






1.我遇到的痛点
1.微服务的服务器多,日志都分散在不同的服务器节点上,查找问题是否头疼。如何构建一个统一的日志查看平台在项目中后期显得非常必要。
2.如何通过一种直观的方式来展示日志,让开发和测试和运维都方便使用。
3.如何通过日志看一次交易调用服务的整个过程以及每个服务节点的调用时长,方便问题的查询和定位
2.解决方案的介绍
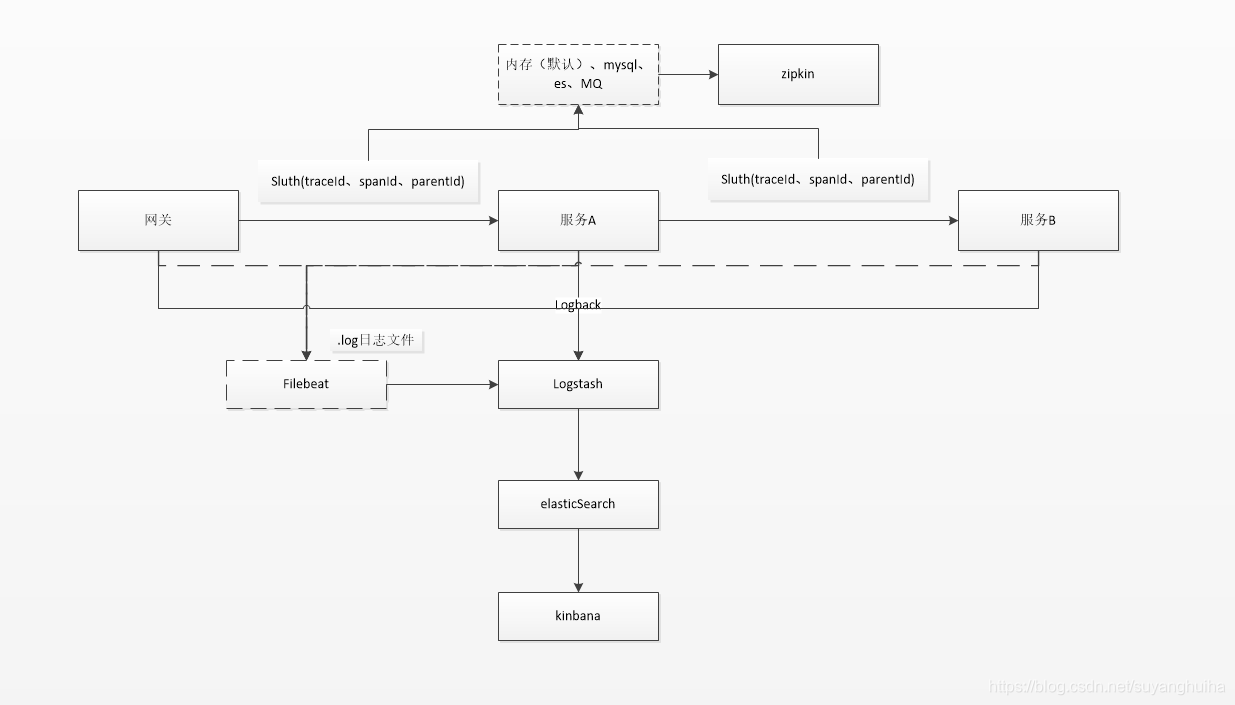
3.名称解释
filebeat:一款轻量级的日志传输工具,它有输入和输出两端,通常是从日志文件中读取数据,输出到 Logstash 或 Elasticsearch 。其作用是收集业务服务器的日志,输出到一个日志系统便于集中管理。
logstash:是一个对文件日志或者syslog日志以及其他各种类型的输入数据流进行解码,过滤,转换并转换为其他类型的数据流的软件,最常见的用法是将系统日志分析,结构化处理后倒入到ElasticSearch中。当然logstash也可以独立的完成很多日志/事件处理的工作,并不是必须要和ElasticSearch配合使用,可以和redis和kafka一起使用。
ElasticSearch:是一个基于全文检索引擎lucene实现的一个面向文档的schema free(模式自由)的数据库。所有对数据库的配置、监控及操作都通过Restful接口完成。数据格式为json。默认支持节点自动发现,数据自动复制,自动分布扩展,自动负载均衡。适合处理最大千万级别的数据的检索。处理效率非常高。可以理解为elasticSearch是一个在lucene基础上增加了restful接口及分布式技术的整合。
kinbana : Kibana是一个通过Restful接口对ElasticSearch数据库进行检索,通过HTML5形式以柱状图,饼图,线图,地理位置分布图以及表格等形式展示数据的软件。
Sleuth: Spring-Cloud-Sleuth是Spring Cloud的组成部分之一,为SpringCloud应用实现了一种分布式追踪解决方案,其兼容了Zipkin, HTrace和log-based追踪。
zipkin:分布式跟踪系统;我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助查询跟踪数据以实现对分布式系统的监控程序,从而及时发现系统中出现的延迟过高问题。除了面向开发的 API 接口之外,它还提供了方便的 UI 组件来帮助我们直观地搜索跟踪信息和分析请求链路明细,比如可以查询某段时间内各用户请求的处理时间等。Zipkin 和 Config 结构类似,分为服务端 Server,客户端 Client,客户端就是各个微服务应用。
4.安装
安装讲解是Linux版本的手动安装,docker安装没研究。window下我试了一下不太稳定。
4.1安装前准备工作
1.关键jar
elasticsearch-6.8.6.tar.gz
logstash-6.8.6.tar.gz
kibana-6.8.6-linux-x86_64.tar.gz
下载地址
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-8-6
https://www.elastic.co/cn/downloads/past-releases/logstash-6-8-6
https://www.elastic.co/cn/downloads/past-releases/kibana-6-8-6
2.准备环境
jdk1.8 、centos 7
4.2安装ElasticSearch
1.通过xftp将jar上传服务器,然后解压jar包(elasticSearch和logstash都依赖jdk,所以要先安装jdk)

