









之前分享过批量下载公众号文章导出html2023 更新版:苏生不惑开发过的那些原创工具和脚本,然后用pyppeteer转换html为pdf ,最近pip install -U pyppeteer 升级版本后发现不能用了,这里分享下解决方案,提示Starting Chromium download,要重新下载对应chromium:
[INFO] Starting Chromium download.
Traceback (most recent call last):
File "htmltopdf.py", line 95, in <module>
asyncio.get_event_loop().run_until_complete(main())
File "E:\anaconda\lib\asyncio\base_events.py", line 642, in run_until_complete
return future.result()
File "htmltopdf.py", line 16, in main
browser = await launch()
File "E:\anaconda\lib\site-packages\pyppeteer\launcher.py", line 307, in launch
return await Launcher(options, **kwargs).launch()
File "E:\anaconda\lib\site-packages\pyppeteer\launcher.py", line 120, in __init__
download_chromium()
File "E:\anaconda\lib\site-packages\pyppeteer\chromium_downloader.py", line 138, in download_chromium
extract_zip(download_zip(get_url()), DOWNLOADS_FOLDER / REVISION)
File "E:\anaconda\lib\site-packages\pyppeteer\chromium_downloader.py", line 82, in download_zip
raise OSError(f'Chromium downloadable not found at {url}: ' f'Received {r.data.decode()}.\n')
OSError: Chromium downloadable not found at https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/1181205/chs not exist.</Message><Details>No such object: chromium-browser-snapshots/Win_x64/1181205/chrome-win.zip</Details></Error>.
下载哪个版本的chromium可以使用如下代码:
import pyppeteer.chromium_downloader
PYPPETEER_CHROMIUM_REVISION = '1263111'
print('版本:{}'.format(pyppeteer.__chromium_revision__))
print('文件路径:{}'.format(pyppeteer.chromium_downloader.chromiumExecutable.get('win64')))
print('下载链接:{}'.format(pyppeteer.chromium_downloader.downloadURLs.get('win64')))
版本:1181205
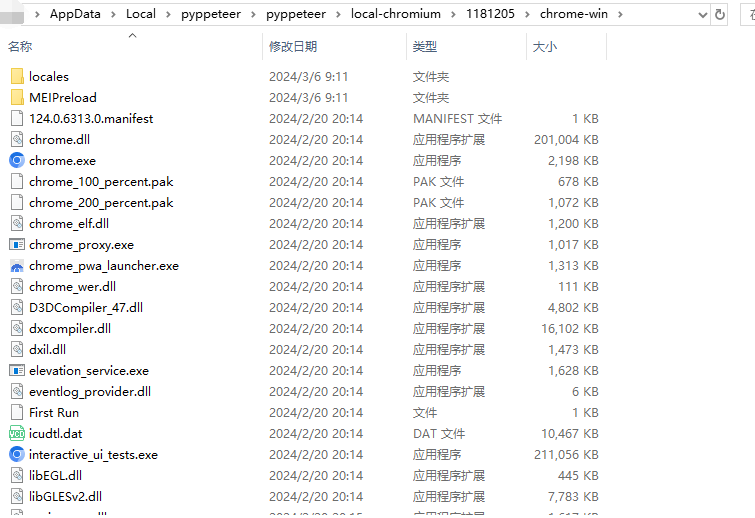
文件路径:C:\Users\xxx\AppData\Local\pyppeteer\pyppeteer\local-chromium\1181205\chrome-win\chrome.exe
下载链接:https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/1181205/chrome-win.zip https://pan.quark.cn/s/330b0d5d2d10
可是https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/1181205/chrome-win.zip 这个文件被删了,搜了下https://stackoverflow.com/questions/78023508/pyton-request-html-is-not-downloading-chromium, 用1263111版本就行 https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/1263111/chrome-win.zip ,下载后解压到C:\Users\xxx\AppData\Local\pyppeteer\pyppeteer\local-chromium新建的目录1181205 ,mac版本在这里找https://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html 。
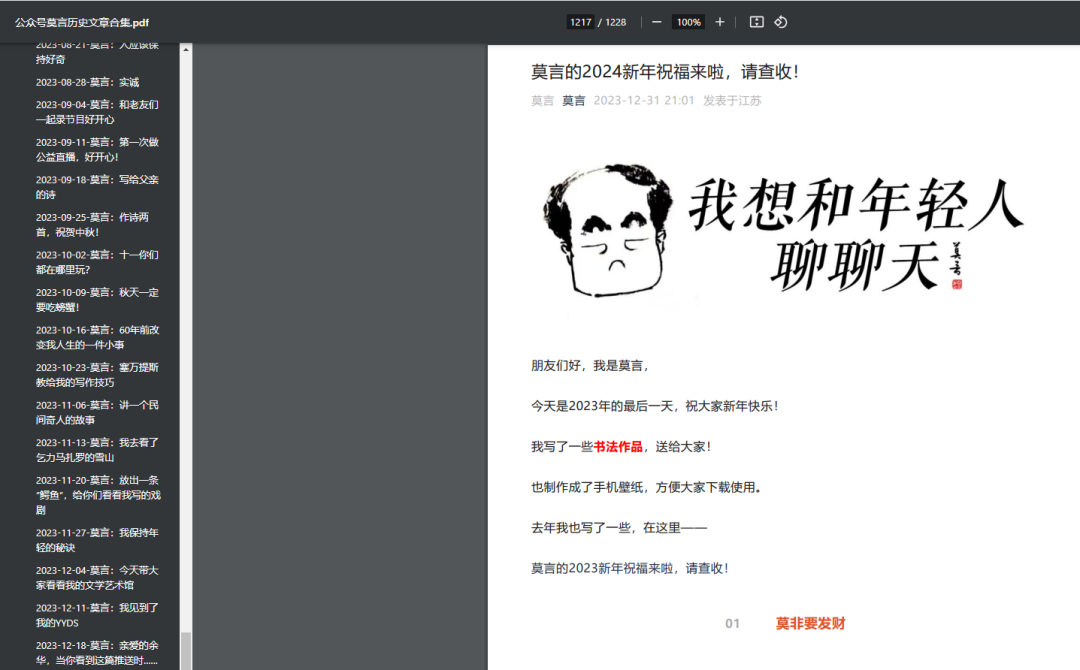
然后就可以用了,转换pdf效果:

