









系列文章目录
前言
暂不考虑支持多线程
常用STL的简单实现,主要内容百行左右, 避免冗余代码
● 智能指针模板
SharedPtr

#include <assert.h>
#include <atomic>
template <class T>
class SharedPtr
{
public:
typedef T element_type;
explicit SharedPtr(T* ptr = nullptr) : m_ref(nullptr)
{
if (ptr) m_ref = new reftype(ptr);
}
template <class Deleter>
explicit SharedPtr(T* ptr, Deleter d) : m_ref(nullptr)
{
if (ptr) m_ref = new reftye_with_deleter<Deleter>(ptr, d);
}
SharedPtr(const SharedPtr& tocopy)
{
Acquire(tocopy.m_ref);
}
~SharedPtr()
{
Release();
}
SharedPtr& operator=(const SharedPtr& tocopy)
{
if (this != &tocopy)
{
Release();
Acquire(tocopy.m_ref);
}
return *this;
}
SharedPtr& operator=(T* ptr)
{
if (get() != ptr)
{
Release();
if (ptr) m_ref = new reftype(ptr);
}
return *this;
}
T* get() const
{
return m_ref ? m_ref->m_ptr : nullptr;
}
void reset(T* ptr = nullptr)
{
Release();
if (ptr) m_ref = new reftype(ptr);
}
template <class Deleter>
void reset(T* ptr, Deleter d)
{
Release();
if (ptr) m_ref = new reftye_with_deleter<Deleter>(ptr, d);
}
bool unique() const { return m_ref ? m_ref->m_count == 1 : true; }
long use_count() const { return m_ref ? m_ref->m_count.load() : 0; }
// test for pointer validity: defining conversion to unspecified_bool_type
// and not more obvious bool to avoid implicit conversions to integer types
typedef T*(SharedPtr<T>::*unspecified_bool_type)() const;
operator unspecified_bool_type() const
{
if (m_ref && m_ref->m_ptr) return &SharedPtr<T>::get;
else nullptr;
}
T& operator*() const
{
assert(m_ref && m_ref->m_ptr);
return *( m_ref->m_ptr);
}
T* operator->() const
{
assert(m_ref && m_ref->m_ptr);
return m_ref->m_ptr;
}
private:
struct reftype
{
reftype(T* ptr) : m_ptr(ptr), m_count(1) {}
virtual ~reftype() {}
virtual void delete_ptr() { delete m_ptr; }
T* m_ptr;
std::atomic_int m_count;
};
template <class Deleter>
struct reftye_with_deleter: public reftype
{
reftye_with_deleter(T* ptr, Deleter d) : reftype(ptr), m_deleter(d) {}
virtual void delete_ptr() override
{
m_deleter(this->m_ptr);
}
Deleter m_deleter;
};
reftype* m_ref;
void Acquire(reftype* ref)
{
m_ref = ref;
if (ref) ref->m_count.fetch_add(1);
}
void Release()
{
if (m_ref)
{
if (! --m_ref->m_count )
{
m_ref->delete_ptr();
delete m_ref;
}
m_ref = nullptr;
}
}
};
template <class T, class U>
bool operator==(const SharedPtr<T>& a, const SharedPtr<U>& b)
{
return a.get() == b.get();
}
template <class T, class U>
bool operator!=(const SharedPtr<T>& a, const SharedPtr<U>& b)
{
return a.get() != b.get();
}
//------------------------------------------------------------------------------
#include <iostream>
#include <stdio.h>
class TestSt
{
public:
char buf[1024];
char bux[4096];
public:
TestSt()
{
printf(" const %p\n", this);
};
~TestSt()
{
printf("~TestSt: %p\n", this);
}
};
int main()
{
std::atomic_int at;
SharedPtr<TestSt> p_st(new TestSt());
SharedPtr<TestSt> p_st2(p_st);
SharedPtr<TestSt> p_st3(new TestSt());
p_st3 = p_st2;
std::cout << p_st.use_count() << " " << p_st2.use_count() << " "
<< p_st3.use_count() << " " << std::endl;
}
● Vector
auto p = new T[N]; 申请空间,为每个元素p[i]调用T的构造函数
delete[] p; 先为每个元素调用析构函数,释放空间
1. 简单版本
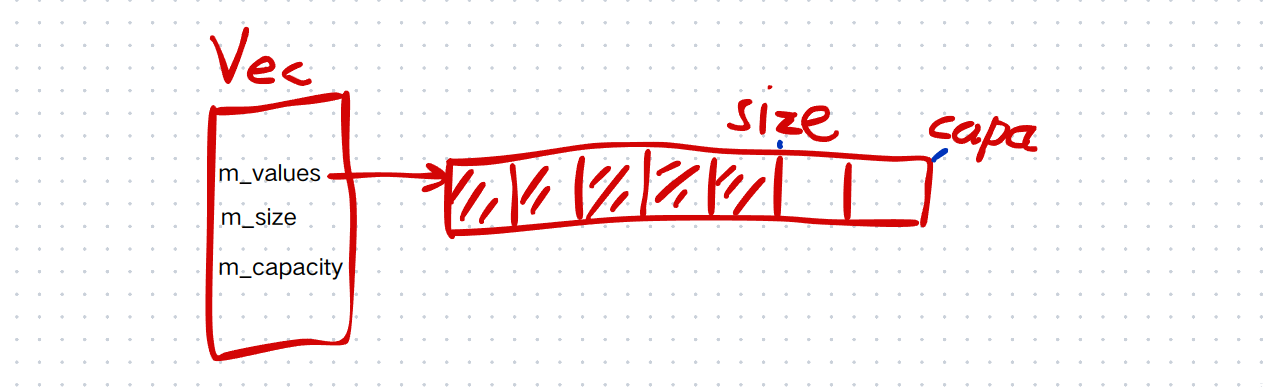
new (m_values+i) T(val); 和 m_values[i] = val并不等价
当value_type包含虚函数时后者不能正确处理虚函数表指针,而前者却可以。