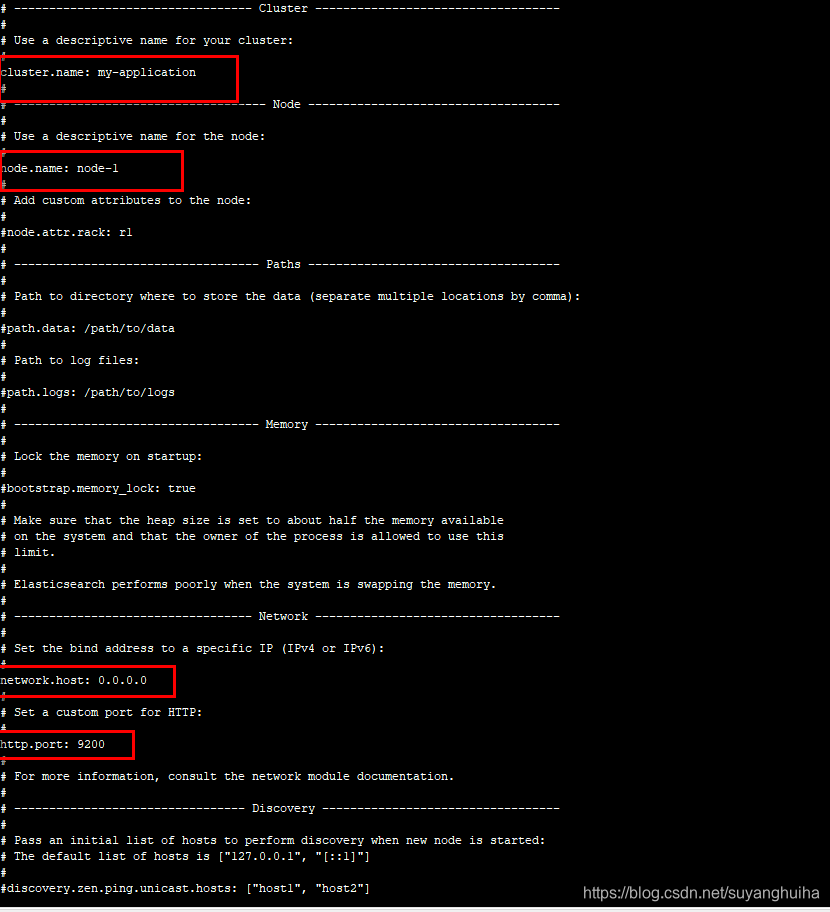
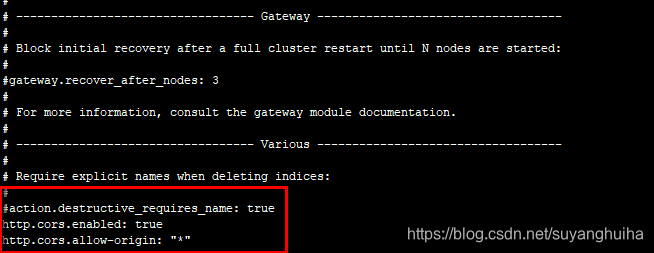
2.修改/elasticsearch-6.8.6/config/elasticsearch.yml 下的文件
3.启动服务
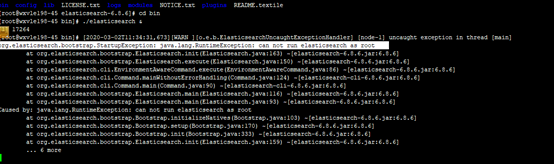
root用户是不能直接启动elasticsearch的,需要新建一个用户(elk)
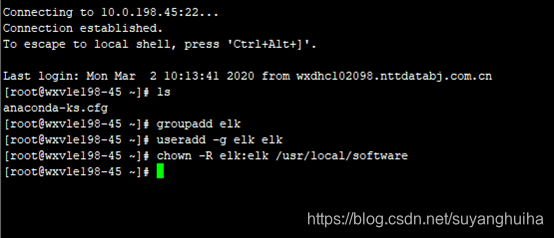
然后用elk用户启动,服务仍然报错(每个进程最大同时打开文件数太小;虚拟内存太小)

修改/etc/security/limits.conf
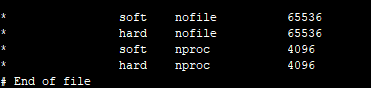
修改/etc/sysctl.conf
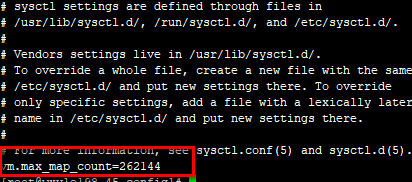
让系统重新载入sysctl.conf 文件(sysctl -p)

我用公司的服务器启动ok了,但是不能正常访问,上度娘上查一下,发现是防火墙的原因导致的,关闭之后就ok了(心里默默开心一分钟)

