







一、需求
关系型数据库仍是大部分公司核心数据的主流存储引擎,它不像有些存储引擎天生支持分布式,可以横向扩容,性能不降低。为了解决关系型数据库横向扩容的问题,目前大部分公司的方案是通过应用架构改进来实现分库分表技术的。
二、方案
主流的分库方案有两种:
第一种方案在应用层实现动态切库(这次实现这种方案)
优点:方案实现起来简单,直连目标数据库,通信效率高,SQL百分百兼容;
缺点:无论是应用层扩容还是分库扩容时,数据库连接池的数量都会成正比增加,应用需要更多的连接维护开销,MySQL单机的连接数量越占越多,维护开销也是越来越大。
适合场景:分库数量不是太多的时候(小厂?)。
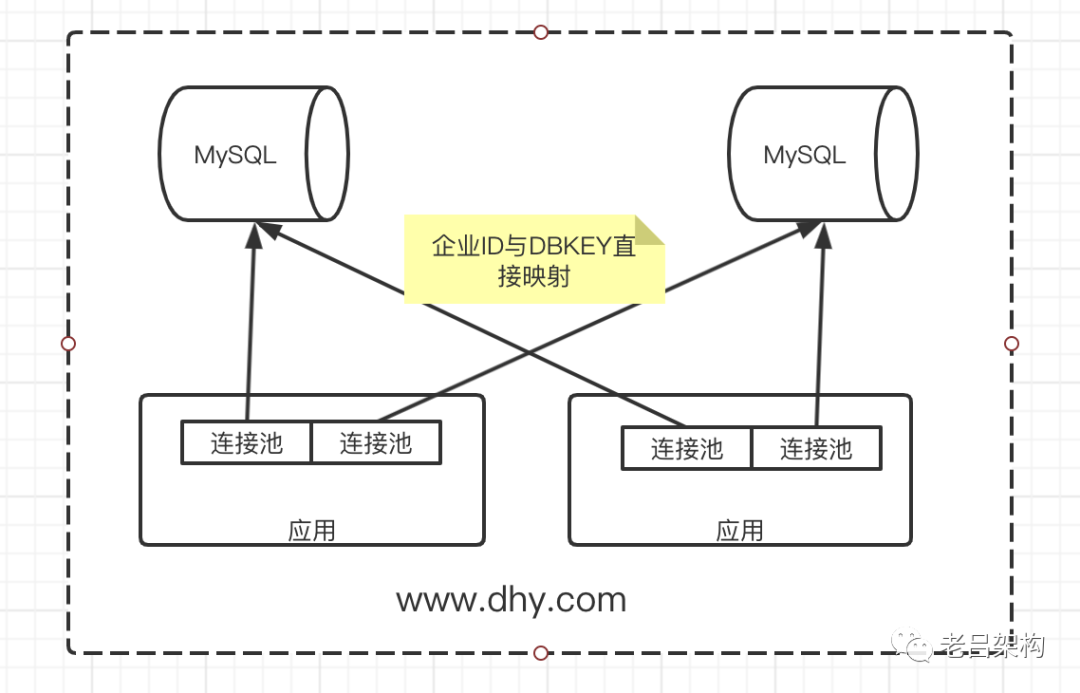
优化方案,通过应用分组来降低每个应用上数据库连接
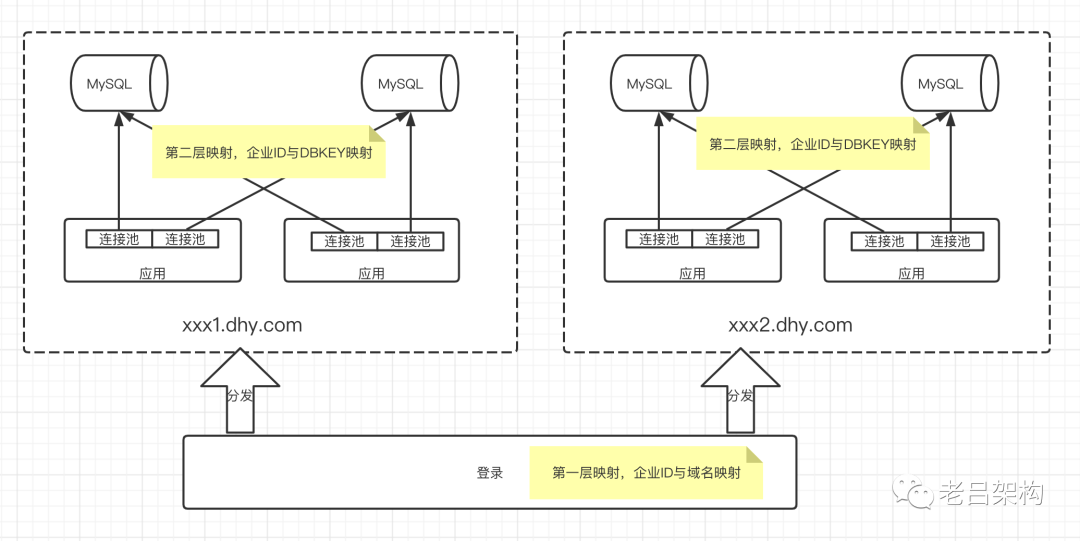
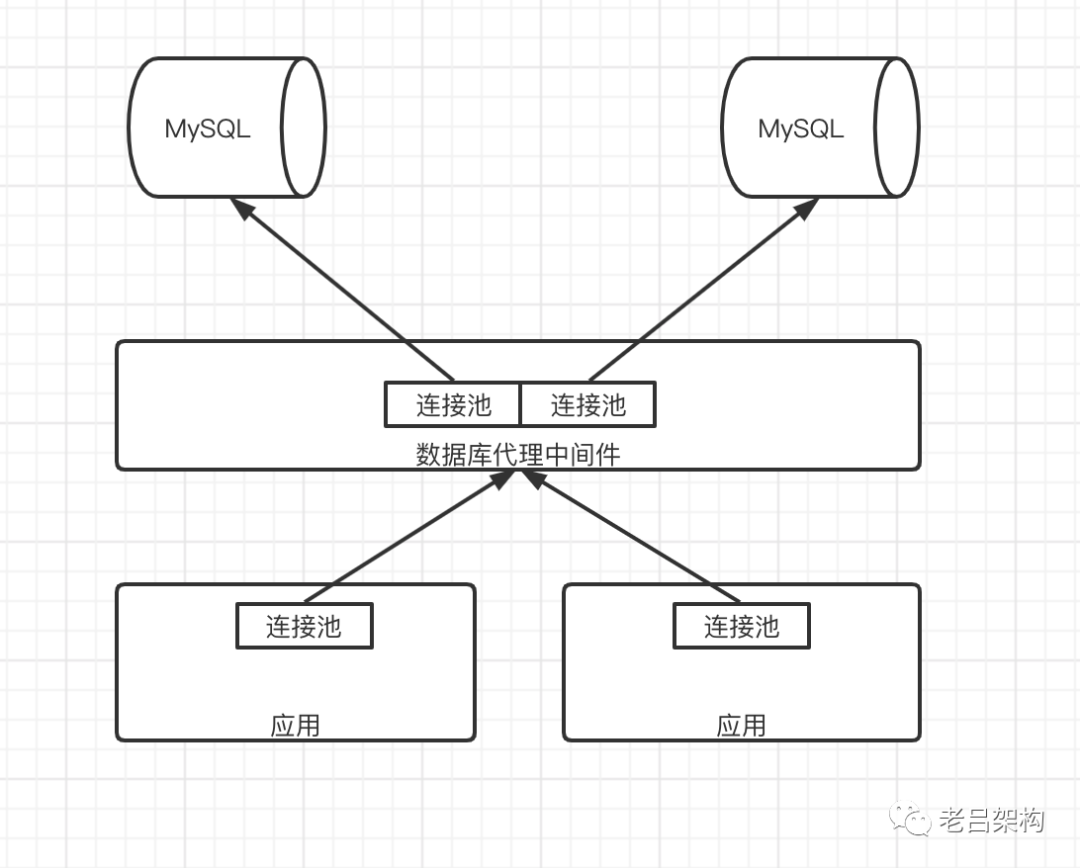
第二种方案是通过数据库连接代理层来实现分库
优点:连接池的数量会少很多,复用的程度会大大增加。聚合查询数据比较容易实现。
缺点:1、代理中间件会成为性能瓶颈,它的高可用,扩容,高性能都需要维护成本 2、sql的执行性能会下降,毕竟中间多了一层代理 3、SQL能否百分百兼容?因为我们知道 代理中间件是需要解析sql来确定路由到哪一个分库上的
适用场景:有大量分库的场景(大厂?)
