










selectOne和selectList
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
//创建SqlSession
SqlSession session = sqlSessionFactory.openSession();
try {
Person person = (Person) session.selectOne("org.erik.PersonMapper.selectBlog", 2);
System.out.println(person.getName());
} finally {
session.close();
}前面五句是读取配置文件,然后构建SqlSessionFactory和sqlSession,具体怎么解析配置文件,再构建SqlSessionFactory现在暂时不看,我们现在主要看看怎么拿到sql语句,然后去数据库执行。
重点在
Person person = (Person) session.selectOne("org.erik.PersonMapper.selectBlog", 2);sqlSession的selectOne实现:
org.apache.ibatis.session.defaults.DefaultSqlSession
selectOne方法:
public <T> T selectOne(String statement, Object parameter) {
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.<T>selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}这边selectOne方法就是selectList后,再拿第一个。正常逻辑。
selectList方法:
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
return result;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}rowBounds:查询列表时的limit限制。包括offset(偏移量)和limit(大小)。
MappedStatement ms = configuration.getMappedStatement(statement);statement为要执行的sql的“定义ID”,这里为字符串 org.erik.PersonMapper.selectBlog
<mapper namespace="org.erik.PersonMapper">
<select id="selectBlog" parameterType="int" resultType="mybatis.Person">
select * from person where id = #{id}
</select>
</mapper>configuration中有所有的sql的配置信息,就是根据上面这个statement作为key存储的。
拿到MappedStatement 后相当于拿到了要执行sql的各种环境信息。
至于怎么解析配置文件,再储存到configuration中的我们以后再详谈。
List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);executor是哪儿来的?
我能说是在openSession的时候创建的。然后以后再看吗?
好吧,我错了。上代码
org.apache.ibatis.session.defaults.DefaultSqlSessionFactory#openSessionFromDataSource
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}就是在openSession的时候创建的。根据tx(事务管理器),和执行器类型创建的。这里面就不深究下去了。因为太深。还是以后有功夫再看吧。
回到selectList。
看executor.query的参数。
第一个是ms,上面讲到的sql语句的一些环境配置信息。
第二个是参数,sql要执行的参数。这里做了一个wrapCollection。实际上就是list和array塞到map中,好方面之后获取。
private Object wrapCollection(final Object object) {
if (object instanceof List) {
StrictMap<Object> map = new StrictMap<Object>();
map.put("list", object);
return map;
} else if (object != null && object.getClass().isArray()) {
StrictMap<Object> map = new StrictMap<Object>();
map.put("array", object);
return map;
}
return object;
}第三个是rowBounds上面也讲到了。
最后一个是resultHandler就是结果处理器,sql执行完后,怎么印射到相应对象中。
靠。就讲了一个方法要一章节啊。烦不烦啊!
附这节的UML图:
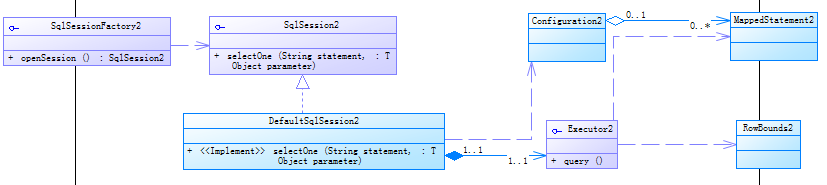
别问我为什么带个2.















 1552
1552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