用elk用户在后台启动

启动成功
4.3安装logstash
1.解压jar包

2.在config下创建mylogstash.conf

3.修改mylogstash.conf (日志流的方式写入logstash)
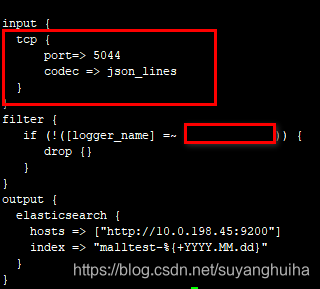
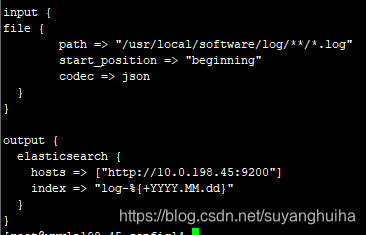
mylogstash.conf (日志文件的方式写入logstash)
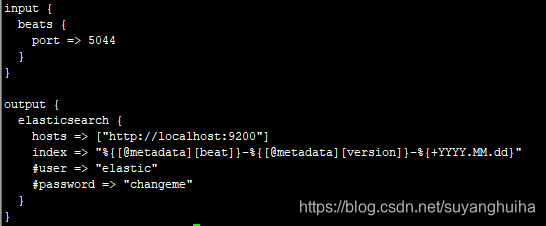
mylogstash.conf (beats轻量级采集组件(filebeat)方式写入logstash)
4.启动服务
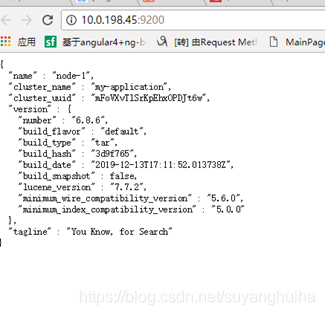
5.启动成功(访问http://10.0.198.45:9600)

6.应用场景
1.以logstash为日志文件的收集器。这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
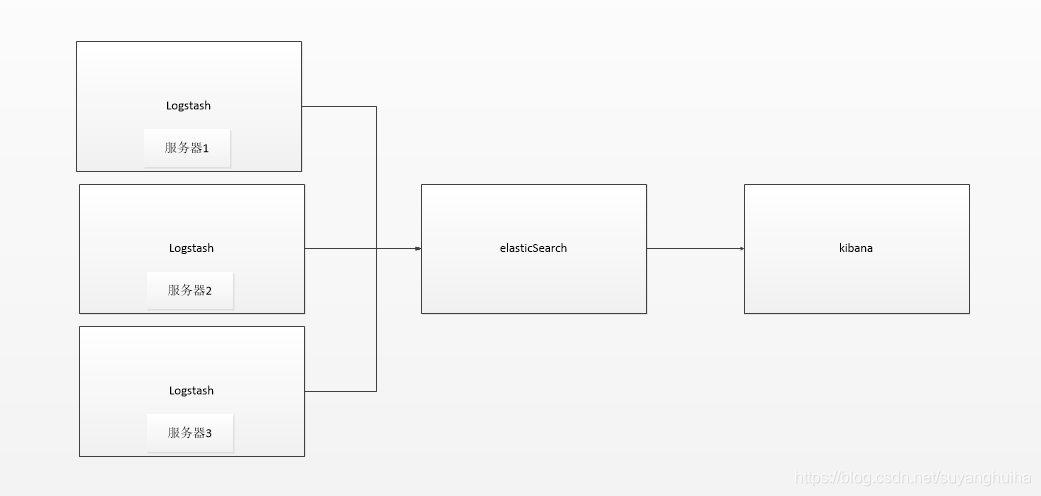
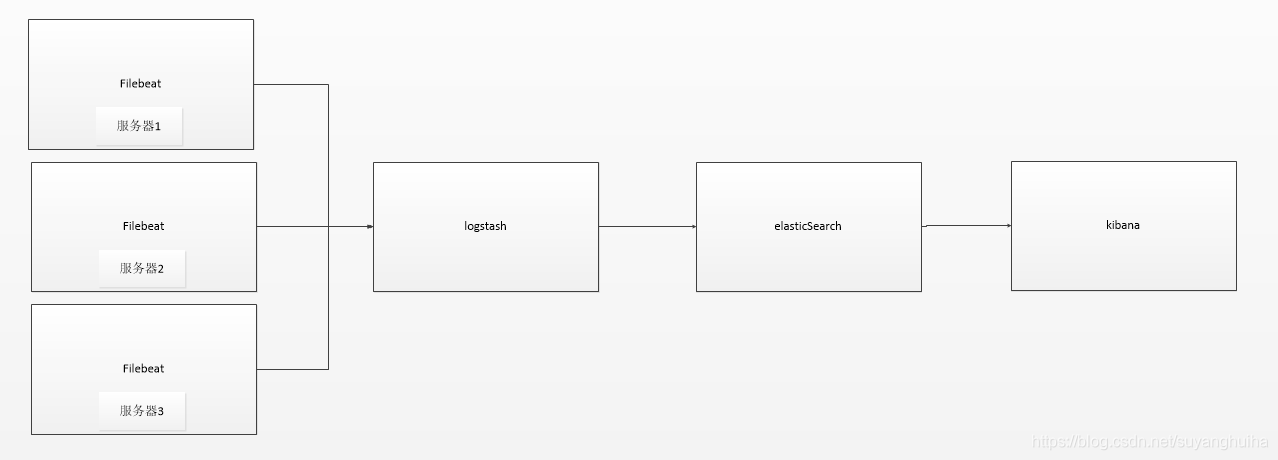
2.以beats作为日志文件的收集器。这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
常见的beat有:
Packetbeat(搜集网络流量数据);
Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
Filebeat(搜集文件数据)-------最常用。
4.4安装kibana
1.解压jar包