第三种方案是通过DAS(DataAccessService)服务来实现分库(类似中间件代理,但是不解析SQL,只是为了统一DB访问通道,最大程度复用DB连接。这种方案是我临时想出来的,不清楚有没有公司这么干的)
优点:能在一定程度上解决方案1的缺点,但是又没有第二种方案那么复杂,更像一个折中方案
缺点:多一层网络传输性能损耗

三、实现
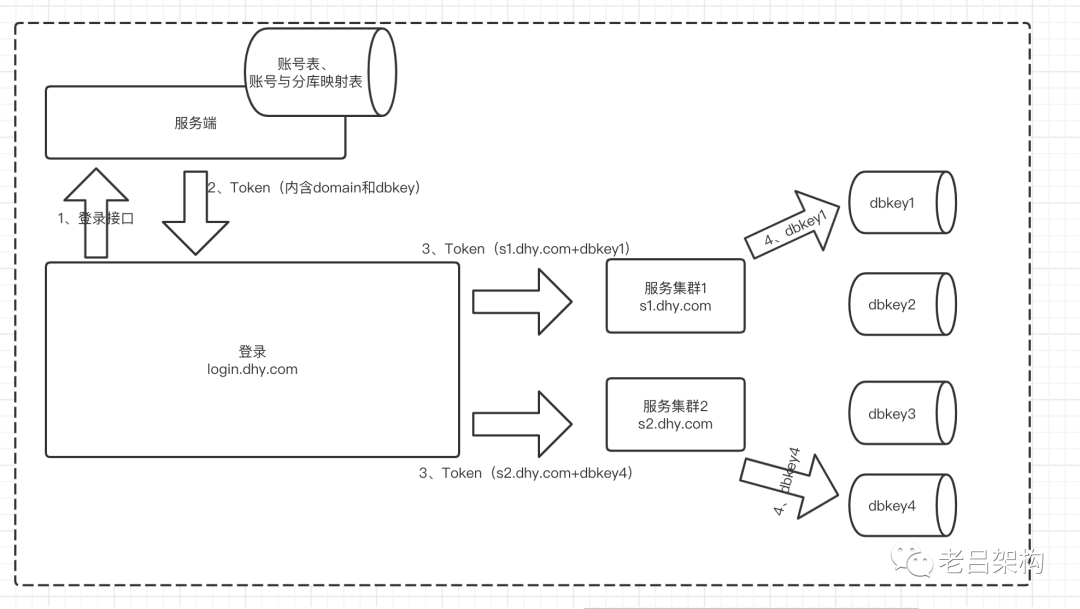
步骤0、总体实现思路图
步骤1、数据源配置表
dbKey,dbIp,dbUser,dbPwd,dbPort,dbName
步骤2、映射表(有了这一层映射,就灵活多了,可以实现很多特殊需求)
orgId,dbKey
步骤3、动态数据源的构建,动态路由接口的实现
系统库连接配置
@Component
@ConfigurationProperties(prefix = "spring.datasource.druid.data-source")
@Data
public class DbConfig {
private String url;
private String username;
private String password;
private String publicKey;
private String connectionProperties;
private String filters;
}路由接口
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
{
return TraceUtil.getShardingDBKey();
}
}
}动态数据源自动构建
@Configuration
public class MybatisConfig {
@Autowired
private DbConfig dbConfig;
@Bean("dataSource")
public DataSource dataSource() {
return getNewDataSourceInstance(dbConfig);
}
private DruidDataSource getNewDataSourceInstance(DbConfig dbConfig){
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setUrl(dbConfig.getUrl());
druidDataSource.setUsername(dbConfig.getUsername());
druidDataSource.setPassword(dbConfig.getPassword());
druidDataSource.setConnectionProperties(dbConfig.getConnectionProperties());
try {
druidDataSource.setFilters(dbConfig.getFilters());
} catch (SQLException throwables) {
throwables.printStackTrace();
}
return druidDataSource;
}
@Bean("dynamicDataSource")
public DataSource dynamicDataSource() {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
Map<Object, Object> dataSourceMap = new HashMap<>();
dataSourceMap.put("dataSource", dataSource());
//分库数据源--
MysqlDbConfig mysqlDbConfig = new MysqlDbConfig();
BeanUtils.copyProperties(dbConfig,mysqlDbConfig);
List<SysDataSourceDto> dataSourceConfigList = DataSourceUtil.getDataSourceConfigList(mysqlDbConfig,null);
for (SysDataSourceDto ds : dataSourceConfigList) {
String dbKey = ds.getDbkey();
String replace=ds.getDbip()+":"+ds.getDbport()+"/"+ds.getDbname();
String fromUrl = this.dbConfig.getUrl();
int beginIndex = fromUrl.indexOf("//");
int endIndex = fromUrl.lastIndexOf("?");
String toUrl = fromUrl.substring(0,beginIndex)+"//"+replace+fromUrl.substring(endIndex);