如图所示,new (m_values+i) T(val)可以正确处理虚表指针,而m_values[i] = val的_vptr.TestSt = 0x0
#include <stdlib.h>
#include <algorithm>
template <class T>
class Vector
{
private:
T* m_values;
size_t m_size, m_capacity;
public:
typedef T value_type;
typedef T* iterator;
Vector(): m_values(nullptr), m_size(0), m_capacity(0) {}
~Vector()
{
for (size_t i = 0; i < m_size; i++)
{
m_values[i].~T();
}
free(m_values);
m_values = nullptr;
m_size = m_capacity = 0;
}
Vector(size_t n, const T& val): m_values(nullptr), m_size(n),m_capacity(n)
{
m_values = (T*)malloc(sizeof(T) * m_capacity);
for (size_t i = 0; i < n; i++)
{
new (m_values+i) T(val);
}
}
Vector(const Vector<T>& tocopy)
{
m_values = (T*)malloc(sizeof(T) * tocopy.m_capacity);
m_size = tocopy.m_size;
m_capacity = tocopy.m_capacity;
for (size_t i = 0; i < m_size; i++)
{
new (m_values+i) T(tocopy.m_values[i]);
}
}
Vector<T>& operator=(const Vector<T>& tocopy)
{
if (&tocopy == this) return *this;
Vector<T> tmp(tocopy);
std::swap(m_values, tmp.m_values);
std::swap(m_size, tmp.m_size);
std::swap(m_capacity, tmp.m_capacity);
return *this;
}
value_type& operator[](size_t idx)
{
return m_values[idx];
}
void push_back(const T& val)
{
if (m_size + 1 > m_capacity)
{
m_capacity = m_capacity ? 2*m_capacity : 1;
T* tmp = (T*)malloc(sizeof(T) * m_capacity);
for (size_t i = 0; i < m_size; i++)
{
new (tmp+i) T(m_values[i]);
m_values[i].~T();
}
free(m_values);
m_values = tmp;
}
new (m_values+m_size) T(val);
++m_size;
}
void pop_back()
{
m_values[m_size].~T();
// if ~T() _did_ throw, everything is OK,
// but push_back Unable to handle throw
--m_size;
}
void clear()
{
for (size_t i = 0; i < m_size; i++)
{
m_values[i].~T();
}
m_size = 0;
}
size_t size() { return m_size; }
iterator begin()
{
return m_values;
}
iterator end()
{
return m_values + m_size;
}
};
2. X
● 无锁栈

// lock_free_stack
template <class T, class Alloc=std::allocator<T>>
class lock_free_stack
{
private:
struct Node
{
Node(const T& tocopy): m_data(tocopy), m_next(0) {}
T m_data;
Node* m_next = nullptr;
};
std::atomic<Node*> m_top;
std::atomic_size_t m_size;
public:
lock_free_stack(const lock_free_stack&) = delete;
lock_free_stack& operator=(const lock_free_stack&) = delete;
lock_free_stack(const lock_free_stack&&) = delete;
lock_free_stack& operator=(const lock_free_stack&&) = delete;
lock_free_stack()
{
m_top.store(nullptr);
m_size.store(0);
}
T& top()
{
return m_top.load()->m_data ;
}
bool push(const T& tocopy)
{
Node* new_node = new (std::nothrow) Node(tocopy);
if (!new_node) return false;
new_node->m_next = m_top.load();
while ( !m_top.compare_exchange_strong(new_node->m_next, new_node, std::memory_order_acq_rel) ) sched_yield();
m_size.fetch_add(1);
return true;
}
void pop()
{
// other threads spin
Node* __always_top = nullptr;
do
{
__always_top = m_top.load();
if (!__always_top) return;
} while ( !m_top.compare_exchange_strong(__always_top, __always_top->m_next, std::memory_order_acq_rel) );
__always_top->m_next = nullptr;
delete __always_top;
m_size.fetch_sub(1);
}
size_t size()
{
return m_size.load();
}
~lock_free_stack() = default;
};
● 一种高性能队列实现