2.修改/config/kibana.yml文件
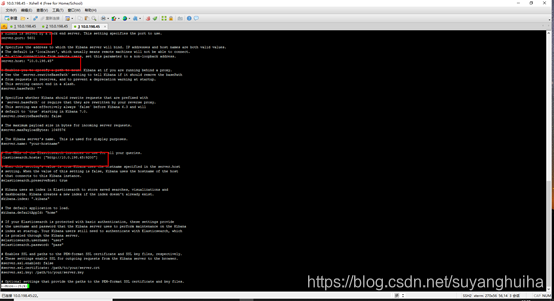
3.启动服务

4.启动成功
5.微服务和elk的结合使用
以上elk服务搭建完成了,如何将springcloud生产的日志写入logstash中。
1.修改pom.xml,引入对应的maven jar包
net.logstash.logback
logstash-logback-encoder
5.3
2.修改logback.xml
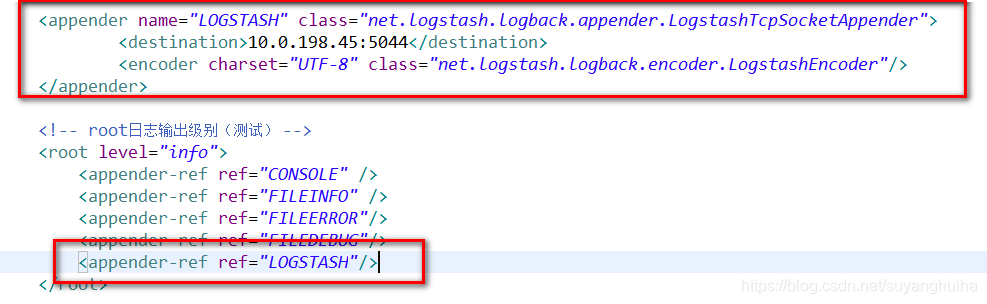
启动服务
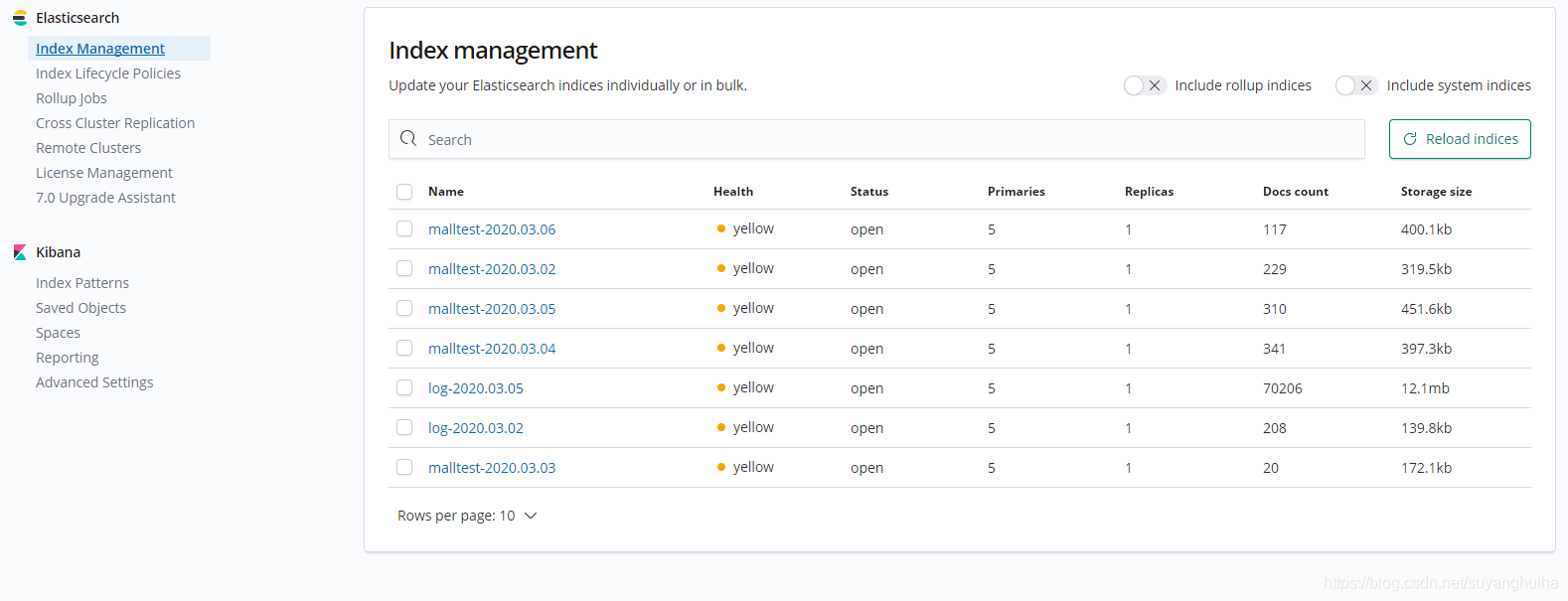
1.在kibana中可以查看es的索引文件
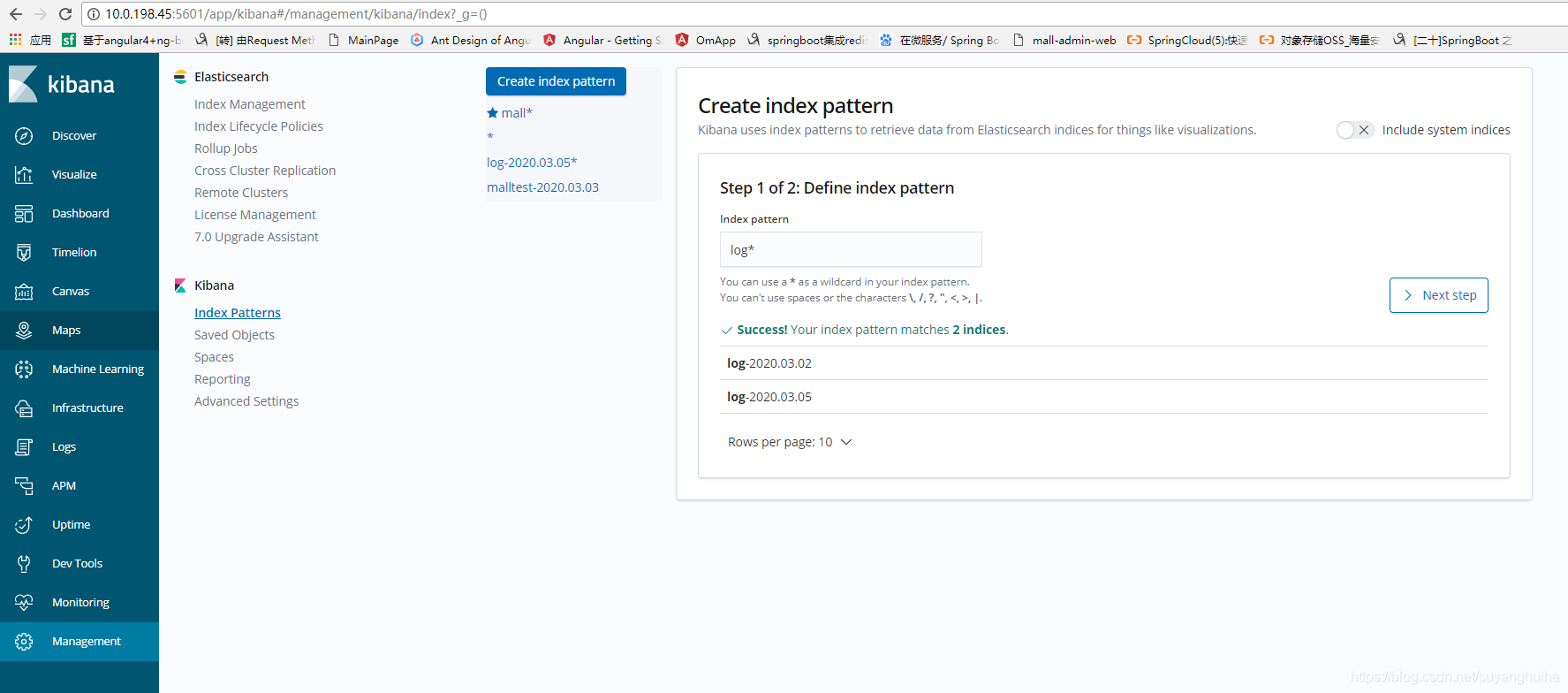
2.配置kibana可查询es索引文件(配置* 就是所有文件)
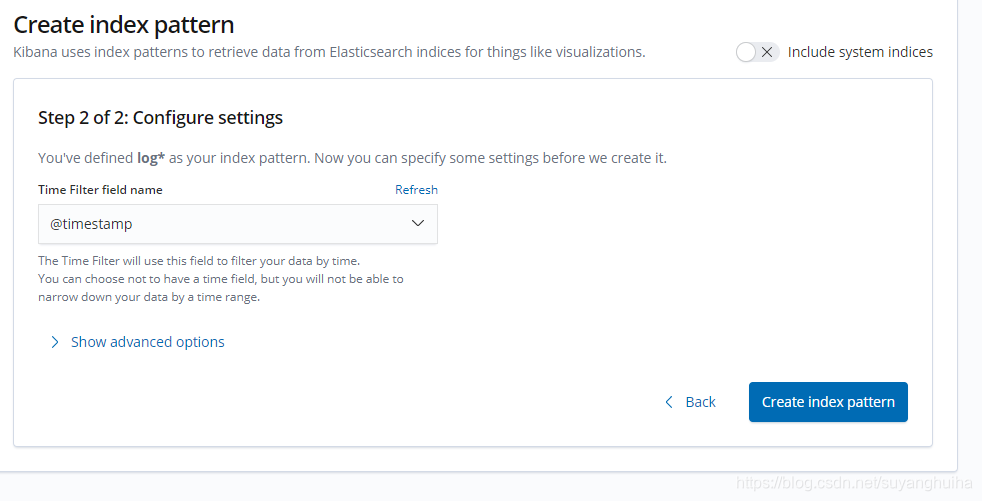
3.索引文件中的数据按时间排序
