







MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是一种特殊数据结构。
索引实际上是将某个被使用频繁的字段抽取出来,建立一种单独的数据组织结构。就像一本字典,我们把他们的首字母抽取出来,组成一个目录,我们查询时直接查询目录,可以大大的减少我们的查询速度。提高查询速度的同时,当我们需要对数据修改时,修改的的速度也会相对应降低,因为我们也要同时性的修改我们的索引。
所以当我们数据量大的时候,我们使用索引来增加我们的查询速度,当数据量少的时候,专门为数据建立索引就不太值得,同时,我们建立索引的时候应该考虑应该设置索引的字段,给频繁被用于查询条件的字段添加索引,不做无用功。
索引的数据结构
数据库索引主要有Hash表、二叉树、红黑树、B树、B+树,我们MySQL使用的是B+树!
Hash索引
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。
既然是基于哈希表实现的,那么它的底层结构也是hash表的结构,即数组加链表。每一条记录的hash值都根据hash散列计算散列到某一个数组下标中的链表上的链表节点中,指针中存储着记录的真实地址。
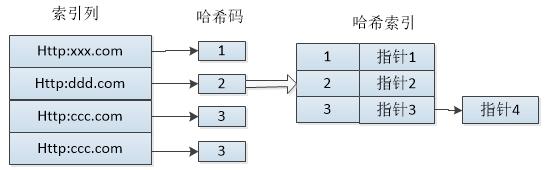
我们有一条`SELECT * FROM user WHERE name=‘石小添’; 这样的一条SQL可以直接对石小添 按哈希算法算出来一个Hash值,通过该值找到对应的记录指针,通过记录指针找到表中的哪一行数据,最后比较name是否为石小添,以保证就是要查找的行。
但是如果我们有 SELECT * FROM user WHERE name>‘石小添’; 这样的一条SQL则无能为力,因为Hash表支持快速的精确查询,但是不支持范围查询。
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序
- 哈希索引不支持部分索引列匹配查找,因为哈希索引始终是使用索引列的全部内容来计算哈希值
- 哈希索引只支持等值比较查询,不支持任何范围查询
- 访问哈希索引的数据非常快,除非有很多哈希冲突(不同的索引列值却有相同的哈希值)。当出现哈希冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行
- 如果哈希冲突很多的话,一些索引维护操作的代价也会很高。例如,如果在某个选择性很低(哈希冲突很多)的列上建立哈希索引,那么当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大
二叉树
二叉树(Binary Tree)是每个结点最多有两个子树的树结构。通常子树被称作"左子树"(left subtree)和"右子树"(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
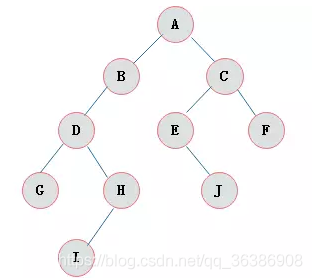
二叉查找树的特点就是左子树的节点值比父亲节点小,而右子树的节点值比父亲节点大。所以这种二叉查找树树是一种不平衡树,它在有时会出现一些极端的存储情况。
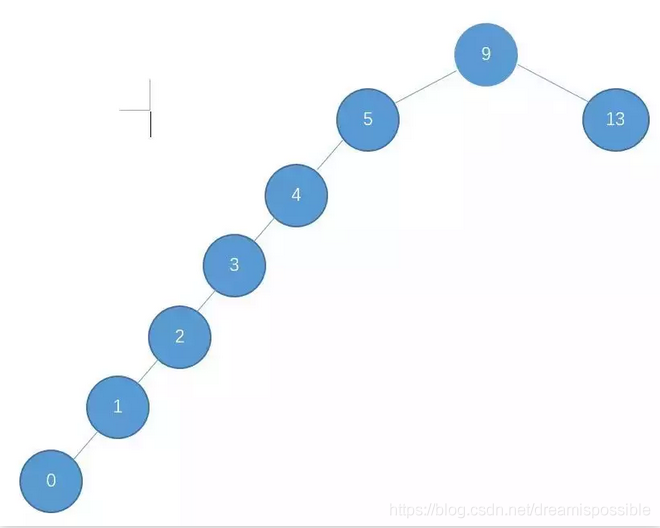
如果建立了如上图的索引并且使用它去进行查找6次,速度和没有创建索引是一样的&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7786
7786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