// yqueue is an efficient queue implementation. The main goal is
// to minimise number of allocations/deallocations needed. Thus yqueue
// allocates/deallocates elements in batches of N.
//
// yqueue allows one thread to use push/back function and another one
// to use pop/front functions. However, user must ensure that there's no
// pop on the empty queue and that both threads don't access the same
// element in unsynchronised manner.
//
// T is the type of the object in the queue.
// N is granularity of the queue (how many pushes have to be done till
// actual memory allocation is required).
//
// ALIGN is the memory alignment size to use in the case where we have
// posix_memalign available. Default value is 64, this alignment will
// prevent two queue chunks from occupying the same CPU cache line on
// architectures where cache lines are <= 64 bytes (e.g. most things
// except POWER). It is detected at build time to try to account for other
// platforms like POWER and s390x.
template <typename T, int N, size_t ALIGN = 64>
class yqueue_t
{
public:
inline yqueue_t ()
{
_begin_chunk = allocate_chunk ();
alloc_assert (_begin_chunk);
_begin_pos = 0;
_back_chunk = NULL;
_back_pos = 0;
_end_chunk = _begin_chunk;
_end_pos = 0;
}
inline ~yqueue_t ()
{
while (true) {
if (_begin_chunk == _end_chunk) {
free (_begin_chunk);
break;
}
chunk_t *o = _begin_chunk;
_begin_chunk = _begin_chunk->next;
free (o);
}
chunk_t *sc = _spare_chunk.xchg (NULL);
free (sc);
}
inline T &front () { return _begin_chunk->values[_begin_pos]; }
inline T &back () { return _back_chunk->values[_back_pos]; }
inline void push ()
{
_back_chunk = _end_chunk;
_back_pos = _end_pos;
if (++_end_pos != N)
return;
chunk_t *sc = _spare_chunk.xchg (NULL);
if (sc) {
_end_chunk->next = sc;
sc->prev = _end_chunk;
} else {
_end_chunk->next = allocate_chunk ();
alloc_assert (_end_chunk->next);
_end_chunk->next->prev = _end_chunk;
}
_end_chunk = _end_chunk->next;
_end_pos = 0;
}
// Removes element from the back end of the queue. In other words
// it rollbacks last push to the queue. Take care: Caller is
// responsible for destroying the object being unpushed.
// The caller must also guarantee that the queue isn't empty when
// unpush is called. It cannot be done automatically as the read
// side of the queue can be managed by different, completely
// unsynchronised thread.
inline void unpush ()
{
if (_back_pos)
--_back_pos;
else {
_back_pos = N - 1;
_back_chunk = _back_chunk->prev;
}
if (_end_pos)
--_end_pos;
else {
_end_pos = N - 1;
_end_chunk = _end_chunk->prev;
free (_end_chunk->next);
_end_chunk->next = NULL;
}
}
inline void pop ()
{
if (++_begin_pos == N) {
chunk_t *o = _begin_chunk;
_begin_chunk = _begin_chunk->next;
_begin_chunk->prev = NULL;
_begin_pos = 0;
chunk_t *cs = _spare_chunk.xchg (o);
free (cs);
}
}
private:
struct chunk_t
{
T values[N];
chunk_t *prev;
chunk_t *next;
};
static inline chunk_t *allocate_chunk ()
{
void *pv;
if (posix_memalign (&pv, ALIGN, sizeof (chunk_t)) == 0)
return (chunk_t *) pv;
return NULL;
}
// Back position may point to invalid memory if the queue is empty,
// while begin & end positions are always valid. Begin position is
// accessed exclusively be queue reader (front/pop), while back and
// end positions are accessed exclusively by queue writer (back/push).
chunk_t *_begin_chunk;
int _begin_pos;
chunk_t *_back_chunk;
int _back_pos;
chunk_t *_end_chunk;
int _end_pos;
// People are likely to produce and consume at similar rates. In
// this scenario holding onto the most recently freed chunk saves
// us from having to call malloc/free.
atomic_ptr_t<chunk_t> _spare_chunk;
yqueue_t (const yqueue_t &) = delete;
yqueue_t &operator= (const yqueue_t &) = delete;
yqueue_t (yqueue_t &&) = delete;
yqueue_t &operator= (yqueue_t &&) = delete;
};















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









