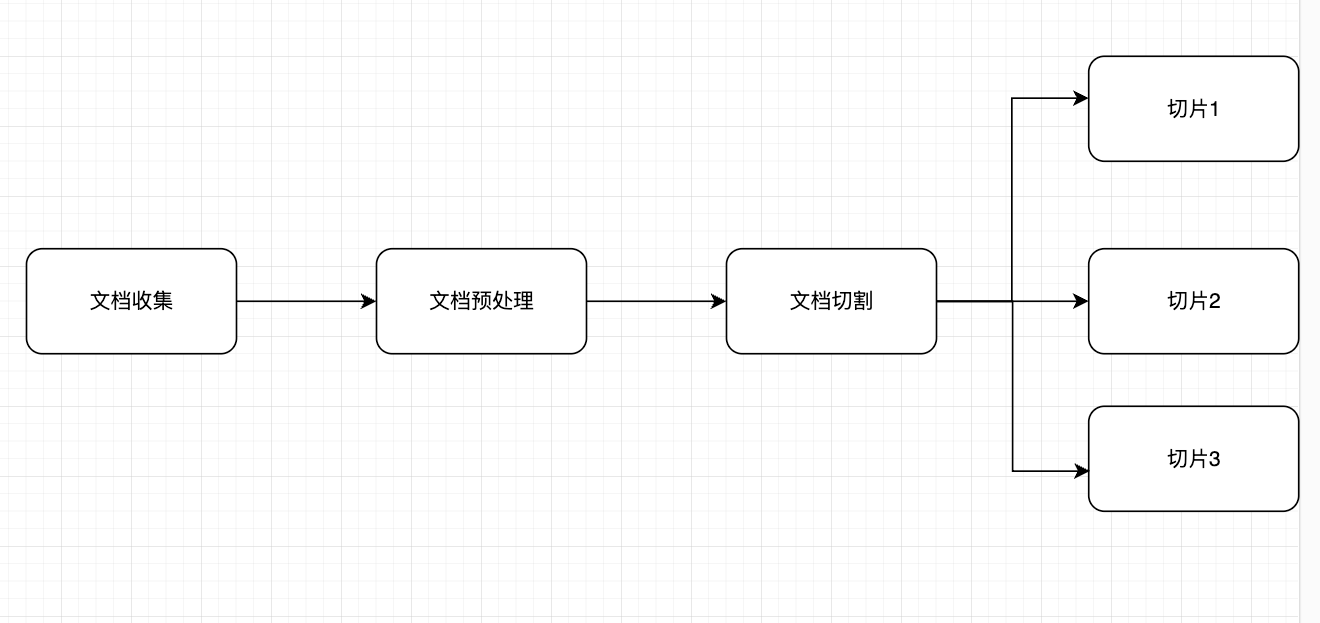
3.1 文档收集和切割
文档收集:从各种来源(网页、PDF、数据库等)收集原始文档
文档预处理:清洗、标准化文本格式
文档切割:将长文档分割成适当大小的片段
- 基于固定大小(如 512 个 token)
- 基于语义边界(如段落、章节)
如下图:
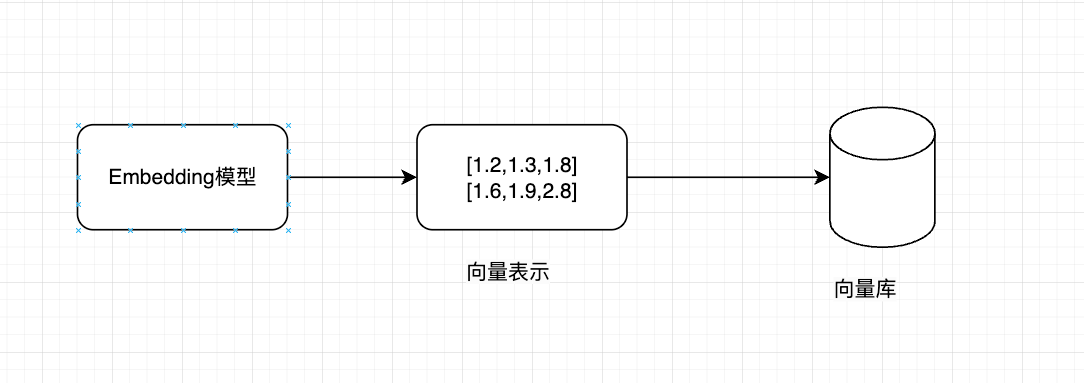
3.2 向量转换和存储
向量转换:使用 Embedding 模型将文本块转换为高维向量表示,可以捕获到文本的语义特征
向量存储:将生成的向量和对应文本存入向量数据库,支持高效的相似性搜索
如下图:
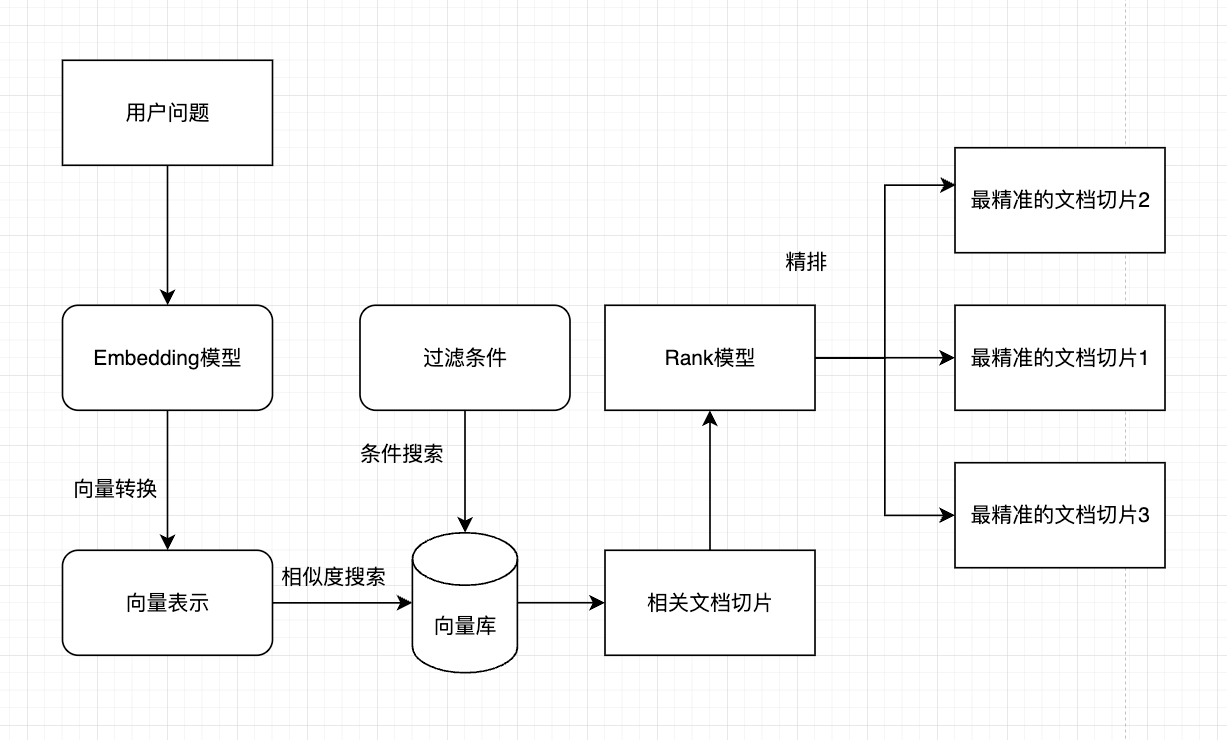
3.3 文档过滤和检索
查询处理:将用户问题也转换为向量表示
过滤机制:基于元数据、关键词或自定义规则进行过滤
相似度搜索:在向量数据库中查找与问题向量最相似的文档块,常用的相似度搜索算法有余弦相似度、欧氏距离等
上下文组装:将检索到的多个文档块组装成连贯上下文
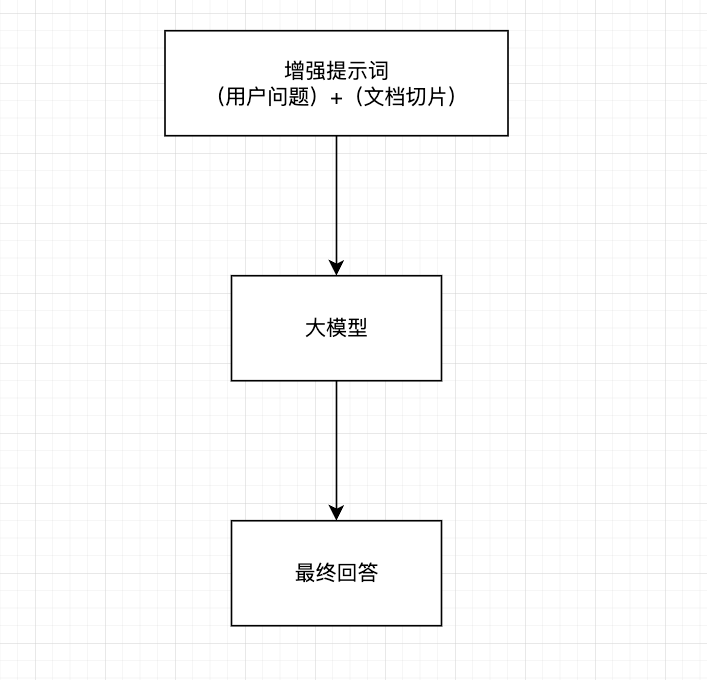
3.4 查询增强和关联
提示词组装:将检索到的相关文档与用户问题组合成增强提示
上下文融合:大模型基于增强提示生成回答
源引用:在回答中添加信息来源引用
后处理:格式化、摘要或其他处理以优化最终输出
完整工作流程
分别理解上述 4 个步骤后,我们可以将它们组合起来,形成完整的 RAG 检索增强生成工作流程:
4、代码实现
可以参考SpringAi官方文档案例进行开发,建议存到向量库尽量不要用PDF格式,感觉效果并不是那么好,当然可以让AI调用调用工具,将PDF转成text文本或者markdown格式在存入。
官网地址:https://docs.spring.io/spring-ai/reference/api/etl-pipeline.html#_markdown
先编写一个接口:
@PostMapping("/insertUserVetor")
@Operation(summary = "上传文件添加到向量库中")
public ResponseEntity<String> insertUserVetor(@RequestParam("file") MultipartFile[] files) {
operatePgVertorManager.loadUserDocumentsToVectorStore(files);
