







安装Scala
版本选择
Spark官方对配套的Scala版本有规定,所以要根据自己的实际情况来选择Scala版本。因此首先去Spark官网下载Spark,再根据要求下载对应版本的Scala。
在http://spark.apache.org/docs/1.6.2/中有一句提示:
Spark runs on Java 7+, Python 2.6+ and R 3.1+. For the Scala API, Spark 1.6.2 uses Scala 2.10. You will need to use a compatible Scala version (2.10.x).意味着Spark 1.6.2版本最好选择Scala 2.10.x。当然也可以选择更高版本的2.11.x,比如2.11.8,不过需要手动编译。
结合上一篇文章,Hadoop和Spark版本最好也要适配,选择pre-build版本。也可以选择source code或者自己指定Hadoop版本,这部分知识本文不再介绍。
此处版本为spark-1.6.2-bin-hadoop2.6和scala-2.10.6,还有hadoop-2.6.4版本。注意自己实现的时候版本兼容选择。
安装
1、 将下载的压缩包解压后放入指定位置,usr/lib/scala。
root@master:~/Documents# ls
hadoop-2.4.6.tar.gz scala-2.10.6.tgz spark-1.6.2-bin-hadoop2.6.tgz
root@master:~/Documents# tar zxvf scala-2.10.6.tgz
......
root@master:~/Documents# mkdir /usr/lib/scala
root@master:~/Documents# mv scala-2.10.6 /usr/lib/scala/
root@master:~/Documents# cd /usr/lib/scala/
root@master:/usr/lib/scala# ls
scala-2.10.6
root@master:/usr/lib/scala#2、 配置环境变量
打开~/.bashrc文件(默认是root用户登录,因此此处绝对路径为/root/.bashrc,前文中没有特殊说明的情况下均采用这里的标准),配置Scala环境变量。主要为SCALA_HOME和PATH。
#if [ -f /etc/bash_completion ] && ! shopt -oq posix; then
# . /etc/bash_completion
#fi
export JAVA_HOME=/usr/lib/java/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=${JAVA_HOME}/jre
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.4.6
export SCALA_HOME=/usr/lib/scala/scala-2.10.6然后root@master:~# source .bashrc,使配置生效。
注意$SCALA_HOME这种书写方式,书本是使用${SCALA_HOME}。但是scala -version失败。这里还是自己测试一下,一种不行再试另一种,多折腾。
3、 测试配置是否成功
在终端输入scala -version查看Scala的版本信息。
不成功的话,再返回上面修改。成功后,可以直接使用scala进入Scala的命令交互界面。
root@master:~# scala
Welcome to Scala version 2.10.6 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91).
Type in expressions to have them evaluated.
Type :help for more information.
scala> 3*4
res0: Int = 12
scala> 到这里基本安装成功。master主机已经配置好,其余主机也做相应配置即可。
4、 迁移到其他主机
另外两台worker主机也需要与master主机保持一致。因此考虑使用scp命令复制Scala文件夹和~/.bashrc文件到其余主机。
root@master:/usr/lib# scp -r scala/ root@worker1:/usr/lib/
root@master:/usr/lib# scp ~/.bashrc root@worker1:~
root@master:/usr/lib# scp -r scala/ root@worker2:/usr/lib/
root@master:/usr/lib# scp ~/.bashrc root@worker2:~记得最后在worker主机上source让配置文件生效。
当然也可以手动配置,重复上述过程。
最后测试一下其余主机Scala是否可用。
安装Spark和集群部署
Spark需要运行在三台机器上,这里先安装Spark到master主机上,另外两台的安装方法一样,也可以使用SSH的scp命令把master主机上的安装好的Spark目录复制到另外两台机器相同的目录下。
1、 将下载的Spark放置在指定目录:/usr/local/spark。
按照之前的描述,下载适配版本的Spark并解压。如此处的spark-1.6.2-bin-hadoop2.6.tgz。
root@master:~/Documents# tar zxvf spark-1.6.2.tgz
...
root@master:~/Documents# mkdir /usr/local/spark
root@master:~/Documents# ls
hadoop-2.4.6.tar.gz scala-2.10.6.tgz spark-1.6.2-bin-hadoop2.6 spark-1.6.2-bin-hadoop2.6.tgz
root@master:~/Documents# mv spark-1.6.2-bin-hadoop2.6 /usr/local/spark/
root@master:~/Documents# cd /usr/local/spark/
root@master:/usr/local/spark# ls
spark-1.6.2-bin-hadoop2.6
root@master:/usr/local/spark#2、 配置环境变量
修改~/.bashrc文件,添加SPARK_HOME,将spark的bin目录添加至PATH:
root@master:~# cat .bashrc
...
