






spark 说说轻快灵巧,但开发真的好多东西😕
回顾spark两种算子:
- transformation:是lazy的算子,并不会马上执行,需要等到action操作的时候才会启动真正的计算过程,如map,filter,join。
- action:是spark应用真正执行的触发动作,如count,collect,save等。
一开始我只知道两个算子的概念,并没有实质理解,但最近有点悟到,transformation返回值是一个RDD,而action返回结果或者将结果写入存储
由于spark是基于scala语言的,但没有scala的功底,后期选择java进行开发:
在spark客户端简单的用scala实现了Wordcount:
进入spark客户端:

现在就成功进来啦
在scala中有两种变量
val:常量 如rdd,只读的
var:变量
sc 可以理解冲java中的sparkcontext spark的功能入口
直接跟路径,默认读取的是HDFS上的数据:


调用flatmap方法将数据从hdfs中读取,并通过“ ”切分成字符串,调用map和reduce进行合并

在调用collect就不会报错了:
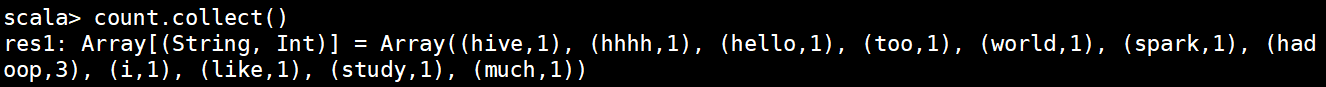
接下来进入java开发:
Spark-core常用接口介绍:
| JavaSparkContext | 是spark的对外接口,负责向调用该类的java应用提供spark的各种功能,相当于一个百宝箱 |
|---|---|
| SparkConf | Spark应用配置类 如设置应用名称,执行模式,executor内存等 |
| JavaRDD<> | 用于在java应用中定义JavaRDD的类 只有值(value) |
| JavaPairRDD<> | 表示key-value形式的JavaRDD类,提供的方法有groupByKey,reduceByKey等 以键值对的方式 |
案例一:RDD的创建
package com.spark;
import java.io.File;
import org.apache.cassandra.cli.CliParser.newColumnFamily_return;
import org.apache.hadoop.fs.FileSystem;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class GenerateRddforTextFile {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 设置本地运行路径,需要搭建windows hadoop环境 可省略
// System.setProperty("hadoop.home.dir", "E:\\hadoop-2.6.5\\");
// 本地部署,获取文件路径,file.separator:“/” "user.dir"===》当前执行路径
String basedir = System.getProperty("user.dir")+File.separator+"conf"+File.separator;
// 实例化conf,配置部署方式为local ,设置程序名称
SparkConf conf= new SparkConf().setAppName("TextFileRDD").setMaster("local");
@SuppressWarnings("resource")//没有特殊意义,只是为了不报警告
// 实例化sparkcontext,为整个App程序操作入口,一个JVM同一时刻只允许一个sparkcontext处于活动状态
JavaSparkContext sc = new JavaSparkContext(conf);
// 生成RDD,并读取本地文件中的指定内容
JavaRDD<String> textRDD = sc.textFile(basedir+"spark-info.txt",2);
System.out.println(textRDD.collect());
System.out.println("---------------");
// 读取某个目录中的所有文件
JavaPairRDD<String,String> textPairRDD = sc.wholeTextFiles(basedir);
System.out.println(textPairRDD.collect());
案例二:
wordcount:
package com.spark;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import org.apache.cassandra.cli.CliParser.newColumnFamily_return;
import org.apache.hadoop.hive.ql.parse.HiveParser_IdentifiersParser.nullCondition_return;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import scala.Tuple12;
import scala.Tuple2;
public class wordcount {
public static void main(String[] args) {
String dir = System.getProperty("user.dir")+File.separator+"conf"+File.separator+"spark-info.txt";
SparkConf conf = new SparkConf().setAppName("WordCount").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> line = sc.textFile(dir,2);
JavaPairRDD<String, Integer>pairRDD=line.flatMapToPair(
new PairFlatMapFunction<String, String, Integer>() {
List<Tuple2<String,Integer>>list =new ArrayList<>();
@Override
public Iterable<Tuple2<String, Integer>> call(String s) throws Exception {
// TODO Auto-generated method stub
list.clear();
if(s!=null && !s.matches("\\s+")) {
String[]word = s.split(",");
if (word.length>0) {
for (int i = 0; i < word.length; i++) {
list.add(new Tuple2(word[i],1));
}
}
}
return list;
}
});
JavaPairRDD<String, Integer>countRdd = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
// TODO Auto-generated method stub
return v1+v2;
}
});
System.out.println(countRdd.sortByKey().collectAsMap());
}
}
案例3:并行化集合
package com.spark;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.cassandra.cli.CliParser.newColumnFamily_return;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.dmg.pmml.True;
import com.huawei.bigdata.om.controller.api.common.backup.rpc.BackupRecoveryPluginService.AsyncProcessor.startBackup;
import com.sun.org.apache.regexp.internal.recompile;
import scala.annotation.meta.companionClass;
public class GenerateRddForParallelize {
public static void main(String[] args) {
// TODO Auto-generated method stub
// 实例化sparkconf 设置程序名称和部署方式
SparkConf conf =new SparkConf().setAppName("ParallelizeRDD").setMaster("local");
// 实例化SparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 创建整型的集合,主要有arraylist 和 linkedList两个实现类
List<Integer> list = Arrays.asList(1,2,3,4,5,6);
// 生成RDD,调用spark parallelize的方法获取list集合中的元素,并设置两个分区
JavaRDD<Integer> rdd = sc.parallelize(list,2);
System.out.println(rdd.partitions().size());
// 调用collect方法打印rdd当中的内容
System.out.println(rdd.collect());
// mappartitionswithindex 把rdd中的每个partition的索引和值赋给括号里面的函数,函数需要自定义
JavaRDD rdd2 = rdd.mapPartitionsWithIndex(new TakePartitionDataWithIndex(),true);
System.out.println(rdd2.collect());
}
@SuppressWarnings("serial")
// function2:两个输入一个输出 partition索引 内容
static class TakePartitionDataWithIndex implements Function2<Integer,Iterator<Integer>,Iterator<String>>{
List<String> list =new ArrayList<String>();
@Override
public Iterator<String> call(Integer v1, Iterator<Integer> v2){
while (v2.hasNext()) {
list.add("partition" + v1 +":" + v2.next());
}
return list.iterator();//传给rdd2
}
}
}
在运行过程中会由于各种原因报错,一定要对应自己定义的变量个实例,还有部署方式!!!















 1176
1176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