return ResponseEntity.ok("文件上传成功");
}
保存到向量库可以用VectorStore 创建一个bean就OK的
加载用户上传的文件,调用add方法进行添加到向量库
/**
* 加载用户上传的 markdown 文档并存入向量库:mrsun_agent
*/
public void loadUserDocumentsToVectorStore(MultipartFile[] files) {
List<Document> documents = documentLoader.loadUserMarkdowns(files);
List<Document> enrichedDocs = myKeywordEnricher.enrichDocument(documents);
pgVectorVectorStore.add(enrichedDocs);
}
加载文档以及处理文档
/**
* 加载用户上传的文档切分入向量库
* @param files 可以是多个
* @return
*/
public List<Document> loadUserMarkdowns(MultipartFile[] files) {
List<Document> allDocuments = new ArrayList<>();
for (MultipartFile file : files) {
try {
String fileName = file.getOriginalFilename();
if (fileName == null || fileName.length() < 6) {
log.warn("文件名无效或过短,跳过: {}", fileName);
continue;
}
Resource resource = new FileSystemResource(saveToTempFile(file));
String status = fileName.substring(fileName.length() - 6, fileName.length() - 4);
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", fileName)
.withAdditionalMetadata("status", status)
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);
//处理matadata的信息
List<Document> docs = updateMetadata(reader.get(), fileName);
allDocuments.addAll(docs);
} catch (IOException e) {
log.error("Markdown 文件加载失败: {}", file.getOriginalFilename(), e);
}
}
return allDocuments;
}
5、效果
打开调试台。上传一个文件测试效果
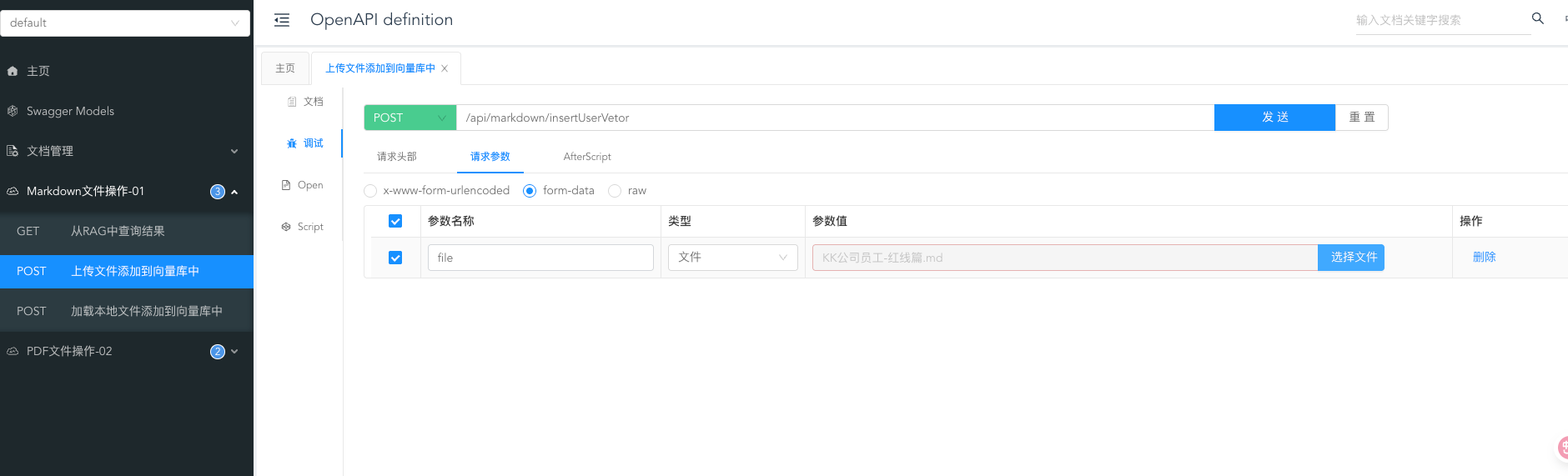
进行切片入向量库。用的是pg数据库。查看结果:

6、查询重写
查询重写可以使查询更加精确和专业,但是要注意保持查询的语义完整性
主要应用包括:
- 使用 RewriteQueryTransformer 优化查询结构
参考 官方文档 实现查询重写:
地址:https://java2ai.com/docs/1.0.0-M6.1/tutorials/rag/#32-query-rewrite-%E6%9F%A5%E8%AF%A2%E9%87%8D%E5%86%99
代码如下:
/**
* 查询重写器
* 查询重写和翻译可以使查询更加精确和专业,但是要注意保持查询的语义完整性
*/
@Component
public class QueryRewriter {
private final QueryTransformer queryTransformer;
/***
* 自动注入:使用阿里云百炼千问plus模型,dashscopeChatModel
* @param dashscopeChatModel
*/
public QueryRewriter(ChatModel dashscopeChatModel) {
ChatClient.Builder builder = ChatClient.builder(dashscopeChatModel);
// 创建查询重写转换器
queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(builder)
.build();
}
/**
* 接收一个原本的查询---->转成新的查询
*
* @param prompt
* @return
*/
public String doQueryRewrite(String prompt) {
Query query = new Query(prompt);