4.查询日志
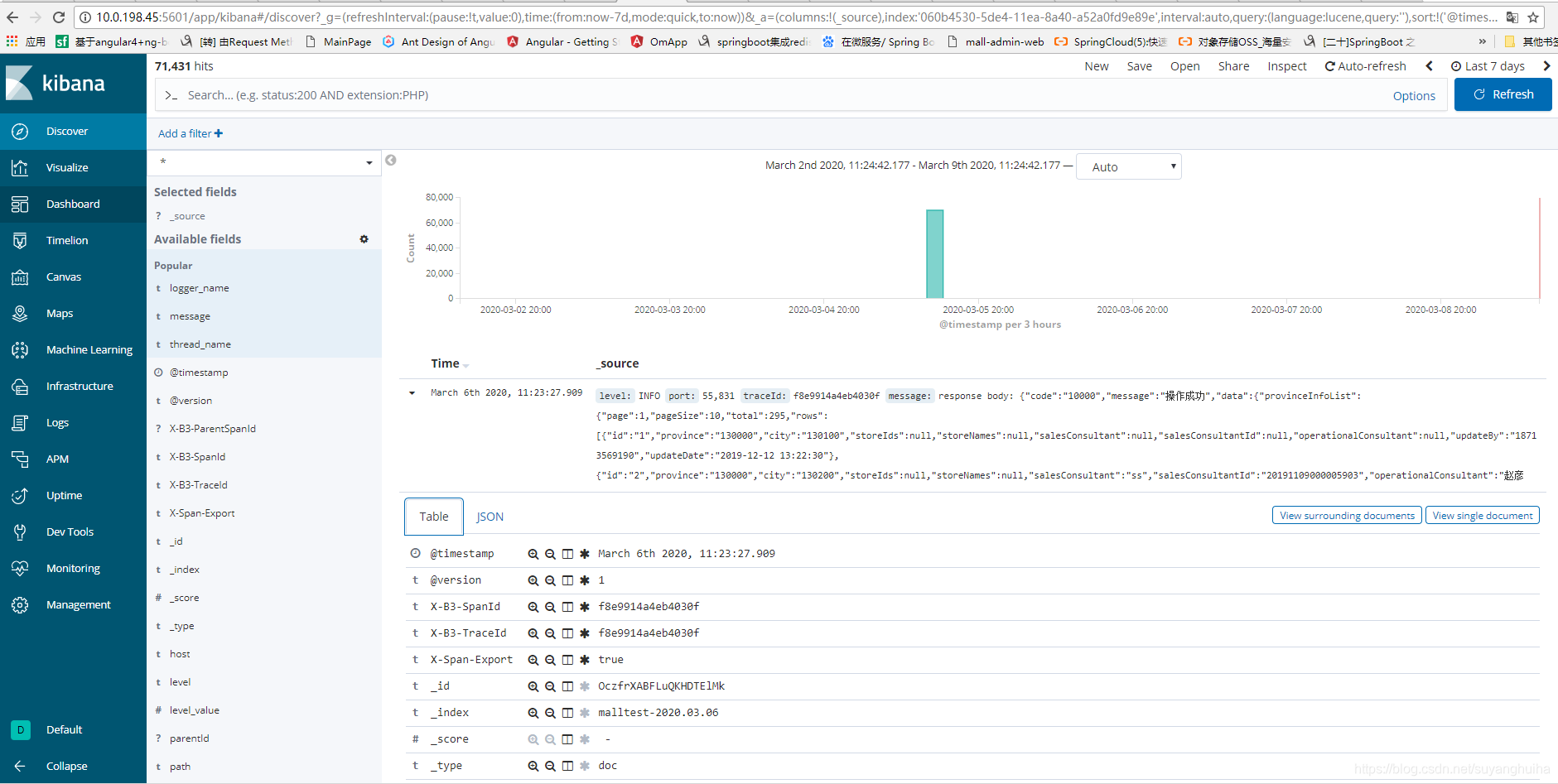
6.sleuth和elk的结合使用
微服务存在着多服务的调用,如何将多个微服务的日志通过一个traceId将服务的日志穿到一起,做到服务日志和跟踪。我们采用了springcloud的另外一个组件spring-cloud-sleuth。
1.搭建zipkin-serer 服务(如果不需要实时查看服务的调用信息,这个可以不搭建的)
引入pom.xml引入jar

