







Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程
对比 Flink SQL 的执行流程:https://blog.csdn.net/super_wj0820/article/details/95623380
1. Spark SQL运行架构

由上图看出,Spark SQL 的解析流程为:
1. 使用 SessionCatalog 保存元数据
在解析SQL语句之前,会创建 SparkSession,或者如果是2.0之前的版本初始化 SQLContext
SparkSession 只是封装了 SparkContext 和 SQLContext 的创建而已,会把元数据保存在SessionCatalog中,涉及到表名,字段名称和字段类型
创建临时表或者视图,其实就会往SessionCatalog注册
2. 解析SQL使用 ANTLR 生成未绑定的逻辑计划
当调用 SparkSession 的SQL或者 SQLContext 的SQL方法,我们以2.0为准,就会使用 SparkSqlParser 进行解析SQL
使用的 ANTLR 进行词法解析和语法解析,它分为2个步骤来生成Unresolved LogicalPlan:
- 词法分析:Lexical Analysis, 负责将token分组成符号类
- 语法分析:构建一个分析树或者语法树AST
3. 使用分析器Analyzer绑定逻辑计划
在该阶段,Analyzer 会使用 Analyzer Rules,并结合 SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划
4. 使用优化器Optimizer优化逻辑计划
优化器也是会定义一套 Rules,利用这些Rule对逻辑计划和 Exepression 进行迭代处理,从而使得树的节点进行合并和优化。
5. 使用SparkPlanner生成物理计划
SparkSpanner 使用 Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划 SparkPlan
6. 使用 QueryExecution 执行物理计划
此时调用 SparkPlan 的 execute 方法,底层其实已经再触发JOB了,然后返回RDD
2. catalyst整体执行流程介绍
2.1 catalyst整体执行流程
Catalyst是spark sql的核心,是一套针对 spark sql 语句执行过程中的查询优化框架
上述 spark sql 的执行流程,其实就是 Catalyst的工作流程
2.2 一个简单sql语句的执行
为了更好的对整个过程进行理解,下面通过一个简单的sql示例来查看采用catalyst框架执行sql的过程。示例代码如下:
object TestSql {
case class Student(id:Long,name:String,chinese:String,math:String,English:String,age:Int)
case class Score(sid:Long,weight1:String,weight2:String,weight3:String)
def main(args: Array[String]): Unit = {
//使用saprkSession初始化spark运行环境
val spark=SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate()
//引入spark sql的隐式转换
import sqlContext.implicits._
//读取第一个文件的数据并转换成DataFrame
val testP1 = spark.sparkContext.textFile("/home/dev/testP1").map(_.split(" ")).map(p=>Student(p(0).toLong,p(1),p(2),p(3),p(4),p(5).trim.toInt)).toDF()
//注册成表
testP1.registerTempTable("studentTable")
//读取第二个文件的数据并转换成DataFrame
val testp2 = spark.sparkContext.textFile("/home/dev/testP2").map(_.split(" ")).map(p=>Score(p(0).toLong,p(1),p(2),p(3))).toDF()
//注册成表
testp2.registerTempTable("scoreTable")
//查看sql的逻辑执行计划
val dataframe = spark.sql("select sum(chineseScore) from " +
"(select x.id,x.chinese+20+30 as chineseScore,x.math from studentTable x inner join scoreTable y on x.id=y.sid)z" +
" where z.chineseScore <100").map(p=>(p.getLong(0))).collect.foreach(println)
此例也是针对spark2.1.1版本的,程序的入口是SparkSession
这里涉及到的sql查询就是最后一句,通过spark shell可以看到该sql查询的逻辑执行计划和物理执行计划。进入sparkshell后,输入一下代码即可显示此sql查询的执行计划
spark.sql("select sum(chineseScore) from " +
"(select x.id,x.chinese+20+30 as chineseScore,x.math from studentTable x inner join scoreTable y on x.id=y.sid)z" +
" where z.chineseScore <100").explain(true)
这里,是使用DataSet的explain函数实现逻辑执行计划和物理执行计划的打印,调用explain的源码如下:
/**
* Prints the plans (logical and physical) to the console for debugging purposes.