//执行查询重写
Query transformedQuery = queryTransformer.transform(query);
// 输出重写后的查询
return transformedQuery.text();
}
}
7、知识库查询
查询知识库的流程和上面流程图是一样的。用户需要输入问题,Embedding模型会帮我们将问题转换成向量,如:[1.3,1.6,2.1]等等。。。。然后去向量库中进行检索相关的文档,取出最接近的文档进行切片,进行精排,喂给AI(用户问题+文档)最终返回一个精准的文档。
代码如下:
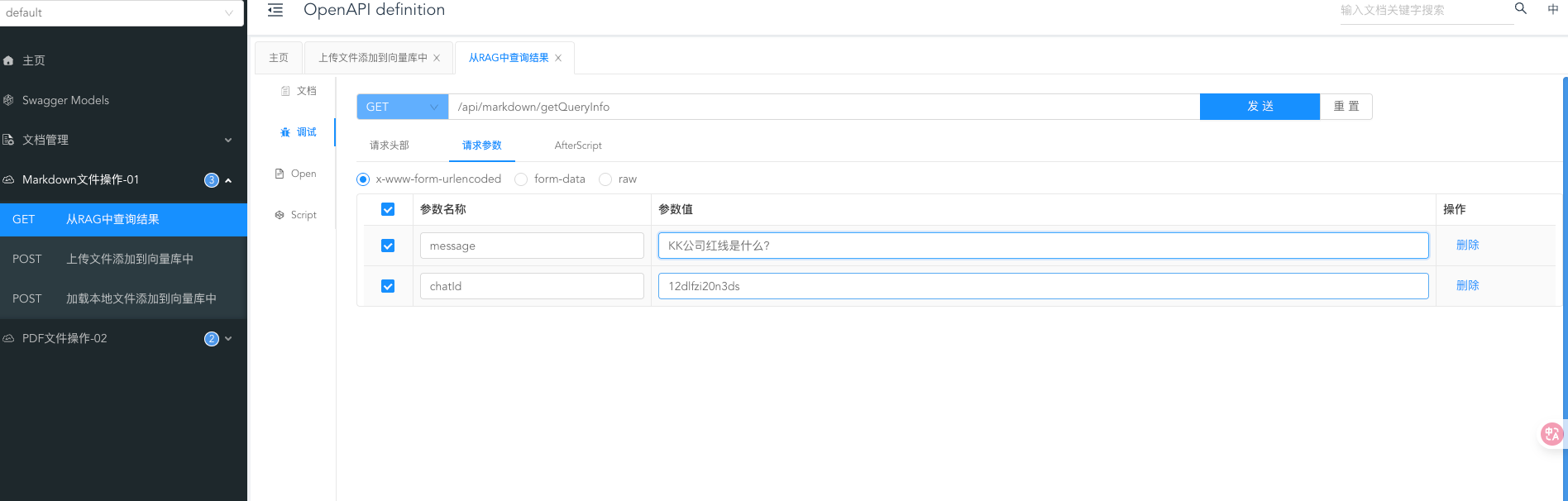
先编写问题的入口,参数分别为消息内容,以及chatId(不可重复)
@GetMapping("/getQueryInfo")
@Operation(summary = "从RAG中查询结果")
public ResponseEntity getQueryInfo(String message, String chatId) {
String resopnse = null;
try {
resopnse = pgVertorManager.queryMarkdownKnowledge(message, chatId);
return ResponseEntity.ok(resopnse);
} catch (Exception e) {
return ResponseEntity.internalServerError().body("查询失败,错误原因为: " + e.getMessage());
}
}
定义一个manager层,进行调用查询等操作:
public String queryMarkdownKnowledge(String message, String chatId) {
return queryFromVectorStore(message, chatId, pgVectorVectorStore, SYSTEM_PROMPT_AI);
}
传递进去的为消息,会话id,从哪个库中查询,以及提示词。由于不想让AI回答的太官方,或者一看就是从知识库中拿到的文档,这里进行设置一个预先的提示词:
private final static String SYSTEM_PROMPT_AI = """
你是一个全公司最厉害的人事小助手,
你需要使用文档内容对用户提出的问题进行回复,同时你需要表现得天生就知道这些内容,
