







需求:增量按照时间段统计每个人知识库文章的文章数量、创建人、操作时间、修改人、文章内容、文章链接。并将每个人的统计结果导出到excel。
实现步骤:
1、首先找到最适合的网页,即:能爬取出需求所需要的数据 的 最合适的网页
最合适的页面为右上方的搜索,如下示例图:

点击搜索如下:
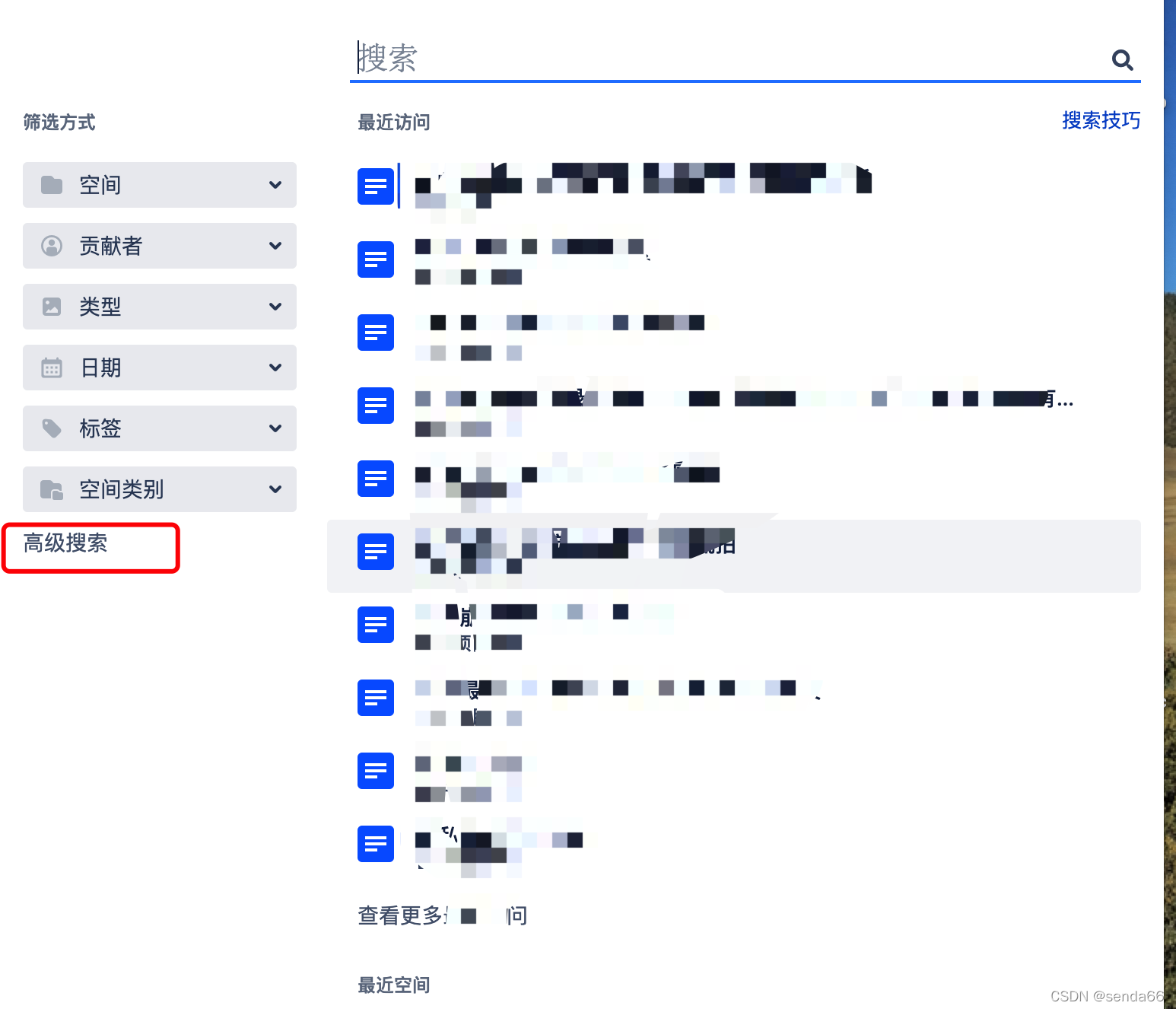
点击高级搜索出现如下:下图中可根据很多提供的条件进行获取文章、文章摘要等,还有日期时间段条件。所以就选定如下页面进行数据爬取。