*
* @group basic
* @since 1.6.0
*/
def explain(extended: Boolean): Unit = {
val explain = ExplainCommand(queryExecution.logical, extended = extended)
sparkSession.sessionState.executePlan(explain).executedPlan.executeCollect().foreach {
// scalastyle:off println
r => println(r.getString(0))
// scalastyle:on println
}
}
显示在 spark shell 中的 unresolved logical plan、resolved logical plan、optimized logical plan 和 physical plan 如下图2所示:

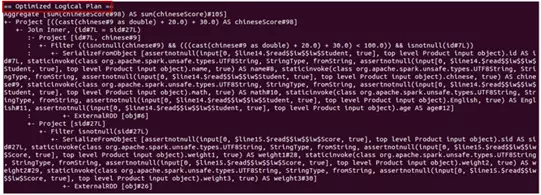

图2 spark sql 执行计划
将上图2中的 Parsed Logical Plan 表示成树结构如图3所示
Catalyst 中的 parser 将图左中一个sql查询的字符串解析成图右的一个AST语法树,该语法树就称为Parsed Logical Plan
解析后的逻辑计划基本形成了执行计划的基础骨架,此逻辑执行计划被称为 unresolved Logical Plan,也就是说该逻辑计划是无法执行的,系统并不知道语法树中的每个词是神马意思,如图中的filter,join,以及studentTable等

图3 Parsed Logical Plan树
将上图2中的Analyzed logical plan,即Resolved logical plan表示成树结构如下图4所示
Catalyst 的 analyzer 将 unresolved Logical Plan 解析成 resolved Logical Plan
Analyzer 借助 cataLog(下文介绍)中表的结构信息、函数信息等将此逻辑计划解析成可被识别的逻辑执行计划

图4 Analyzed logical plan树
optimized logical plan 与 physical plan 的树结构跟上面两种逻辑执行计划树结构的画法相似,下面就不在画了
从optimized logical plan可出,此次优化使用了Filter下推的策略,即将 Filter下推到子查询中实现,继而减少后续数据的处理量。
前面展示了 catalyst 执行一段sql语句的大致流程,下面我们就从源代码的角度来分析catalyst的每个部分内部如何实现,以及它们之间是如何承接的
3. catalyst各个模块介绍
通过分析上面的例子代码的调用过程来分析 catalys 各个部分的主要代码模块,spark sql 的入口是最后一句,SparkSession 类里的sql函数,传入一个sql字符串,返回一个 dataframe 对象
入口调用的代码如下:
code 1
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
3.1 Parser
从入口代码可看出,首先调用 sqlParser 的 parsePlan 方法,将sql字符串解析成 unresolved 逻辑执行计划
parsePlan 的具体实现在 AbstractSqlParser 类中:
code 2
/** Creates LogicalPlan for a given SQL string. */
override def parsePlan(sqlText: String): LogicalPlan = parse(sqlText) { parser =>
astBuilder.visitSingleStatement(parser.singleStatement()) match {
case plan: LogicalPlan => plan
case _ =>
val position = Origin(None, None)
throw new ParseException(Option(sqlText), "Unsupported SQL statement", position, position)
}
}
由上段代码可看出,调用的主函数是parse,继续进入到parse中,代码如下:
code 3
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logInfo(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new ANTLRNoCaseStringStream(command))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
try {
try {
// first, try parsing with potentially faster SLL(Strong-LL) mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
}
}
从parse函数可以看出,这里对于SQL语句的解析采用的是 ANTLR 4,这里使用到了两个类:词法解析器 SqlBaseLexer 和语法解析器 SqlBaseParser
SqlBaseLexer 和 SqlBaseParser 均是使用 ANTLR 4 自动生成的Java类。这里,采用这两个解析器将SQL语句解析成了 ANTLR 4 的语法树结构 ParseTree。之后,在 parsePlan(见code 2)中,使用 AstBuilder(AstBuilder.scala)将ANTLR 4语法树结构转换成catalyst表达式,即 logical plan