不能在回复中体现出你是根据给出的文档内容进行回复的,这点非常重要。
文档内容如下:
{documents}
""";
编写查询的业务,可以用到用户问题重写,
/**
* 通用 RAG 查询接口
*/
private String queryFromVectorStore(String message, String chatId, VectorStore vectorStore, String systemPromptTemplate) {
SearchRequest request = SearchRequest.builder()
.query(message)
.build();
List<Document> similarDocs = vectorStore.similaritySearch(request);
String documents = similarDocs.stream()
.map(Document::getText)
.collect(Collectors.joining());
Message systemMessage = new SystemPromptTemplate(systemPromptTemplate)
.createMessage(Map.of("documents", documents));
//构建AI查询重写器,可以改写输入的问题
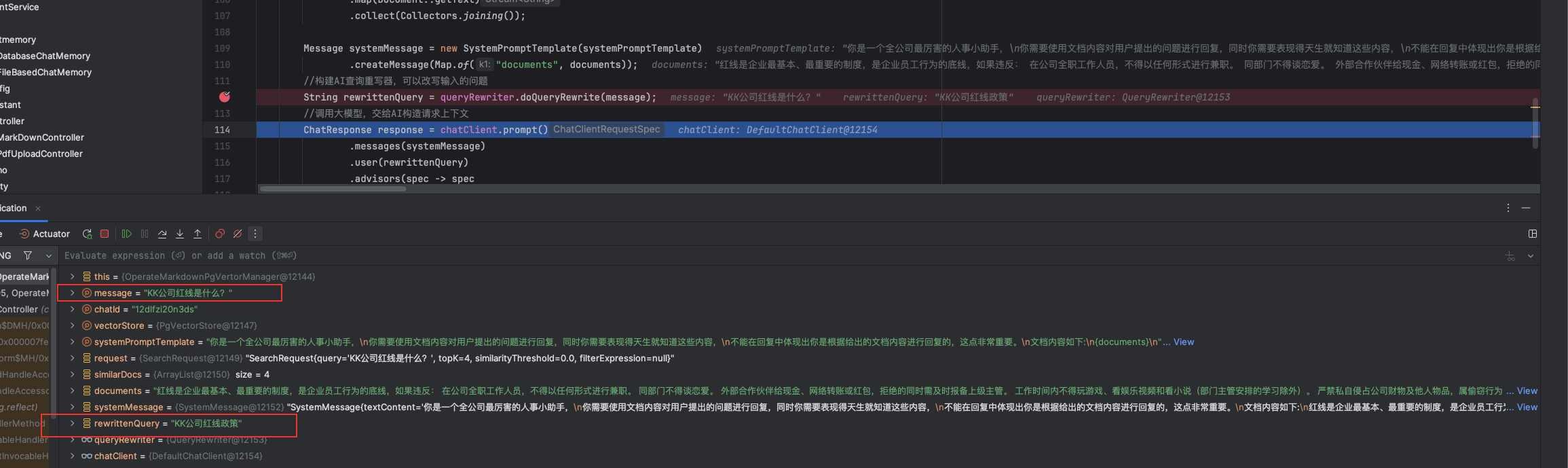
String rewrittenQuery = queryRewriter.doQueryRewrite(message);
//调用大模型,交给AI构造请求上下文
ChatResponse response = chatClient.prompt()
.messages(systemMessage)
.user(rewrittenQuery)
.advisors(spec -> spec
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10))
// .advisors(RagCustomAdvisorFactory.createAppRagCustomAdvisor(vectorStore,"红线"))
.call()
.chatResponse();
return response.getResult().getOutput().getText();
}
测试效果:
可以打个断点到用户重写的方法那,看看AI给我们转成了什么?