# . /etc/bash_completion
#fi
export JAVA_HOME=/usr/lib/java/jdk1.8.0_91
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=${JAVA_HOME}/jre
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.4.6
export SCALA_HOME=/usr/lib/scala/scala-2.10.6
export SPARK_HOME=/usr/local/spark/spark-1.6.2-bin-hadoop2.6
root@master:~#保存并退出。使用source命令使配置文件生效。
3、 配置Spark
需要配置spark-env.sh文件和slaves文件,没有的话可以根据该目录下的template文件创建。
进入Spark安装目录下的conf目录,根据模板创建新文件。
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6# cd conf
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# ls
docker.properties.template metrics.properties.template spark-defaults.conf.template
fairscheduler.xml.template slaves spark-env.sh
log4j.properties.template slaves.template spark-env.sh.template
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# cp spark-env.sh.template spark-env.sh
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# cp slaves.template slaves修改spark-env.sh,在最后添加下面的信息。
保存退出。
最终效果如下:
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# cat spark-env.sh
#!/usr/bin/env bash
...
export JAVA_HOME=/usr/lib/java/jdk1.8.0_91
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.4.6
export SCALA_HOME=/usr/lib/scala/scala-2.10.6
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.7.2/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=1
export SPARK_WORKER_INSTANCES=1
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf#上面各个参数的作用在文档中已经提及。可以自行查阅进行个性化配置。
修改slaves文件。
最终效果如下:
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# vim slaves
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf# cat slaves
#
...
# A Spark Worker will be started on each of the machines listed below.
worker1
worker2
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6/conf#这里只设置两台worker主机为工作节点。
4、 配置其余主机
worker1和worker2的配置与master主机完全相同。可以通过SSH的scp命令将Spark的安装目录和~/.bashrc文件复制到两台worker主机。
这里不再赘述。
5、 启动并测试集群的状况
1) 当前我们只使用Hadoop的HDF文件系统,所以可以只启动master主机Hadoop的HDFS文件系统。进入Hadoop的sbin目录下,然后在shell命令终端输入./start-dfs.sh命令,可以看到master启动了namenodes,worker1和worker2都启动了datanode,表示HDFS文件系统已经启动。
root@master:/usr/local/hadoop/hadoop-2.4.6# ./sbin/start-dfs.sh这时候会启动上一篇文章中的部分服务。具体可以通过jsp查看。
2) 用Spark的sbin目录下的./start-all.sh命令启动Spark集群。
如果上面配置没有问题的话,就可以很顺利的开启服务了。
提示信息也很简洁。仅供对照。