DbConfig dbConfig = new DbConfig();
BeanUtils.copyProperties(this.dbConfig,dbConfig);
dbConfig.setUrl(toUrl);
DruidDataSource druidDataSource= getNewDataSourceInstance(dbConfig);
dataSourceMap.put(dbKey,druidDataSource);
}
// 将 dataSource 数据源作为默认指定的数据源
dynamicDataSource.setDefaultTargetDataSource(dataSource());
// 将 分库数据源作为目标数据源
dynamicDataSource.setTargetDataSources(dataSourceMap);
return dynamicDataSource;
}
@Bean("lazyDataSource")
public DataSource lazyDataSource() {
LazyConnectionDataSourceProxy proxy = new LazyConnectionDataSourceProxy();
proxy.setTargetDataSource(dynamicDataSource());
return proxy;
}
@Bean
public SqlSessionFactoryBean sqlSessionFactoryBean() throws Exception {
SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
// 配置数据源,此处配置为关键配置,如果没有将 dynamicDataSource作为数据源则不能实现切换
sessionFactory.setDataSource(lazyDataSource());
sessionFactory.setTypeAliasesPackage("com.dhy.boss.dto"); // 扫描Model
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sessionFactory.setMapperLocations(resolver.getResources("classpath*:mapping/*.xml")); // 扫描映射文件
return sessionFactory;
}
@Bean
public PlatformTransactionManager transactionManager() {
// 配置事务管理, 使用事务时在方法头部添加@Transactional注解即可
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(lazyDataSource());
dataSourceTransactionManager.setNestedTransactionAllowed(false);
return dataSourceTransactionManager;
}
}步骤4、分库标识的传递(传递过程要靠 Spring Token拦截器、Dubbo过滤器、ThreadLocal工具类相互协作完成)
public class TraceUtil {
private static final InheritableThreadLocal<String> contextHolder_shardingDBKey = new InheritableThreadLocal<>();
/**
* 设置业务分库的dbkey
*/
public static void setShardingDBKey(String dbKey) {
contextHolder_shardingDBKey.set(dbKey);
}
/**
* 获取业务分库的dbkey
*/
public static String getShardingDBKey() {
String dbKey = contextHolder_shardingDBKey.get();
if (dbKey == null||dbKey.length() == 0) {
throw new Exception("dbkey为空");
}
return dbKey;
}
}四、总结
1、没有最好的设计,只有适合当前业务特点的、当前业务规模的合理超前的设计,目前我的项目是SaaS型to B的业务,分库规模在50个左右,目前的设计还是能吼住的,扩容还是比较从容的
2、第三种方案更适合新项目,从头开始的项目。抽时间实现下。
3、感觉方案1的优化方案已经能满足大大部分to B 业务公司的需求了

















 1500
1500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