最终回答:
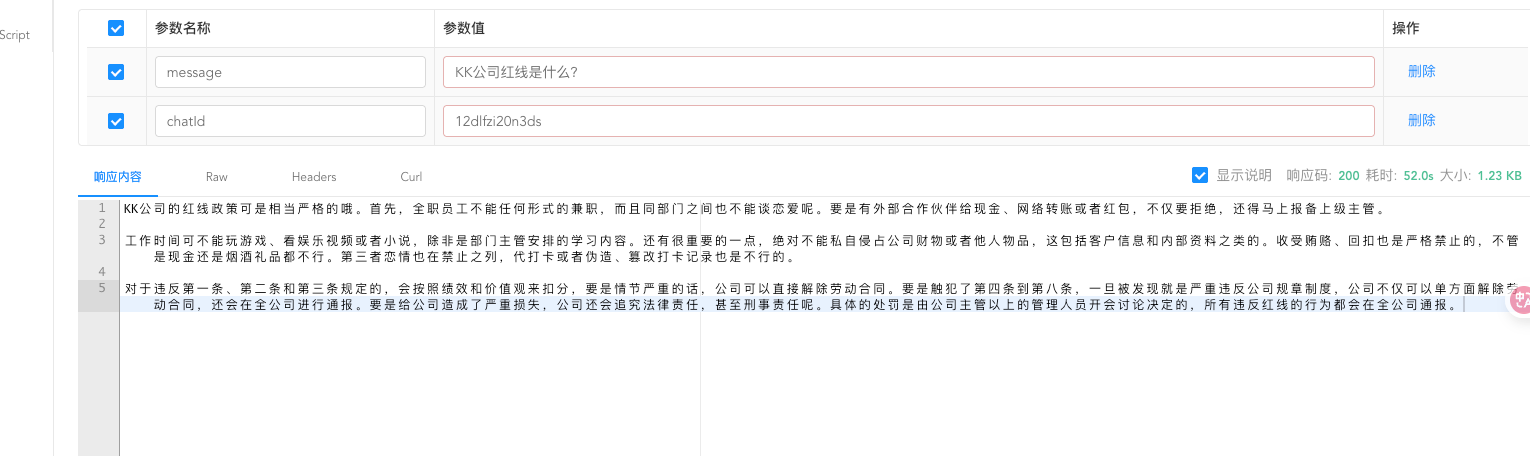
这就是我们公司的红线,如果不加提示词模版。它会回答的很传统,直接把向量库中的内容给我念出来了。
错误处理机制
在实际应用中,可能出现多种异常情况,如找不到相关文档、相似度过低、查询超时等。良好的错误处理机制可以提升用户体验。
异常处理主要包括:
1、允许空上下文查询(即处理边界情况)
2、提供友好的错误提示
3、引导用户提供必要信息
边界情况处理可以使用 Spring AI 的 ContextualQueryAugmenter 上下文查询增强器:
RetrievalAugmentationAdvisor.builder()
.queryAugmenter(
ContextualQueryAugmenter.builder()
.allowEmptyContext(false)
.build()
)
如果不使用自定义处理器,或者未启用 “允许空上下文” 选项,系统在找不到相关文档时会默认改写用户查询 userText:
The user query is outside your knowledge base.
Politely inform the user that you can't answer it.
如果启用 “允许空上下文”,系统会自动处理空 Prompt 情况,不会改写用户输入,而是使用原本的查询。
我们也可以自定义错误处理逻辑,来运用工厂模式创建一个自定义的 ContextualQueryAugmenter:
/**
* 创建上下文工厂增强器----用于异常处理,如果AI没有检索到知识。则让自定义回答
*/
public class ContextualQueryAugmenterFactory {
/**
* 创建自定义提示词
* 注:如果没有下面的代码。或者改成true AI则会给你改写提示词。
* .allowEmptyContext(false) //允许空上下文
* .emptyContextPromptTemplate(emptyContextPromptTemplate) 使用自定义的提示词。检索不到的情况
* The user query is outside your knowledge base.
* Politely inform the user that you can't answer it.