此时生成的逻辑执行计划成为 unresolved logical plan,只是将sql串解析成类似语法树结构的执行计划,系统并不知道每个词所表示的意思,离真正能够执行还差很远
3.2 Analyzer
parser 生成逻辑执行计划后,使用 analyzer 将逻辑执行计划进行分析。我们回到 Dataset 的 ofRows 函数:
code 4
def ofRows(sparkSession: SparkSession, logicalPlan: LogicalPlan): DataFrame = {
val qe = sparkSession.sessionState.executePlan(logicalPlan)
qe.assertAnalyzed()
new Dataset[Row](sparkSession, qe, RowEncoder(qe.analyzed.schema))
}
这里首先创建了 queryExecution 类对象,QueryExecution 中定义了sql执行过程中的关键步骤,是sql执行的关键类,返回一个 dataframe 类型的对象
QueryExecution 类中的成员都是 lazy 的,被调用时才会执行。只有等到程序中出现action算子时,才会调用 queryExecution 类中的 executedPlan 成员,原先生成的逻辑执行计划才会被优化器优化,并转换成物理执行计划真正的被系统调用执行
QueryExecution 类的主要成员如下所示,其中定义了解析器analyzer、优化器 optimizer 以及生成物理执行计划的 sparkPlan
code 5
//调用analyzer解析器
lazy val analyzed: LogicalPlan = {
SparkSession.setActiveSession(sparkSession)
sparkSession.sessionState.analyzer.execute(logical)
}
lazy val withCachedData: LogicalPlan = {
assertAnalyzed()
assertSupported()
sparkSession.sharedState.cacheManager.useCachedData(analyzed)
}
//调用optimizer优化器
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
//将优化后的逻辑执行计划转换成物理执行计划
lazy val sparkPlan: SparkPlan = {
SparkSession.setActiveSession(sparkSession)
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now,
// but we will implement to choose the best plan.
planner.plan(ReturnAnswer(optimizedPlan)).next()
}
// executedPlan should not be used to initialize any SparkPlan. It should be
// only used for execution.
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
/**
* Prepares a planned [[SparkPlan]] for execution by inserting shuffle operations and internal
* row format conversions as needed.
*/
protected def prepareForExecution(plan: SparkPlan): SparkPlan = {
preparations.foldLeft(plan) { case (sp, rule) => rule.apply(sp) }
}
前文有介绍,analyzer 的主要职责是将 parser 生成的 unresolved logical plan 解析生成 logical plan
调用 analyzer 的代码在 QueryExecution 中,code 5中已经有贴出
此模块的主函数来自于analyzer的父类 RuleExecutor,主函数 execute 实现在RuleExecutor 类中,代码如下:
code 6
/**
* Executes the batches of rules defined by the subclass. The batches are executed serially
* using the defined execution strategy. Within each batch, rules are also executed serially.
*/
def execute(plan: TreeType): TreeType = {
var curPlan = plan
batches.foreach { batch =>
val batchStartPlan = curPlan
var iteration = 1
var lastPlan = curPlan
var continue = true
// Run until fix point (or the max number of iterations as specified in the strategy.