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-1.6.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
worker2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.6.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker2.out
worker1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.6.2-bin-hadoop2.6/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker1.out
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6#6、 简单验证
1)使用JPS在master结点、worker1、2结点分别可以查看到新开启的Master和Worker进程。
master:
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6# jps
3600 SecondaryNameNode
3289 NameNode
3914 Master
3983 Jps
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6#worker1:
root@worker1:~# jps
12245 Worker
11592 DataNode
12299 Jps
root@worker1:~#worker2:
root@worker2:~# jps
12019 Jps
11325 DataNode
11966 Worker
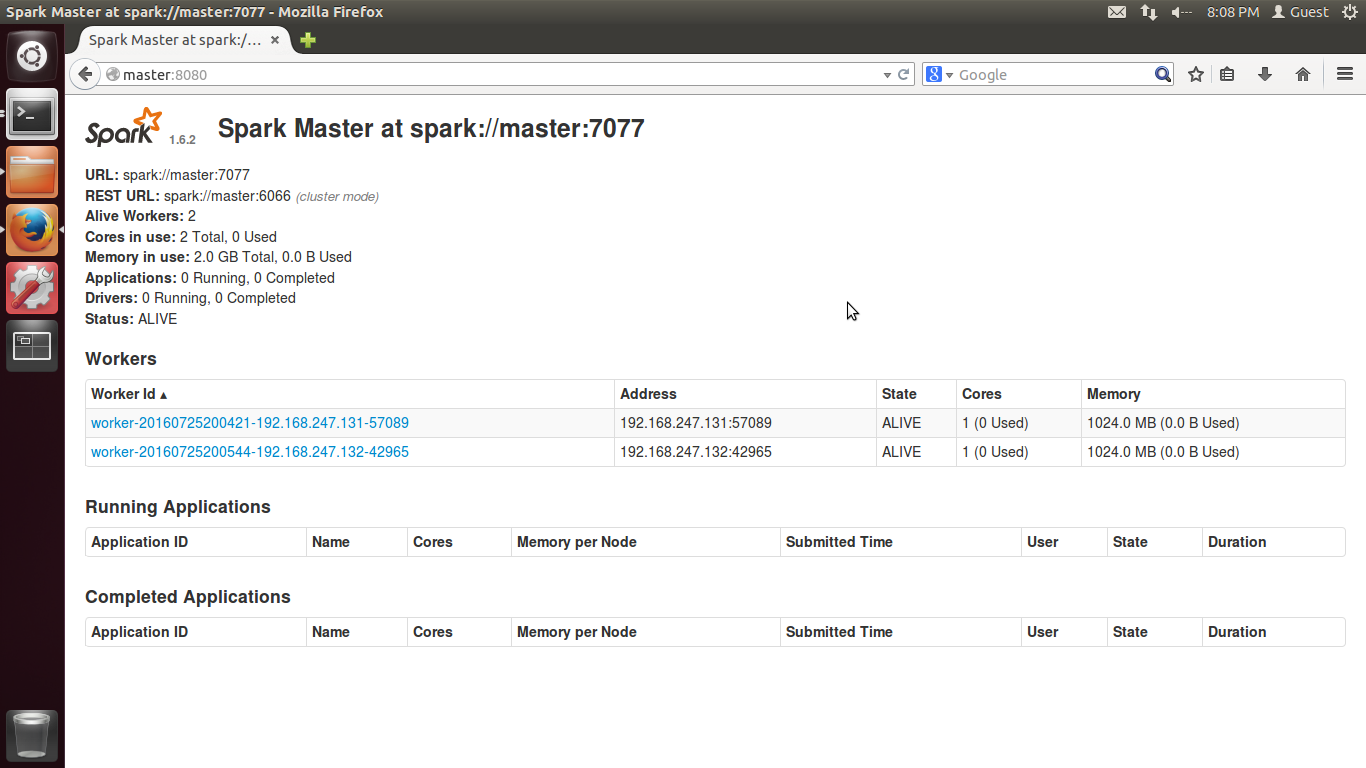
root@worker2:~#2)进入Spark的WebUI页面,访问master:8080,可以看到如下图所示的界面。
3)进入Spark的bin目录,使用spark-shell命令可以进入spark-shell控制台。
root@master:/usr/local/spark/spark-1.6.2-bin-hadoop2.6# ./bin/spark-shell
16/07/25 20:10:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/07/25 20:10:30 INFO spark.SecurityManager: Changing view acls to: root
16/07/25 20:10:30 INFO spark.SecurityManager: Changing modify acls to: root
16/07/25 20:10:30 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/07/25 20:10:31 INFO spark.HttpServer: Starting HTTP Server
16/07/25 20:10:31 INFO server.Server: jetty-8.y.z-SNAPSHOT
16/07/25 20:10:31 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:46693
16/07/25 20:10:31 INFO util.Utils: Successfully started service 'HTTP class server' on port 46693.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.2
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91)
Type in expressions to have them evaluated.
Type :help for more information.
16/07/25 20:10:52 INFO spark.SparkContext: Running Spark version 1.6.2
16/07/25 20:10:53 WARN spark.SparkConf:
SPARK_WORKER_INSTANCES was detected (set to '1').
This is deprecated in Spark 1.0+.
Please instead use:
- ./spark-submit with --num-executors to specify the number of executors
- Or set SPARK_EXECUTOR_INSTANCES
- spark.executor.instances to configure the number of instances in the spark config.