*
* @return
*/
public static ContextualQueryAugmenter createInstance() {
PromptTemplate emptyContextPromptTemplate = new PromptTemplate("""
你应该输出下面的内容:
很抱歉,您的问题超出了当前知识范围,暂时无法为您提供准确答案。
如需更多帮助,请联系南瓜:xxxxxxx@qq.com
""");
return ContextualQueryAugmenter.builder()
.allowEmptyContext(false) //允许空上下文
.emptyContextPromptTemplate(emptyContextPromptTemplate)
.build();
}
}
给检索增强生成 Advisor 应用自定义的 ContextualQueryAugmenter:
public static Advisor createAppRagCustomAdvisor(VectorStore vectorStore, String status) {
/**
* 过滤特定状态文档
*/
Filter.Expression expression = new FilterExpressionBuilder()
.eq("status", status)
.build();
//创建检索器 实现更精准的检索能力
VectorStoreDocumentRetriever documentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(expression) //过滤条件
.similarityThreshold(0.5) //相似度阈值
.topK(3) //返回文档数量
.build();
return RetrievalAugmentationAdvisor.builder()
.documentRetriever(documentRetriever)
//异常处理
.queryAugmenter(ContextualQueryAugmenterFactory.createInstance())
.build();
}
测试
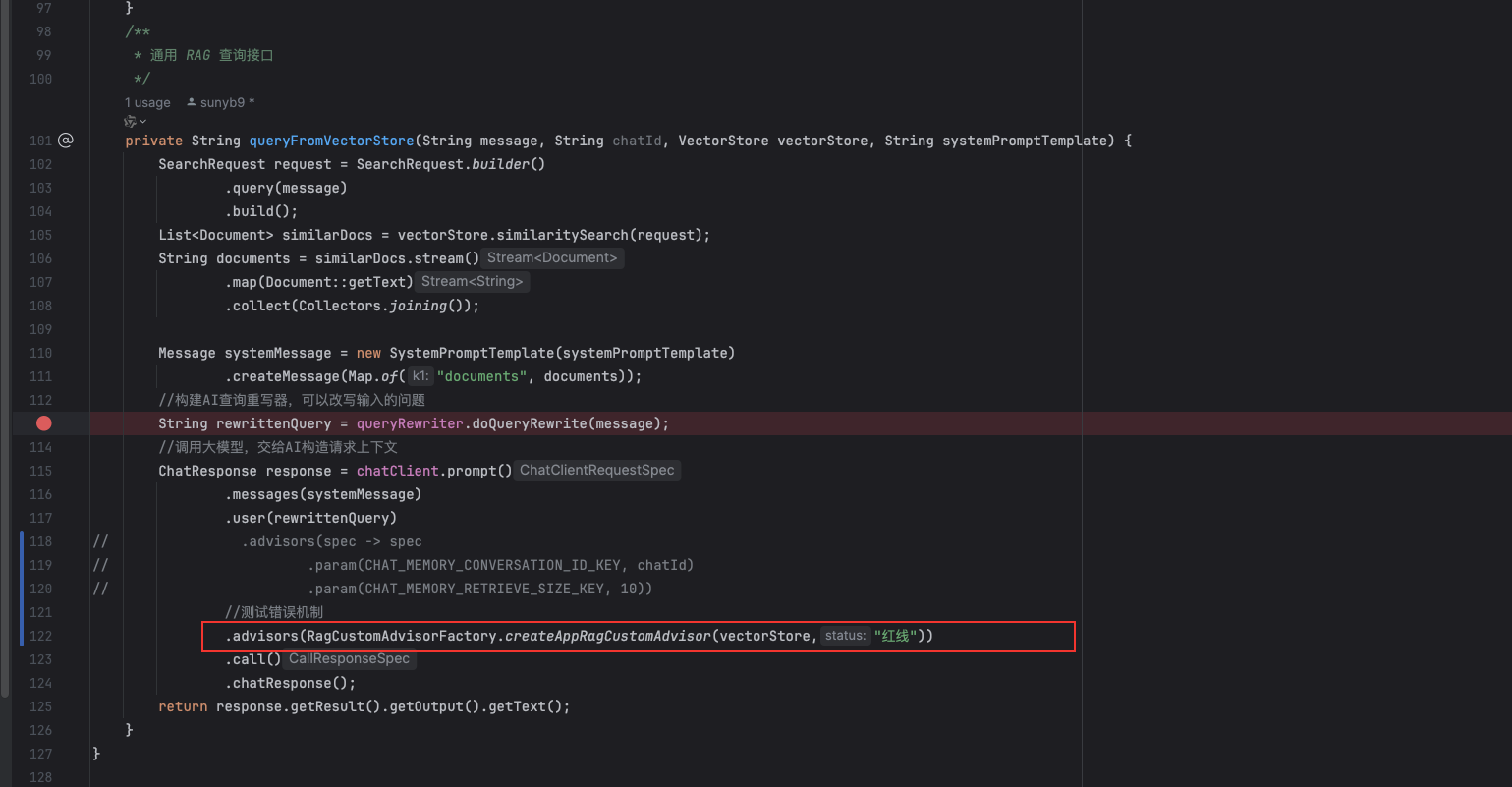
执行效果如下:
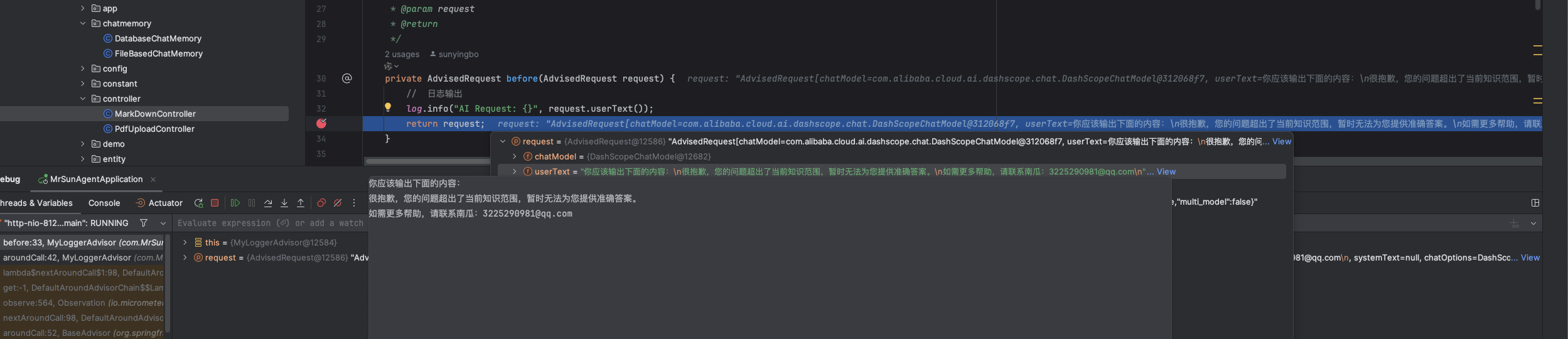
AI返回内容:
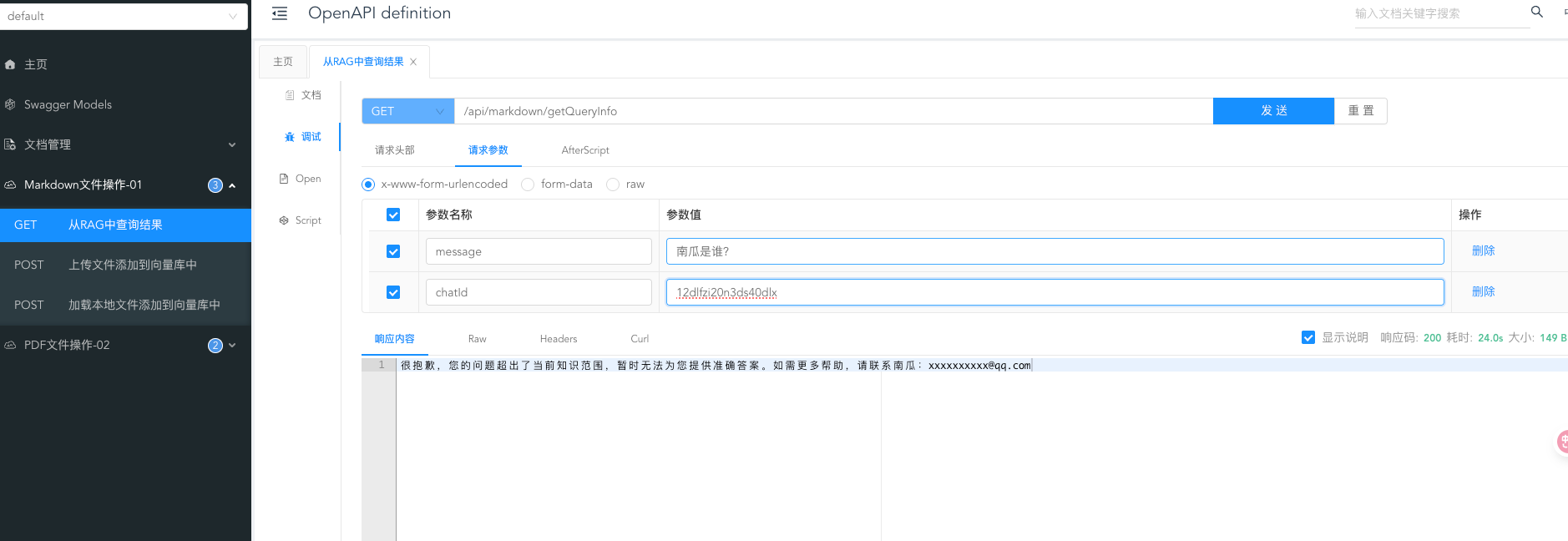
此文章希望对你学习RAG有所帮助,重点是理解RAG工作流程。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