while (continue) {
curPlan = batch.rules.foldLeft(curPlan) {
case (plan, rule) =>
val startTime = System.nanoTime()
val result = rule(plan)
val runTime = System.nanoTime() - startTime
RuleExecutor.timeMap.addAndGet(rule.ruleName, runTime)
if (!result.fastEquals(plan)) {
logTrace(
s"""
|=== Applying Rule ${rule.ruleName} ===
|${sideBySide(plan.treeString, result.treeString).mkString("\n")}
""".stripMargin)
}
result
}
iteration += 1
}
此函数实现了针对 analyzer 类中定义的每一个batch(类别),按照 batch 中定义的 fix point(策略)和 rule(规则)对Unresolved的逻辑计划进行解析。其中batch 的结构如下:
code 7
/** A batch of rules. */
protected case class Batch(name: String, strategy: Strategy, rules: Rule[TreeType]*)
由于在analyzer的batchs中定义了多个规则,代码段很长,因此这里就不再贴出,有需要的请去spark的源码中找到Analyzer类查看
在 batchs 里的这些batch中,Resolution是最常用的,从字面意思就可以看出其用途,就是将 parser 解析后的逻辑计划里的各个节点,转变成 resolved 节点。而其中 ResolveRelations 是比较好理解的一个rule(规则),这一步调用了catalog 这个对象,Catalog对象里面维护了一个 tableName,Logical Plan 的HashMap 结果。通过这个 Catalog 目录来寻找当前表的结构,从而从中解析出这个表的字段,如 UnResolvedRelations 会得到一个 tableWithQualifiers。(即表和字段)
catalog中缓存表名称和逻辑执行计划关系的代码如下:
code 8
/**
* A cache of qualified table names to table relation plans.
*/
val tableRelationCache: Cache[QualifiedTableName, LogicalPlan] = {
val cacheSize = conf.tableRelationCacheSize
CacheBuilder.newBuilder().maximumSize(cacheSize).build[QualifiedTableName, LogicalPlan]()
}
3.3 Optimizer
optimizer 是 catalyst 中关键的一个部分,提供对sql查询的一个优化
optimizer 的主要职责是针对 Analyzer 的 resolved logical plan,根据不同的batch优化策略),来对执行计划树进行优化,优化逻辑计划节点(Logical Plan) 以及表达式 (Expression),同时,此部分也是转换成物理执行计划的前置
optimizer的调用在 QueryExecution 类中,代码 code 5中已经贴出
其工作方式与上面讲的 Analyzer 类似,因为它们的主函数 executor 都是继承自 RuleExecutor。因此,optimizer 的主函数如上面的 code 6代码,这里就不在贴出。optimizer 的 batchs(优化策略)定义如下:
code 9
def batches: Seq[Batch] = {
// Technically some of the rules in Finish Analysis are not optimizer rules and belong more
// in the analyzer, because they are needed for correctness (e.g. ComputeCurrentTime).
// However, because we also use the analyzer to canonicalized queries (for view definition),
// we do not eliminate subqueries or compute current time in the analyzer.
Batch("Finish Analysis", Once,
EliminateSubqueryAliases,
EliminateView,
ReplaceExpressions,
ComputeCurrentTime,
GetCurrentDatabase(sessionCatalog),
RewriteDistinctAggregates,
ReplaceDeduplicateWithAggregate) ::
//
// Optimizer rules start here
//
// - Do the first call of CombineUnions before starting the major Optimizer rules,
// since it can reduce the number of iteration and the other rules could add/move
// extra operators between two adjacent Union operators.
// - Call CombineUnions again in Batch("Operator Optimizations"),
// since the other rules might make two separate Unions operators adjacent.