16/07/25 20:10:53 INFO spark.SecurityManager: Changing view acls to: root
16/07/25 20:10:53 INFO spark.SecurityManager: Changing modify acls to: root
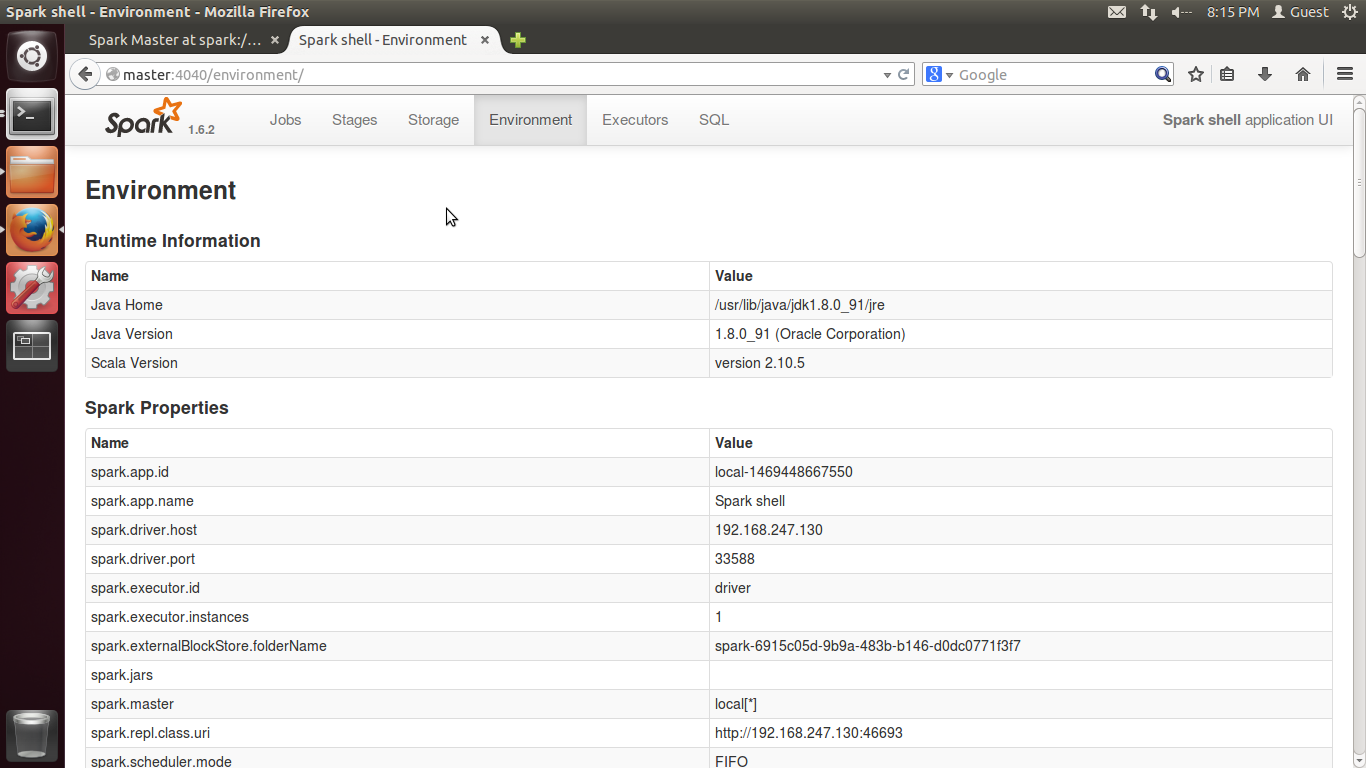
......然后可以在WebUI页面输入master:4040从Web的角度了解Spark-Shell,也可以查看environment(注意此时不要退出或者关闭Spark-Shell,否则4040无法访问)。如下图所示:

到这里,Spark集群部署成功,下面进行集群的测试。
小结
回顾一下上面的整体步骤:配置好Hadoop、Spark、Scala之后,首先通过start-dfs.sh开启Hadoop,然后通过start-all.sh开启Spark,之后运行spark-shell,即可查看4040。
关闭的顺序和上面相反。
错误提示
如果执行完./sbin/start-dfs.sh后,再执行./sbin/start-all.sh的时候出错,如下:
root@master:/usr/local/spark/spark-1.6.2# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-1.6.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
failed to launch org.apache.spark.deploy.master.Master:
Failed to find Spark assembly in /usr/local/spark/spark-1.6.2/assembly/target/scala-2.10.
You need to build Spark before running this program.
full log in /usr/local/spark/spark-1.6.2/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.out
worker1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.6.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker1.out
worker2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-1.6.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker2.out
worker1: failed to launch org.apache.spark.deploy.worker.Worker:
worker1: Failed to find Spark assembly in /usr/local/spark/spark-1.6.2/assembly/target/scala-2.10.
worker1: You need to build Spark before running this program.
worker1: full log in /usr/local/spark/spark-1.6.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker1.out
worker2: failed to launch org.apache.spark.deploy.worker.Worker:
worker2: Failed to find Spark assembly in /usr/local/spark/spark-1.6.2/assembly/target/scala-2.10.
worker2: You need to build Spark before running this program.
worker2: full log in /usr/local/spark/spark-1.6.2/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-worker2.out
root@master:/usr/local/spark/spark-1.6.2#问题的原因在于文章开始的时候提到的Spark版本和Hadoop版本不兼容。资料介绍说Hadoop版本迭代的时候某些组件变化较大,因此Spark版本最好选择spark-1.6.2-bin-hadoop2.6这种和Hadoop绑定的版本。
参考文章:
- Spark(一):Spark的安装部署。 http://my.oschina.net/gently/blog/686192















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