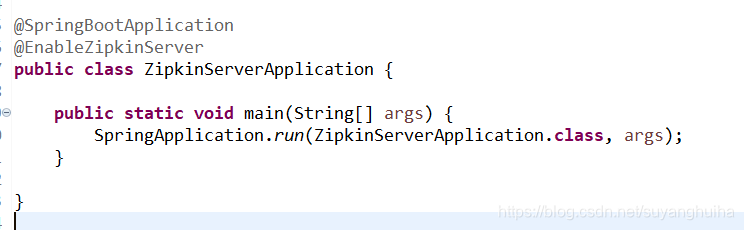
修改启动类
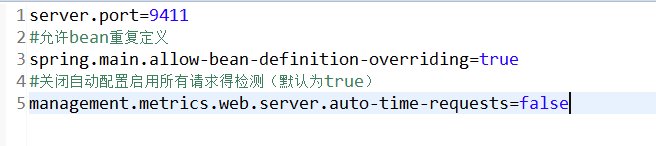
修改application.properties
2.微服务中引入sleuth
修改原微服务中的pom.xml文件

修改原微服务的application.properties文件

为什么要配置抽样收集呢?
理论上应该是收集的跟踪信息越多越好,可以更好的反映出系统的实际运行情况,但是在高并发的分布式系统运行时,大量请求调用会产生海量的跟踪日志信息,如果过多的收集,会对系统性能造成一定的影响,所以 Spring Cloud Sleuth 采用了抽样收集的方式。