Batch("Union", Once,
CombineUnions) ::
Batch("Pullup Correlated Expressions", Once,
PullupCorrelatedPredicates) ::
Batch("Subquery", Once,
OptimizeSubqueries) ::
Batch("Replace Operators", fixedPoint,
ReplaceIntersectWithSemiJoin,
ReplaceExceptWithAntiJoin,
ReplaceDistinctWithAggregate) ::
Batch("Aggregate", fixedPoint,
RemoveLiteralFromGroupExpressions,
RemoveRepetitionFromGroupExpressions) ::
Batch("Operator Optimizations", fixedPoint,
// Operator push down
PushProjectionThroughUnion,
ReorderJoin,
EliminateOuterJoin,
PushPredicateThroughJoin,
PushDownPredicate,
LimitPushDown(conf),
ColumnPruning,
InferFiltersFromConstraints,
// Operator combine
CollapseRepartition,
CollapseProject,
CollapseWindow,
CombineFilters,
CombineLimits,
CombineUnions,
// Constant folding and strength reduction
NullPropagation(conf),
FoldablePropagation,
OptimizeIn(conf),
ConstantFolding,
ReorderAssociativeOperator,
LikeSimplification,
BooleanSimplification,
SimplifyConditionals,
RemoveDispensableExpressions,
SimplifyBinaryComparison,
PruneFilters,
EliminateSorts,
SimplifyCasts,
SimplifyCaseConversionExpressions,
RewriteCorrelatedScalarSubquery,
EliminateSerialization,
RemoveRedundantAliases,
RemoveRedundantProject,
SimplifyCreateStructOps,
SimplifyCreateArrayOps,
SimplifyCreateMapOps) ::
Batch("Check Cartesian Products", Once,
CheckCartesianProducts(conf)) ::
Batch("Join Reorder", Once,
CostBasedJoinReorder(conf)) ::
Batch("Decimal Optimizations", fixedPoint,
DecimalAggregates(conf)) ::
Batch("Typed Filter Optimization", fixedPoint,
CombineTypedFilters) ::
Batch("LocalRelation", fixedPoint,
ConvertToLocalRelation,
PropagateEmptyRelation) ::
Batch("OptimizeCodegen", Once,
OptimizeCodegen(conf)) ::
Batch("RewriteSubquery", Once,
RewritePredicateSubquery,
CollapseProject) :: Nil
}
由此可以看出,Spark 2.1.1版本增加了更多的优化策略,因此如果要提高 spark sql 程序的性能,升级spark版本是非常必要的。
其中,“Operator Optimizations”,即操作优化是使用最多的,也是比较好理解的优化操作,“Operator Optimizations” 中包括的规则有PushProjectionThroughUnion,ReorderJoin 等。
PushProjectionThroughUnion 策略是将左边子查询的 Filter 或者是 projections 移动到 union 的右边子查询中。例如针对下面代码:
case class a:item1:String,item2:String,item3:String
case class b:item1:String,item2:String
select a.item1,b.item2 from a where a.item1>'example' from a union all (select item1,item2 from b )
此时,通过PushProjectionThroughUnion规则后,查询优化器会将sql改为下面的sql,即将Filter右移到了union的右端。如下所示:
select a.item1,b.item2 from a where a.item1>’example’ union all (select item1,item2 from b where item1>’example’)
RorderJoin,顾名思义,就是对多个 join 操作进行重新排序。具体操作就是将一系列的带有 join 的子执行计划进行排序,尽可能地将带有条件过滤的子执行计划下推到执行树的最底层,这样能尽可能地减少join的数据量
例如下面代码中是三个表做 join操作,而过滤条件是针对表a的,但熟悉sql的人就会发现对a中字段 item1的过滤可以挪到子查询中,这样可以减少join的时候数据量,如果满足此过滤条件的记录比较少,则可以大大地提高join的性能
case class b:item1:String,item2:String
select a.item1,d.item2 from a where a.item1> ‘example’ join (select b.item1,b.item2 from b join c on b.item1=c.item1) d on a.item1= d.item1
3.4 SparkPlann
optimizer将逻辑执行计划优化后,接着该SparkPlan登场了,SparkPlann将optimized logical plan转换成physical plans。执行代码如下:
code 10
lazy val sparkPlan: SparkPlan = {
SparkSession.setActiveSession(sparkSession)
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now,
// but we will implement to choose the best plan.
planner.plan(ReturnAnswer(optimizedPlan)).next()
}
其中,planner 为 SparkPlanner 类的对象,对象的创建如下code 11所示
该对象中定义了一系列的执行策略,包括 LeftSemiJoin 、HashJoin 等等,这些策略用来指定实际查询时所做的操作
SparkPlanner 中定义的策略如下code 12所示:
code 11
def strategies: Seq[Strategy] =
extraStrategies ++ (
FileSourceStrategy ::
DataSourceStrategy ::
SpecialLimits ::
Aggregation ::
JoinSelection ::
InMemoryScans ::
BasicOperators :: Nil)
code 12
/**
* Planner that converts optimized logical plans to physical plans.