2、由于网站做了反爬手段,所以需要首先模拟登录,登录账号使用个人账号即可,模拟登录库使用requests session 库。代码示例如下:
base_url = 'http://192.168.10.18:8080'
login_action_url = "http://192.168.10.18:8080/dologin.action"
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36",
"Referer": "http://192.168.10.18:8080/login.action?language=zh_CN"
}
login_data = {
"os_username": "真实用户名",
"os_password": "真实密码",
"login": "登录",
"os_destination": ""
}
import requests
session = requests.session()
# 发起登录请求
response_post = session.post(url=login_action_url, data=login_data, headers=headers)
content_post = response_post.text
# with open('conloginSucess.html', 'w', encoding='utf-8')as fp:
# fp.write(content_post)
print(session.cookies)
print("登录成功")
3、登录成功后再次请求网页时则使用session 进行请求,因为requests.session 每次请求后都会携带cookie,从而保证登录状态,请求刚刚需要的网页地址,并获取页面源码
经过分析可知:要爬取的页面为分页数据,故地址为:
http://192.168.10.18:8080/dosearchsite.action?cql=type+%3D+%22page%22&startIndex=50
其中startIndex参数为第6页的标识别。第一页的网址为 http://192.168.10.18:8080/dosearchsite.action?cql=type+%3D+%22page%22
其他第n页的网址为:
http://192.168.10.18:8080/dosearchsite.action?cql=type+%3D+%22page%22&startIndex=n*10-10
所以根据这个规律可循坏获取所有页面网页源码并进行解析。这里就不详细写代码了。
article_list = []
for i in 100:
article_dict = {}
if i==1:
url = http://192.168.10.18:8080/dosearchsite.action?cql=type+%3D+%22page%22
else:
url = http://192.168.10.18:8080/dosearchsite.action?cql=type+%3D+%22page%22&startIndex=i*10-10
current_res = session.get(url=current_href).text
# 解析 current_res,组成想要的数据 放到list 中即可 使用xpath 库
from lxml import etree
tree = etree.HTML(current_res)
# xpath 解析,解析出文章列表,循环文章列表 获取数据组成一个文章实体,放到article_list中。
4、解析成功后将需要的数据保存到list列表中,并导出到excel
def exporToExcel(article_list):
from openpyxl import load_workbook
from openpyxl import Workbook
workbook = Workbook()
wb = workbook.create_sheet(index=0)
wb.cell(row=1, column=1, value='按人员统计')
wb.cell(row=1, column=2, value='文章名称')
wb.cell(row=1, column=3, value='文章链接')
wb.cell(row=1, column=4, value='创建人')
wb.cell(row=1, column=5, value='修改人')
wb.cell(row=1, column=6, value='处理时间')
count = 2
for article in article_list:
# 将数据写入到下一行
wb.cell(row=count, column=1, value=article["tj_user"])
wb.cell(row=count, column=2, value=article["a_title"])
wb.cell(row=count, column=3, value=article["a_href"])
wb.cell(row=count, column=4, value=article["a_c_person"])
wb.cell(row=count, column=5, value=article["a_m_person"])
wb.cell(row=count, column=6, value=article["a_date"])
count += 1
workbook.save(filename='article_list.xlsx')
总结
爬虫爬取最重要的是找到合适的页面进行数据分析。其他都不难。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











