







声明: 部分图片来自于课程讲义
写在前面
本文仅作为课程的总结,可以作为考试复习的大纲,其中包含一些习题或者是往年的考试题目,作为练习,文中以[例题]样式标明。虽然大多是为了考试,还是加入了一些概念、推导,甚至是讨论、困惑,作为点缀和“警示”。
整理的顺序较乱,但已经尽力而为,大致是按照授课顺序整理的(整个课程的授课顺序就很迷惑,没有主线,可能是因为能讲的太多太杂)。
习题解答参考
声明:个人作业,仅供参考,请勿保存,禁止在其他网站转载!如有错误请务必在评论区指出,或联系sunzhihao_future@163.com,十分感谢!
https://blog.csdn.net/sunzhihao_future/article/details/122315786
模式识别经典算法
线性判别分析
感知器算法(赏罚机制)
贝叶斯决策问题
贝叶斯最小错误率判别
贝叶斯最小错误率判别:利用模式集的统计特性来分类,以使分类器发生错误的概率最小。对于两类模式集的分类,要确定 x x x是属于 ω 1 \omega_1 ω1类还是 ω 2 \omega_2 ω2类,要看 x x x是来自于 ω 1 \omega_1 ω1类的概率大还是来自 ω 2 \omega_2 ω2类的概率大。
[例题]
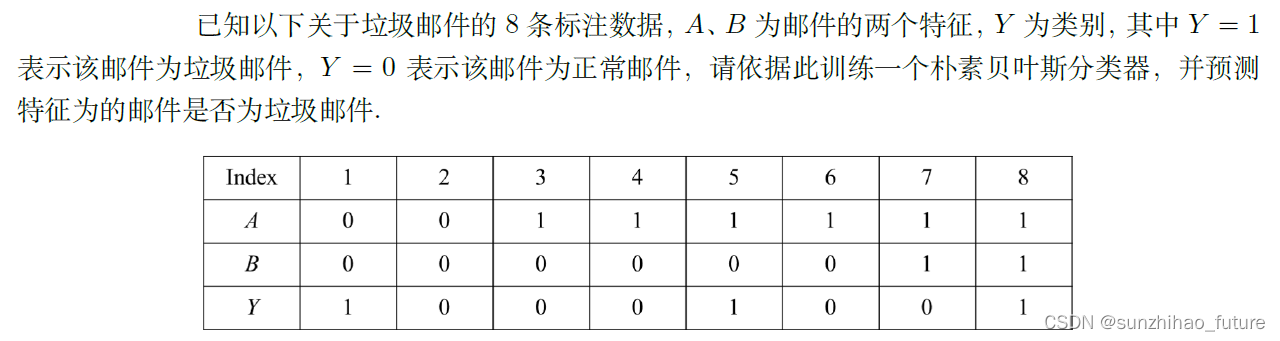
更正:预测特征为 A = 0 , B = 1 A=0, B=1 A=0,B=1的邮件是否为垃圾邮件。
[例题]


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