*/
def planner: SparkPlanner =
new SparkPlanner(sparkContext, conf, experimentalMethods.extraStrategies)
plan 真正的处理函数如下的code 13所示。该函数的功能是整合所有的 Strategy,_(plan)每个Strategy应用plan上,得到所有 Strategies 执行完后生成的所有Physical Plan的集合
code 13
def plan(plan: LogicalPlan): Iterator[PhysicalPlan] = {
// Obviously a lot to do here still...
// Collect physical plan candidates.
val candidates = strategies.iterator.flatMap(_(plan))
// The candidates may contain placeholders marked as [[planLater]],
// so try to replace them by their child plans.
val plans = candidates.flatMap { candidate =>
val placeholders = collectPlaceholders(candidate)
if (placeholders.isEmpty) {
// Take the candidate as is because it does not contain placeholders.
Iterator(candidate)
} else {
// Plan the logical plan marked as [[planLater]] and replace the placeholders.
placeholders.iterator.foldLeft(Iterator(candidate)) {
case (candidatesWithPlaceholders, (placeholder, logicalPlan)) =>
// Plan the logical plan for the placeholder.
val childPlans = this.plan(logicalPlan)
candidatesWithPlaceholders.flatMap { candidateWithPlaceholders =>
childPlans.map { childPlan =>
// Replace the placeholder by the child plan
candidateWithPlaceholders.transformUp {
case p if p == placeholder => childPlan
}
}
}
}
}
4. SQK任务执行 uml 时序图
此处以一个更为简单的 demo 展示业务、构建时序图
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/people.json")
// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
上面这段代码主要做了这么几件事:
- 读取 json 文件得到 df
- 基于 df 创建临时视图 people
- 执行 sql 查询 SELECT * FROM people,得到 sqlDF
- show() 出结果
在这里,主要关注第 3、4 步
第3步是从 sql 语句转化为 DataFrame 的过程,该过程尚未执行 action 操作,并没有执行计算任务
第4步是一个 action 操作,会触发计算任务的调度、执行
4.1 sql 语句到 sqlDataFrame

根据该时序图,我们对该过程进一步细分:
第1~3步:将 sql 语句解析为 unresolved logical plan,可以大致认为是解析 sql 为抽象语法树
第4~13步:使用之前得到的 unresolved logical plan 来构造 QueryExecution 对象 qe,qe 与 Row 编码器一起来构造 DataFrame(QueryExecution 是一个关键类,之后的 logical plan 的 analyzer、optimize 以及将 logical plan 转换为 physical plan 都要通过这个类的对象 qe 来调用)
需要注意的是,到这里为止,虽然 SparkSession#sql 已经返回,并生成了 sqlDataFrame,但由于该 sqlDataFrame 并没有执行任何 action 操作,所以到这里为止,除了在 driver 端执行了上述分析的操作外,其实并没有触发或执行其他的计算任务。
这个过程最重要的产物 unresolved logical plan 被存放在 sqlDataFrame.queryExecution 中,即 sqlDataFrame.queryExecution.logical
4.2 sqlDataFrame 的 action

同样可以将上面这个过程进行细分(忽略第1、2步):
第3~5步:从更外层慢慢往更直接的执行层的一步步调用
第6步:Analyzer 借助于数据元数据(Catalog)将 unresolved logical plan 转化为 resolved logical plan
第7~8步:Optimizer 将包含的各种优化规则作用于 resolved plan 进行优化
第9~10步:SparkPlanner 将 optimized logical plan 转换为 physical plan
第11~12步:调用 QueryExecution#prepareForExecution 方法,将 physical plan 转化为 executable physical plan,主要是插入 shuffle 操作和 internal row 的格式转换
第13~14步:将 executable physical plan 转化为 RDD,并调用 RDD collect 来触发计算
参考:
- https://www.jianshu.com/p/d045a14930cb
- https://www.jianshu.com/p/0aa4b1caac2e















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