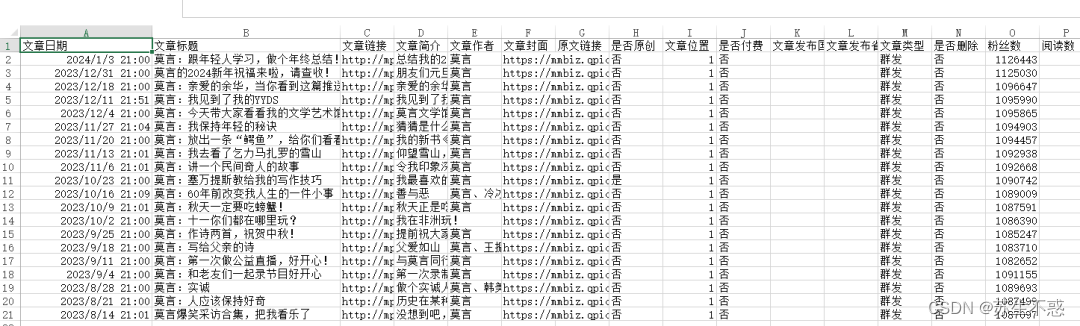
以莫言的公众号文章为例研究了下莫言的公众号,2023年发布文章166篇,阅读数10万+的文章有120篇,粉丝数过百万 ,网盘地址https://pan.quark.cn/s/afa15a7b027b
还有导出的文章数据excel文件,数据包含文章日期,文章标题,文章链接,文章简介,文章作者,文章封面图,是否原创,文章类型,是否删除,IP归属地,阅读数,在看数,点赞数,粉丝数,留言数等,莫言2024年1月3日的粉丝数 1126443:
再次更新:2023批量下载公众号文章内容/话题/图片/封面/视频/音频,导出文章pdf,文章数据含阅读数/点赞数/在看数/留言数
一次性搞定微博,苏生不惑又写了个脚本,一键下载微博内容导出pdf,批量抓取微博评论转发数据导出excel
苏生不惑出品:2024 批量下载知乎回答,文章和想法,导出 excel 和 pdf ,文章数据包括标题,链接,赞同数

















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