启动程序,访问微服务进行服务链路跟踪。(http://localhost:9411/zipkin)
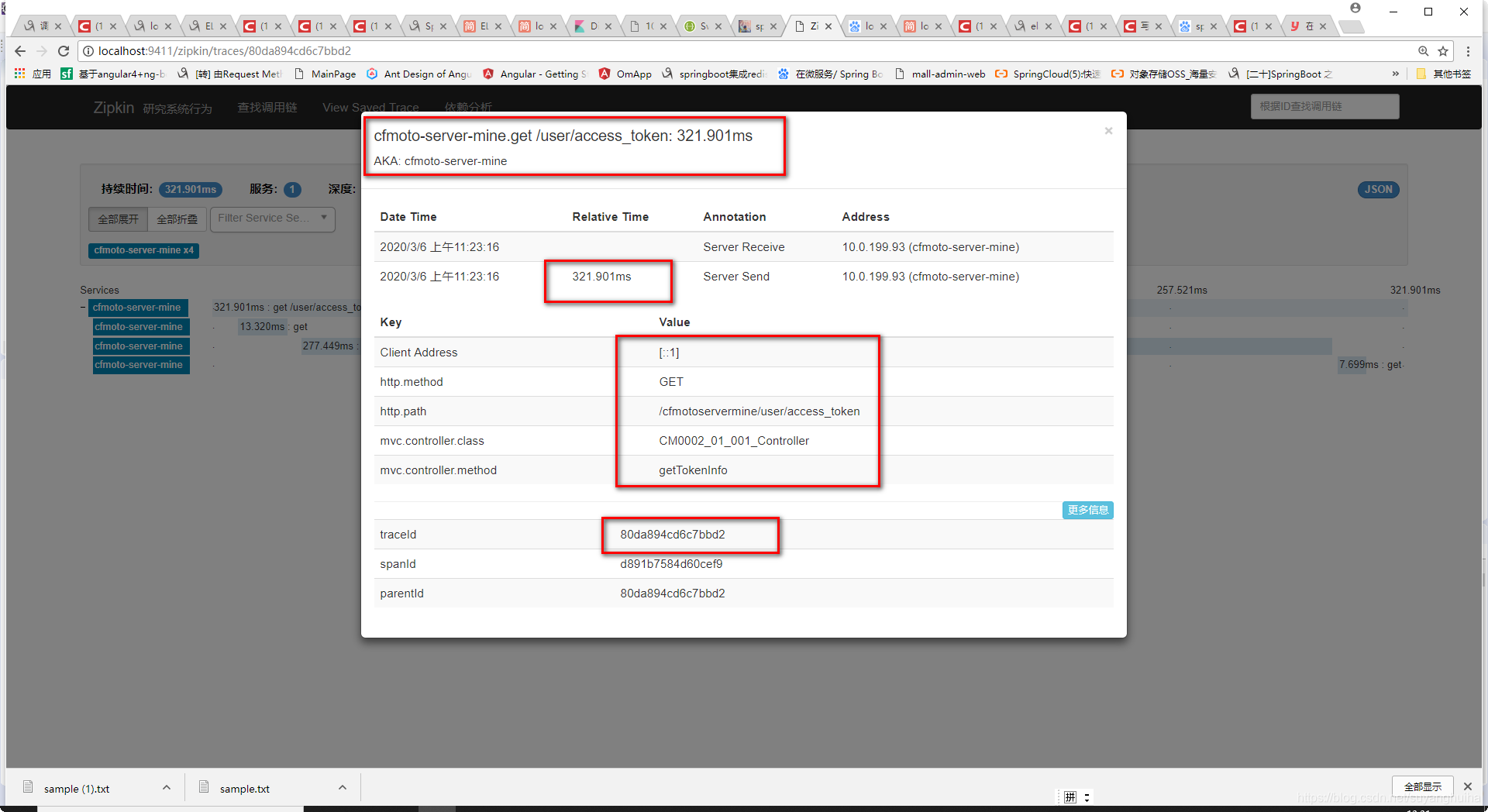
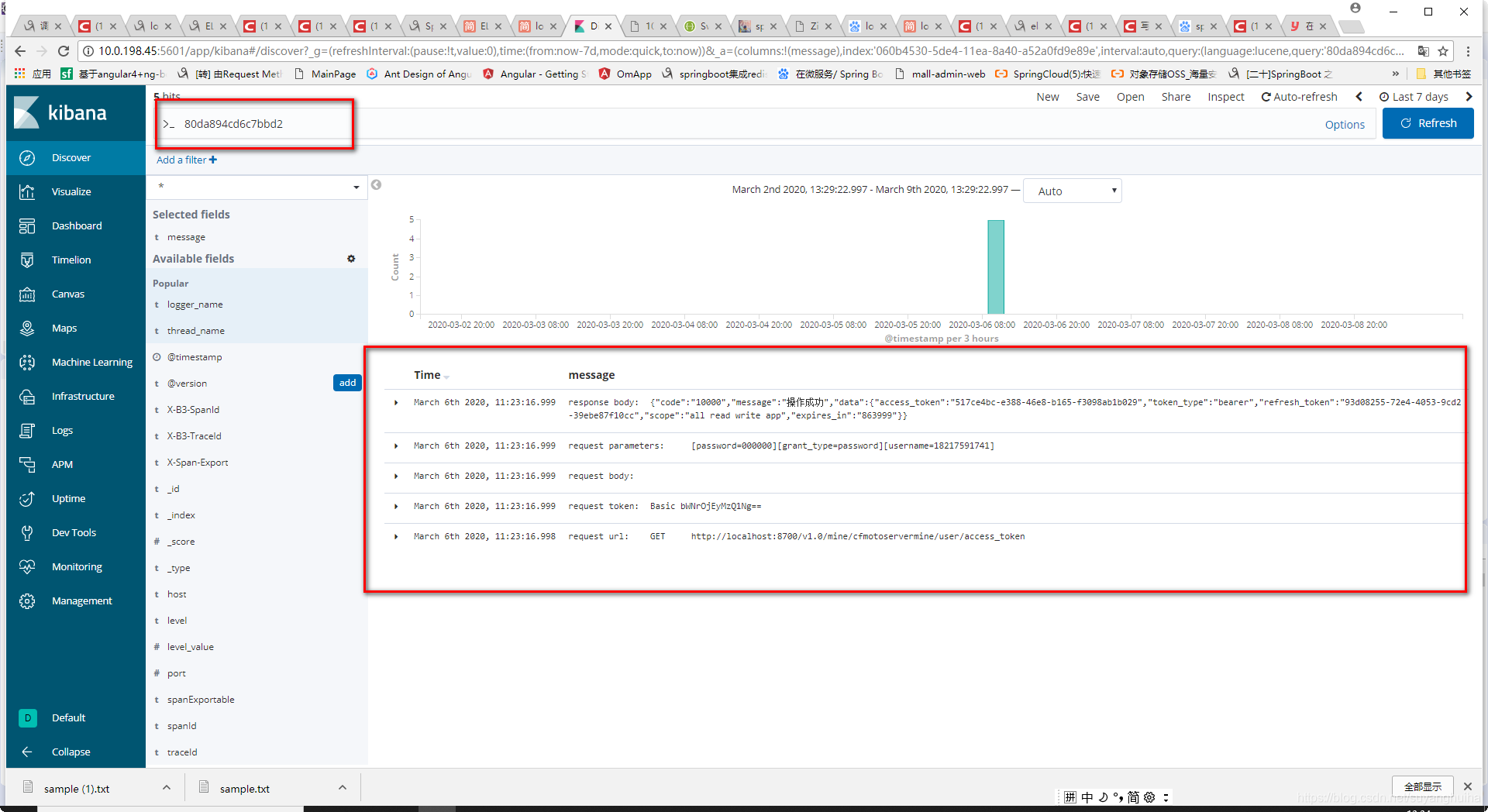
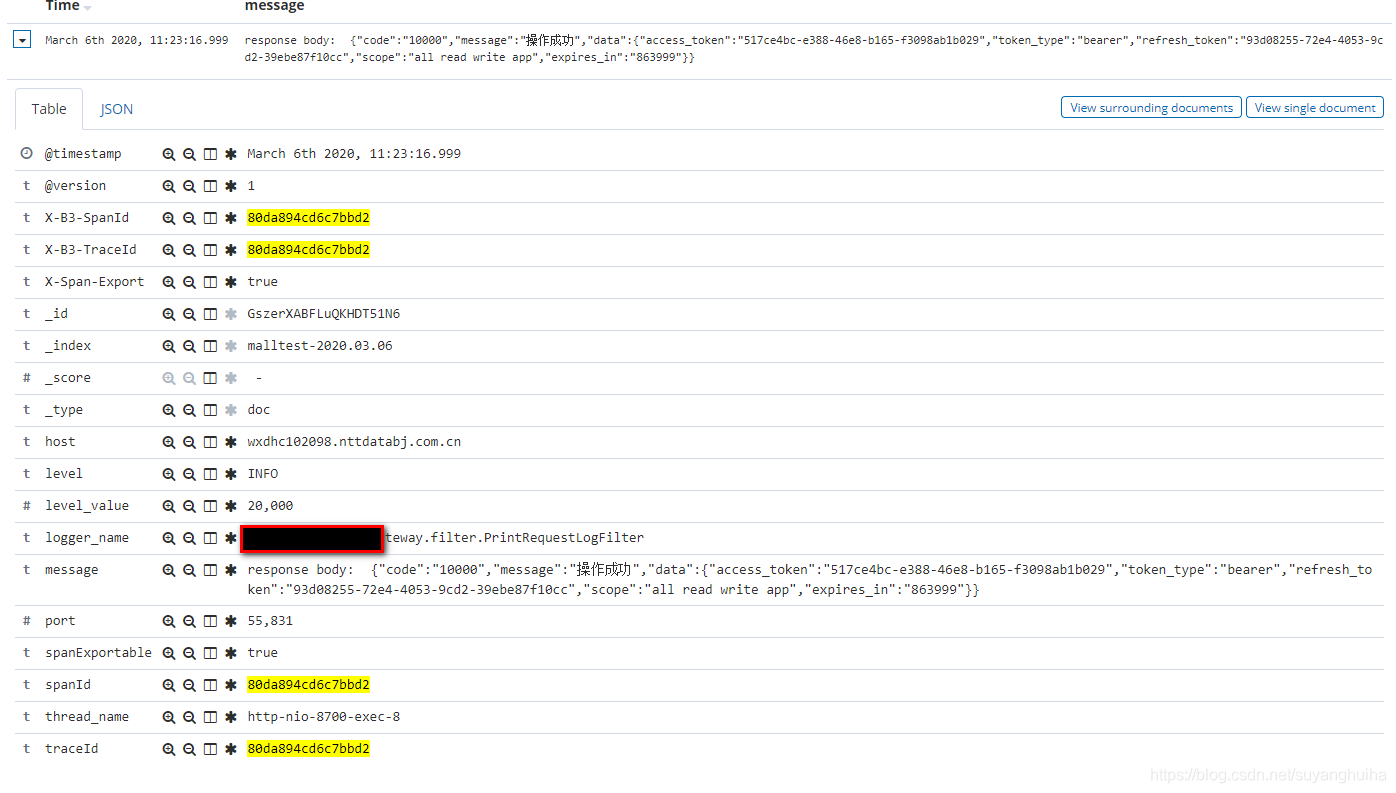
根据tranceid在kibana中查看数据














 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









